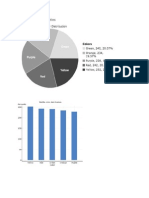
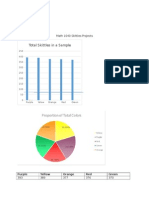
Вам также может понравиться
- Skittles Project With ReflectionДокумент7 страницSkittles Project With Reflectionapi-234712126100% (1)
- SkittlesdataclassprojectДокумент8 страницSkittlesdataclassprojectapi-399586872Оценок пока нет
- Full Skittles ProjectДокумент13 страницFull Skittles Projectapi-537189505Оценок пока нет
- Comprehensive Skittles Project Math 1040Документ7 страницComprehensive Skittles Project Math 1040api-316732019Оценок пока нет
- Math 1040 Skittles Term ProjectДокумент9 страницMath 1040 Skittles Term Projectapi-319881085Оценок пока нет
- The Skittles Project FinalДокумент8 страницThe Skittles Project Finalapi-316760667Оценок пока нет
- Skittles Project FinalДокумент5 страницSkittles Project Finalapi-271348941Оценок пока нет
- Kassem Hajj: Math 1040 Skittles Term ProjectДокумент10 страницKassem Hajj: Math 1040 Skittles Term Projectapi-240347922Оценок пока нет
- Skittles ProjectДокумент4 страницыSkittles Projectapi-287735026Оценок пока нет
- Group Project #1 - SkittlesДокумент9 страницGroup Project #1 - Skittlesapi-245266056Оценок пока нет
- Skittles Project Stats 1040Документ8 страницSkittles Project Stats 1040api-301336765Оценок пока нет
- Statistics Final Project Summer Semester 2016Документ17 страницStatistics Final Project Summer Semester 2016api-295161880Оценок пока нет
- Statistics Project 17Документ13 страницStatistics Project 17api-271978152Оценок пока нет
- Skittles Project 5-02Документ8 страницSkittles Project 5-02api-354040698Оценок пока нет
- Skittles ProjectДокумент9 страницSkittles Projectapi-252747849Оценок пока нет
- Skittles Term ProjectДокумент10 страницSkittles Term Projectapi-273060240Оценок пока нет
- Math 1040 Statistics Term Project: Blake FreemanДокумент10 страницMath 1040 Statistics Term Project: Blake Freemanapi-252919218Оценок пока нет
- Reflection and EportfolioДокумент8 страницReflection and Eportfolioapi-252747849Оценок пока нет
- Math 1040 Skittles Term ProjectДокумент10 страницMath 1040 Skittles Term Projectapi-310671451Оценок пока нет
- Skittles Term Project - Kai Galbiso Stat1040Документ6 страницSkittles Term Project - Kai Galbiso Stat1040api-316758771Оценок пока нет
- Skittles ProДокумент9 страницSkittles Proapi-241124972Оценок пока нет
- Emily Gregorio Skittles Project FinalДокумент3 страницыEmily Gregorio Skittles Project Finalapi-288933258Оценок пока нет
- The Rainbow ReportДокумент11 страницThe Rainbow Reportapi-316991888Оценок пока нет
- Skittlepart3 CorrectionДокумент2 страницыSkittlepart3 Correctionapi-313630053Оценок пока нет
- Skittle Project FinalДокумент6 страницSkittle Project Finalapi-252859182Оценок пока нет
- Skittles ProjectДокумент9 страницSkittles Projectapi-242873849Оценок пока нет
- Final ProjectДокумент9 страницFinal Projectapi-262329757Оценок пока нет
- Skittles Project 1Документ7 страницSkittles Project 1api-299868669100% (2)
- Skittles ProjectДокумент6 страницSkittles Projectapi-319345408Оценок пока нет
- Skittles Term Project 1-6Документ10 страницSkittles Term Project 1-6api-284733808Оценок пока нет
- Math 1040 Final ProjectДокумент11 страницMath 1040 Final Projectapi-300784866Оценок пока нет
- Skittles Project 2Документ10 страницSkittles Project 2api-316655135Оценок пока нет
- Math 1040 Skittles Term Project EportfolioДокумент7 страницMath 1040 Skittles Term Project Eportfolioapi-260817278Оценок пока нет
- Math 1040 Skittles Term Project AynoaДокумент15 страницMath 1040 Skittles Term Project Aynoaapi-301347675Оценок пока нет
- Math 1040 Skittles Term ProjectДокумент8 страницMath 1040 Skittles Term Projectapi-272870073Оценок пока нет
- Final Math ProjectДокумент7 страницFinal Math Projectapi-316775963Оценок пока нет
- Term Project - EportfolioДокумент7 страницTerm Project - Eportfolioapi-251981709Оценок пока нет
- Final ProjectДокумент6 страницFinal Projectapi-283261340Оценок пока нет
- Study Guide Exam 2Документ34 страницыStudy Guide Exam 2kailbertОценок пока нет
- Skittles Final Project Statistics 1040Документ7 страницSkittles Final Project Statistics 1040api-297109325Оценок пока нет
- Term Project ReportДокумент9 страницTerm Project Reportapi-238585685Оценок пока нет
- TP 2 StatsДокумент5 страницTP 2 Statsapi-240850453Оценок пока нет
- Skittles Project Math 1040Документ8 страницSkittles Project Math 1040api-495044194Оценок пока нет
- EportfolioДокумент8 страницEportfolioapi-242211470Оценок пока нет
- 8614 - Assignment 2 Solved (AG)Документ19 страниц8614 - Assignment 2 Solved (AG)Maria GillaniОценок пока нет
- SkittlesДокумент7 страницSkittlesapi-244615173Оценок пока нет
- Skittles Project Part 5Документ16 страницSkittles Project Part 5api-246855746Оценок пока нет
- 6.2 Confidence IntervalsДокумент5 страниц6.2 Confidence IntervalsentropyОценок пока нет
- 8614 - Assignment 2 Solved (AG)Документ19 страниц8614 - Assignment 2 Solved (AG)Malik AlyanОценок пока нет
- Skittles Project - My Page VersionДокумент22 страницыSkittles Project - My Page Versionapi-272829351Оценок пока нет
- Math 1040 ProjectДокумент8 страницMath 1040 Projectapi-388517702Оценок пока нет
- 07 - Chapter 2 PDFДокумент28 страниц07 - Chapter 2 PDFBrhane TeklayОценок пока нет
- Sample Size Determination PDFДокумент28 страницSample Size Determination PDFVedanti Gandhi100% (1)
- Sample SizeДокумент28 страницSample SizeDelshad BotaniОценок пока нет
- Skittles Project Math 1030Документ9 страницSkittles Project Math 1030api-305867098Оценок пока нет
- Skittle Pareto ChartДокумент7 страницSkittle Pareto Chartapi-272391081Оценок пока нет
- Skittles WordДокумент5 страницSkittles Wordapi-285645725Оценок пока нет
- Machine Learning - A Complete Exploration of Highly Advanced Machine Learning Concepts, Best Practices and Techniques: 4От EverandMachine Learning - A Complete Exploration of Highly Advanced Machine Learning Concepts, Best Practices and Techniques: 4Оценок пока нет
- Practice Exercises (Chi-Square Test)Документ2 страницыPractice Exercises (Chi-Square Test)Angelica AlejandroОценок пока нет
- Determinants of Banks' Profitability in Ethiopia: The Case of CommercialДокумент18 страницDeterminants of Banks' Profitability in Ethiopia: The Case of CommercialKanbiro OrkaidoОценок пока нет
- Parametric TestДокумент40 страницParametric TestCarlos MansonОценок пока нет
- E2206 L0409 BДокумент40 страницE2206 L0409 BAlicia SunОценок пока нет
- Ejercicios Resueltos de Inferencia EstadisticaДокумент229 страницEjercicios Resueltos de Inferencia EstadisticaneoferneyОценок пока нет
- Forensic Engineering and The Scientific MethodДокумент10 страницForensic Engineering and The Scientific MethodCharles Powell100% (2)
- Spss Tutorials: Independent Samples T TestДокумент13 страницSpss Tutorials: Independent Samples T TestMat3xОценок пока нет
- Lecture9 November18&19Документ41 страницаLecture9 November18&19Devon MoodyОценок пока нет
- Artsy Case SolutionДокумент16 страницArtsy Case Solutionlenafran22100% (1)
- SPSS Workshop: Utilizing and Implementing SPSS in Our OC-Math Statistics ClassesДокумент11 страницSPSS Workshop: Utilizing and Implementing SPSS in Our OC-Math Statistics Classesgura1999Оценок пока нет
- StatsДокумент212 страницStatskutaboysОценок пока нет
- Final MBA Revised Syllabus Consolidated 18JUL14Документ72 страницыFinal MBA Revised Syllabus Consolidated 18JUL14shirishОценок пока нет
- Normality Test PDFДокумент5 страницNormality Test PDFJorge Hernan Aguado QuinteroОценок пока нет
- The Differences of KTSP and Curriculum 2013Документ11 страницThe Differences of KTSP and Curriculum 2013nurhidayahОценок пока нет
- Statistic PrintДокумент10 страницStatistic PrintNataliAmiranashviliОценок пока нет
- Answering Sheet BSC203 Supplementary/Deferred Exam S1 2020Документ12 страницAnswering Sheet BSC203 Supplementary/Deferred Exam S1 2020kimОценок пока нет
- G PowerДокумент5 страницG PowerJembia Hassan HussinОценок пока нет
- Why McDonalds Is Successful in IndiaДокумент40 страницWhy McDonalds Is Successful in Indiaashbay100% (1)
- A Study On Market Anomalies in Indian Stock Market IДокумент10 страницA Study On Market Anomalies in Indian Stock Market ISrinu BonuОценок пока нет
- Yuvraj Singh MBA HCM Prof. Smita RamakrishnaДокумент36 страницYuvraj Singh MBA HCM Prof. Smita RamakrishnaAkshit BhutaniОценок пока нет
- Chi-Square Pearson SpearmanДокумент8 страницChi-Square Pearson SpearmanTristan da CunhaОценок пока нет
- "A Range of Values Within Which, We Believe, The True Parameter Lies With High Probability" Is CalledДокумент7 страниц"A Range of Values Within Which, We Believe, The True Parameter Lies With High Probability" Is CalledMedia TeamОценок пока нет
- Asas SPSS KuantitatifДокумент10 страницAsas SPSS KuantitatifMuhammad Lukman AlhakimОценок пока нет
- ICT Course Syllabus 2019-2020 PDFДокумент53 страницыICT Course Syllabus 2019-2020 PDFMinh Hiếu100% (1)
- Output SPSS: Tests of NormalityДокумент6 страницOutput SPSS: Tests of NormalityariОценок пока нет
- Study of Students' Perception Regarding Single Common Entrance Examination For Admission in Professional CollegesДокумент33 страницыStudy of Students' Perception Regarding Single Common Entrance Examination For Admission in Professional CollegesRishav SahaОценок пока нет
- A Project On A Statistical Analysis of The E Commerce Businesses in BangladeshДокумент68 страницA Project On A Statistical Analysis of The E Commerce Businesses in BangladeshNayeem Ahamed AdorОценок пока нет
- Chi SquareДокумент8 страницChi SquareGabriella Angelica Jemima HasianОценок пока нет
- RM NOTES, UNIT 1 To 5, SYBAFДокумент81 страницаRM NOTES, UNIT 1 To 5, SYBAFHimanshu UtekarОценок пока нет
- Tbi.b - (1) Research Assumption and HypothesesДокумент5 страницTbi.b - (1) Research Assumption and HypothesesDesi Puspitasari100% (1)