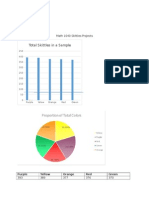
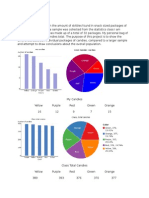
Вам также может понравиться
- SPSS Tutorial: A Detailed ExplanationДокумент193 страницыSPSS Tutorial: A Detailed ExplanationFaizan Ahmad100% (10)
- Engineering Data AnalysisДокумент3 страницыEngineering Data AnalysisJesse JavierОценок пока нет
- Agusan National High School Summative Test in Statistics and ProbabilityДокумент7 страницAgusan National High School Summative Test in Statistics and Probabilityneil ponoyОценок пока нет
- Multiplication and Division for Fourth GradersОт EverandMultiplication and Division for Fourth GradersРейтинг: 5 из 5 звезд5/5 (1)
- Statistical Theory and Methodology in Science and EngineeringДокумент607 страницStatistical Theory and Methodology in Science and EngineeringNelson IsraelОценок пока нет
- ARDL Eviews9 David GilesДокумент35 страницARDL Eviews9 David GilesYasar Yasarlar100% (1)
- Math 1040 Skittles Term ProjectДокумент9 страницMath 1040 Skittles Term Projectapi-319881085Оценок пока нет
- Skittles Project 1Документ7 страницSkittles Project 1api-299868669100% (2)
- Skittles Project FinalДокумент5 страницSkittles Project Finalapi-271348941Оценок пока нет
- TP 2 StatsДокумент5 страницTP 2 Statsapi-240850453Оценок пока нет
- Final Math ProjectДокумент7 страницFinal Math Projectapi-316775963Оценок пока нет
- Math 1040 Term ProjectДокумент7 страницMath 1040 Term Projectapi-340188424Оценок пока нет
- Skittles ProДокумент9 страницSkittles Proapi-241124972Оценок пока нет
- The Rainbow ReportДокумент11 страницThe Rainbow Reportapi-316991888Оценок пока нет
- Skittles Term Project 11 9 14Документ5 страницSkittles Term Project 11 9 14api-192489685Оценок пока нет
- Skittles Project With ReflectionДокумент7 страницSkittles Project With Reflectionapi-234712126100% (1)
- Kassem Hajj: Math 1040 Skittles Term ProjectДокумент10 страницKassem Hajj: Math 1040 Skittles Term Projectapi-240347922Оценок пока нет
- Final Stats ProjectДокумент8 страницFinal Stats Projectapi-238717717100% (2)
- Skittles Term Project StatsДокумент8 страницSkittles Term Project Statsapi-302549779Оценок пока нет
- Term Project ReportДокумент9 страницTerm Project Reportapi-238585685Оценок пока нет
- SkittlesdataclassprojectДокумент8 страницSkittlesdataclassprojectapi-399586872Оценок пока нет
- Skittles ProjectДокумент9 страницSkittles Projectapi-242873849Оценок пока нет
- Math 1030 Skittles Term ProjectДокумент8 страницMath 1030 Skittles Term Projectapi-340538273Оценок пока нет
- Math Project Part B With ConclusionДокумент5 страницMath Project Part B With Conclusionapi-273321131Оценок пока нет
- Math 1040 Statistics Term Project: Blake FreemanДокумент10 страницMath 1040 Statistics Term Project: Blake Freemanapi-252919218Оценок пока нет
- Skittles FinalДокумент12 страницSkittles Finalapi-241861434Оценок пока нет
- Skittles ProjectДокумент6 страницSkittles Projectapi-319345408Оценок пока нет
- Skittle Pareto ChartДокумент7 страницSkittle Pareto Chartapi-272391081Оценок пока нет
- Dulces Math 1040Документ6 страницDulces Math 1040api-242193187Оценок пока нет
- Term Project - EportfolioДокумент7 страницTerm Project - Eportfolioapi-251981709Оценок пока нет
- Math 1040 Final ProjectДокумент3 страницыMath 1040 Final Projectapi-285380759Оценок пока нет
- Skittles Project 2Документ10 страницSkittles Project 2api-316655135Оценок пока нет
- Stats ProjectДокумент14 страницStats Projectapi-302666758Оценок пока нет
- Term Project Part 7Документ8 страницTerm Project Part 7api-291870758Оценок пока нет
- StatsfinalprojectДокумент7 страницStatsfinalprojectapi-325102852Оценок пока нет
- Emily Gregorio Skittles Project FinalДокумент3 страницыEmily Gregorio Skittles Project Finalapi-288933258Оценок пока нет
- Final ProjectДокумент3 страницыFinal Projectapi-265661554Оценок пока нет
- Skittles Group E-PortfolioДокумент9 страницSkittles Group E-Portfolioapi-253834649Оценок пока нет
- The Skittles Project FinalДокумент8 страницThe Skittles Project Finalapi-316760667Оценок пока нет
- Full Skittles ProjectДокумент13 страницFull Skittles Projectapi-537189505Оценок пока нет
- Statistics Project 17Документ13 страницStatistics Project 17api-271978152Оценок пока нет
- Math Skittles Term Project-1Документ6 страницMath Skittles Term Project-1api-241771020Оценок пока нет
- Skittles Project Math 1030Документ9 страницSkittles Project Math 1030api-305867098Оценок пока нет
- Final ProjectДокумент9 страницFinal Projectapi-262329757Оценок пока нет
- Skittles ReportДокумент15 страницSkittles Reportapi-271901299Оценок пока нет
- Math 1040 Skittles Final ProjectДокумент5 страницMath 1040 Skittles Final Projectapi-253961355Оценок пока нет
- Skittles 2 FinalДокумент12 страницSkittles 2 Finalapi-242194552Оценок пока нет
- Skittles ProjectДокумент4 страницыSkittles Projectapi-287735026Оценок пока нет
- EportfolioДокумент8 страницEportfolioapi-242211470Оценок пока нет
- Math 1040 Skittles Term Project EportfolioДокумент7 страницMath 1040 Skittles Term Project Eportfolioapi-260817278Оценок пока нет
- Math 1040 Skittles Term Project AynoaДокумент15 страницMath 1040 Skittles Term Project Aynoaapi-301347675Оценок пока нет
- Final ProjectДокумент6 страницFinal Projectapi-283261340Оценок пока нет
- Statistics Term Project E-Portfolio ReflectionДокумент8 страницStatistics Term Project E-Portfolio Reflectionapi-258147701Оценок пока нет
- Skittles Statistics ProjectДокумент9 страницSkittles Statistics Projectapi-325825295Оценок пока нет
- Term Project SkittlesДокумент4 страницыTerm Project Skittlesapi-356003029Оценок пока нет
- Skittles Project Group Final WordДокумент6 страницSkittles Project Group Final Wordapi-316239273Оценок пока нет
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Документ8 страницTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832Оценок пока нет
- 1040 Skittles ProjectДокумент3 страницы1040 Skittles Projectapi-302929225Оценок пока нет
- Comprehensive Skittles Project Math 1040Документ7 страницComprehensive Skittles Project Math 1040api-316732019Оценок пока нет
- Math 1040 ProjectДокумент8 страницMath 1040 Projectapi-388517702Оценок пока нет
- Term Project: Part 2 - IndividualДокумент13 страницTerm Project: Part 2 - Individualapi-289345421Оценок пока нет
- Skittles Final Project Statistics 1040Документ7 страницSkittles Final Project Statistics 1040api-297109325Оценок пока нет
- Stats StuffДокумент7 страницStats Stuffapi-242298926Оценок пока нет
- Skittles Project Math 1040Документ8 страницSkittles Project Math 1040api-495044194Оценок пока нет
- General Hos LemДокумент9 страницGeneral Hos LemSeyChell NorinhaОценок пока нет
- Mach Learning QsДокумент7 страницMach Learning Qsjohn kayОценок пока нет
- About Kriging: Consultants For Mining and Financial SolutionsДокумент4 страницыAbout Kriging: Consultants For Mining and Financial SolutionsLUIS GUALBERTO VALDIVIESO� GUERRAОценок пока нет
- ch10ppln Product PlanningДокумент19 страницch10ppln Product PlanningJoshAbrahamОценок пока нет
- Data Validity and Reliability AnalysisДокумент8 страницData Validity and Reliability AnalysisLiana LimbongОценок пока нет
- ISE 4553 HW #4Документ8 страницISE 4553 HW #4Justin ZweigОценок пока нет
- Gold Price Forecast W Box-JenkinsДокумент13 страницGold Price Forecast W Box-JenkinsVinОценок пока нет
- Lec5 Part1Документ42 страницыLec5 Part1fhjhgjhОценок пока нет
- Pengaruh Teknik Budidaya Terhadap Produksi Kopi (Coffea Spp. L.) MASYARAKAT KAROДокумент16 страницPengaruh Teknik Budidaya Terhadap Produksi Kopi (Coffea Spp. L.) MASYARAKAT KARORuth ElferawiОценок пока нет
- Percentile Is A Value in A Data Set That Splits The Data Into Two Pieces: The Lower PieceДокумент3 страницыPercentile Is A Value in A Data Set That Splits The Data Into Two Pieces: The Lower PieceBitan BanerjeeОценок пока нет
- Maco - Let's Check ULO C - UwuДокумент2 страницыMaco - Let's Check ULO C - UwuJessie MacoОценок пока нет
- QBM 101 Lecture 10Документ45 страницQBM 101 Lecture 10Shu HeeОценок пока нет
- Machine Learning Practice Problems ExplainedДокумент14 страницMachine Learning Practice Problems ExplainedbrsbyrmОценок пока нет
- Indikator KemiskinanДокумент17 страницIndikator KemiskinanAldhy ThoОценок пока нет
- Unit 3 Lab Assignment: Descriptive Statistics and Box PlotsДокумент4 страницыUnit 3 Lab Assignment: Descriptive Statistics and Box PlotsJaveria MalickОценок пока нет
- Assignment Z TestДокумент2 страницыAssignment Z TestHãñzlà Tåriq0% (1)
- Salary, Years Since PH.D., and Number of Publications Example From Cohen, Cohen. West, & Aiken, Table 3.2.1Документ8 страницSalary, Years Since PH.D., and Number of Publications Example From Cohen, Cohen. West, & Aiken, Table 3.2.1Sheriad MajieОценок пока нет
- Frequency Histogram Analysis of Data DistributionДокумент12 страницFrequency Histogram Analysis of Data DistributionANIL PALОценок пока нет
- Project 2: Technical University of DenmarkДокумент11 страницProject 2: Technical University of DenmarkRiyaz AlamОценок пока нет
- Take Home Test MEI 2014Документ3 страницыTake Home Test MEI 2014மோகனா KarunakaranОценок пока нет
- Statpro Lesson 3RD WeekДокумент23 страницыStatpro Lesson 3RD WeekDelaRosa AltheaОценок пока нет
- Module 4 (Data Management) - Math 101Документ8 страницModule 4 (Data Management) - Math 101Flory CabaseОценок пока нет
- Good Estimation Detection NotesДокумент11 страницGood Estimation Detection NotesTalha NadeemОценок пока нет
- r5210501 Probability and StatisticsДокумент1 страницаr5210501 Probability and StatisticssivabharathamurthyОценок пока нет