Вам также может понравиться
- Manual Data Stage PDFДокумент27 страницManual Data Stage PDF0011010100150% (4)
- Actividades Tema 2Документ3 страницыActividades Tema 2jorgex00% (4)
- Examen Final TeóricoДокумент9 страницExamen Final Teóricoeamseams100% (1)
- DataStage AvanzadoДокумент3 страницыDataStage AvanzadoAndres Gonzalez0% (2)
- Comandos en OracleДокумент6 страницComandos en OracleMiguel ParraОценок пока нет
- DataStage Guía de Conectividad para Aplicaciones IBM WebSphere MQ PDFДокумент217 страницDataStage Guía de Conectividad para Aplicaciones IBM WebSphere MQ PDFItalo HeviaОценок пока нет
- Curso Data StageДокумент144 страницыCurso Data StageIsabel PoloОценок пока нет
- Procedimientos, Funciones y TiggerДокумент56 страницProcedimientos, Funciones y TiggerDAML GGОценок пока нет
- C CharpДокумент4 страницыC CharpRene LunaОценок пока нет
- 3 Ejemplos Desarrollados Normalizacion - Semana4Документ26 страниц3 Ejemplos Desarrollados Normalizacion - Semana4Giovany Lipe Caso100% (1)
- Respuestas Oracle PL-SQL Practica 9Документ4 страницыRespuestas Oracle PL-SQL Practica 9Ezequiel Hernán VillanuevaОценок пока нет
- SQL Principiantes Paso A PasoДокумент20 страницSQL Principiantes Paso A PasoCuadra ValenteОценок пока нет
- Cuestionario OracleДокумент4 страницыCuestionario OracleWilly Campos Lozada100% (1)
- EQV - Taller DataStageДокумент75 страницEQV - Taller DataStageAndres GonzalezОценок пока нет
- Datastage WorkshopДокумент43 страницыDatastage Workshopleniadz250% (2)
- IBM InfoSphereДокумент203 страницыIBM InfoSpherejlopez_303Оценок пока нет
- 2013-11-13 12.23 Capacitacion Datastage - 1era ParteДокумент31 страница2013-11-13 12.23 Capacitacion Datastage - 1era ParteJhonnatan Cahuapas BallartaОценок пока нет
- Data StageДокумент10 страницData StageJhonatan AmezquitaОценок пока нет
- C 1135663Документ64 страницыC 1135663nickhitОценок пока нет
- Curso de Datastage 17102015Документ7 страницCurso de Datastage 17102015leniadz2Оценок пока нет
- Cuestionario TriggerДокумент2 страницыCuestionario TriggerEdsonOrellanaОценок пока нет
- Ejemplo SQL TUNING ADVISORДокумент4 страницыEjemplo SQL TUNING ADVISORkamuniasОценок пока нет
- TALLER N 06 Programacion en Transact SQLДокумент31 страницаTALLER N 06 Programacion en Transact SQLAnonymous Ss4Gb9a1Оценок пока нет
- SQL Server Integration ServicesДокумент42 страницыSQL Server Integration ServicesWilly Campos LozadaОценок пока нет
- Crear Un Procedimiento en MySQLДокумент17 страницCrear Un Procedimiento en MySQLAnonymous GFmbr7Оценок пока нет
- Control de ConcurrenciaДокумент32 страницыControl de Concurrenciajuliocromani04100% (8)
- Soluciones Ejercicios PL/SQLДокумент59 страницSoluciones Ejercicios PL/SQLmigarmi58% (12)
- Examen Final DBA1 Oracle 10g 2011Документ17 страницExamen Final DBA1 Oracle 10g 2011aquey50% (2)
- Manual de Oracle Y PL SQLДокумент61 страницаManual de Oracle Y PL SQLtolicapo100% (11)
- Comandos MysqlДокумент45 страницComandos MysqlAshley Stronghold WitwickyОценок пока нет
- Respuestas Oracle PL-SQL Practica 21Документ5 страницRespuestas Oracle PL-SQL Practica 21Ezequiel Hernán VillanuevaОценок пока нет
- Trucos SQL ServerДокумент46 страницTrucos SQL ServerJavier Vicente GallegoОценок пока нет
- Capítulo 5 - Mantenimiento Del Redo LogДокумент38 страницCapítulo 5 - Mantenimiento Del Redo LogFrancisco GuiñazúОценок пока нет
- Examen Parcial - Semana - BASES de DATOS 1Документ11 страницExamen Parcial - Semana - BASES de DATOS 1John Itzen100% (1)
- Procedimientos AlmacenadosДокумент8 страницProcedimientos AlmacenadosErika Tatiana GUTIERREZ CANO100% (2)
- Procedimientos Almacenados y Triggers en SQL ServerДокумент8 страницProcedimientos Almacenados y Triggers en SQL Serverwireless2007100% (37)
- Manual-Libro Sobre SSIS PDFДокумент8 страницManual-Libro Sobre SSIS PDFGustavo A. CondeОценок пока нет
- SQL Server - Procedimientos AlmacenadosДокумент75 страницSQL Server - Procedimientos Almacenadoscarmelo_esОценок пока нет
- Crud LaravelДокумент12 страницCrud LaravelAndre AyalaОценок пока нет
- Consultas DistribuidasДокумент8 страницConsultas DistribuidasDna bubbleОценок пока нет
- 1-Consultas Avanzadas Con T-SQLДокумент37 страниц1-Consultas Avanzadas Con T-SQLDavid CobeñasОценок пока нет
- Oracle PSQL-Desarrollando TriggersДокумент13 страницOracle PSQL-Desarrollando TriggersJimmy AlvaradoОценок пока нет
- Guia-6 Proyectos ETLДокумент21 страницаGuia-6 Proyectos ETLsaul1905Оценок пока нет
- 12 Subconsultas Avanzadas V 3Документ45 страниц12 Subconsultas Avanzadas V 3sistemasuancvОценок пока нет
- Ejemplo de Reporting ServicesДокумент6 страницEjemplo de Reporting ServicesYadira Carmen Garcia BravoОценок пока нет
- Tutorial JSPДокумент131 страницаTutorial JSPEst DleoОценок пока нет
- File Server o Servidor de ArchivosДокумент32 страницыFile Server o Servidor de ArchivosBryan barrios carlierОценок пока нет
- Material InfosPhere DataStageДокумент40 страницMaterial InfosPhere DataStageIsabel PoloОценок пока нет
- Creación de QueryДокумент18 страницCreación de QuerydavpezОценок пока нет
- Actividad1 Tema 5Документ14 страницActividad1 Tema 5laloОценок пока нет
- Dokumen - Tips - Framework para VFP Conexion Con Sqlserver Mysql Postgresql y Oracle IIIДокумент16 страницDokumen - Tips - Framework para VFP Conexion Con Sqlserver Mysql Postgresql y Oracle IIICesarОценок пока нет
- Conectividad de SAP-VbasicДокумент17 страницConectividad de SAP-Vbasicmartin_josepОценок пока нет
- Práctica Guiada 0 StataДокумент7 страницPráctica Guiada 0 StataMateoQuiguiríОценок пока нет
- TutorialДокумент23 страницыTutorialVicent de la CruzОценок пока нет
- 005.13 I51 EjerciciosДокумент70 страниц005.13 I51 EjerciciosOcas Ocas CОценок пока нет
- Cómo Usar Text FieldДокумент11 страницCómo Usar Text FieldDante AvilésОценок пока нет
- Capitulo3 Buscar Datos en Varios TablasДокумент29 страницCapitulo3 Buscar Datos en Varios TablasAbraham Perez PalmaОценок пока нет
- Framework para VFP Conexion Con SQLServer MySQL PostgreSQL y Oracle IIIДокумент16 страницFramework para VFP Conexion Con SQLServer MySQL PostgreSQL y Oracle IIIGerbert Antonio Huiza Lopez100% (2)
- UntitledДокумент16 страницUntitledSol PaezОценок пока нет
- Manual Excel Avanzado 2Документ8 страницManual Excel Avanzado 2Eduardo F N JОценок пока нет
- Tecnicas MetodologicasДокумент2 страницыTecnicas MetodologicasIleana GuerreroОценок пока нет
- Las Técnicas Metodológicas SonДокумент3 страницыLas Técnicas Metodológicas SonIleana GuerreroОценок пока нет
- Reseña Historica de Los Medios de Comunicación en Venezuela Apartir Del Siglo XXДокумент3 страницыReseña Historica de Los Medios de Comunicación en Venezuela Apartir Del Siglo XXIleana GuerreroОценок пока нет
- El Sistema MétricoДокумент17 страницEl Sistema MétricoIleana GuerreroОценок пока нет
- Al Azif - Necronomicon PDFДокумент95 страницAl Azif - Necronomicon PDFIleana GuerreroОценок пока нет
- Características de La Capitanía General de VenezuelaДокумент4 страницыCaracterísticas de La Capitanía General de VenezuelaIleana GuerreroОценок пока нет
- Al Azif - Necronomicon PDFДокумент95 страницAl Azif - Necronomicon PDFIleana GuerreroОценок пока нет
- Manual de Microcontroladores PICДокумент68 страницManual de Microcontroladores PICabraham-tellez-5555Оценок пока нет
- Telefonía CelularДокумент51 страницаTelefonía CelularCesar Huamani100% (4)
- Microsoft Word 2010 ResumДокумент32 страницыMicrosoft Word 2010 ResumClaudia CruzОценок пока нет
- 9 - 10 OfimaticaДокумент16 страниц9 - 10 OfimaticaJhosselyn Lucas MaciasОценок пока нет
- Quartus Tutorial001Документ25 страницQuartus Tutorial001Alfredo Martin Machacuay SiuceОценок пока нет
- CorelDRAW Graphics Suite X8Документ12 страницCorelDRAW Graphics Suite X8Marco Cusi CОценок пока нет
- Sem 283Документ84 страницыSem 283Cesar EspinozaОценок пока нет
- Manual Evernote para AndroidДокумент13 страницManual Evernote para AndroidJosUé Alberto ZavalaОценок пока нет
- DosemuДокумент12 страницDosemuGabo CienОценок пока нет
- Curso de AutocadДокумент55 страницCurso de Autocadwilliamarm2009Оценок пока нет
- Pasos para Instalar Karaoke 3900Документ10 страницPasos para Instalar Karaoke 3900Francisco OsorioОценок пока нет
- Archivos Matriciales Con Dms GoДокумент6 страницArchivos Matriciales Con Dms Goauxiliar calidadОценок пока нет
- Configurar VNC en ItalcДокумент35 страницConfigurar VNC en Italcnr352Оценок пока нет
- Word PDFДокумент23 страницыWord PDFCarlos Alberto Sosa TОценок пока нет
- Curso Logo! 8 - Módulo 5 - OkДокумент16 страницCurso Logo! 8 - Módulo 5 - OkFernando Gustavo LorenzoОценок пока нет
- Manual SispreДокумент413 страницManual SisprecaperucitarojavОценок пока нет
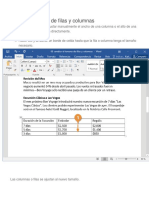
- Modificar Tamaño de Filas y ColumnasДокумент3 страницыModificar Tamaño de Filas y ColumnasYONY ANNELY ESPIRILLA RAMOSОценок пока нет
- Manual PanasonicДокумент77 страницManual PanasonicNataly QuintanaОценок пока нет
- Vensim 8Документ19 страницVensim 8Miguel Arzapalo VillonОценок пока нет
- Poryecto BiometricoДокумент16 страницPoryecto BiometricoFrancisko T'BzОценок пока нет
- Manual Word Basico 2010Документ26 страницManual Word Basico 2010glezmontero_susanaОценок пока нет
- Manual de Usuario TpvSOL 2011Документ28 страницManual de Usuario TpvSOL 2011Jorge FloresОценок пока нет
- Tarea de La Unidad - Valor 5 PuntosДокумент3 страницыTarea de La Unidad - Valor 5 PuntosAbraham González SánchezОценок пока нет
- Guia Archicad Corte 1Документ44 страницыGuia Archicad Corte 1Wilmar farid salcedo toroОценок пока нет
- Ua3 RevitДокумент47 страницUa3 RevitMarte MarteОценок пока нет
- Ayuda en Google ChromeДокумент27 страницAyuda en Google ChromegabrielОценок пока нет
- Fotomontaje Complejo - Hombre Con Su SombraДокумент23 страницыFotomontaje Complejo - Hombre Con Su SombraVictor Pingo MedinaОценок пока нет
- Asm 51Документ76 страницAsm 51yakovagoОценок пока нет
- Unidad 4 - Tarjetas de Presentacion y Postales PDFДокумент9 страницUnidad 4 - Tarjetas de Presentacion y Postales PDFErika Avila LeivaОценок пока нет
- Manual KnitDrawДокумент52 страницыManual KnitDrawJuan perezОценок пока нет
- Manual EmcoДокумент190 страницManual Emcoosiris_rammsesОценок пока нет