Вам также может понравиться
- Egg Dropping Puzzle: Here Is The AssumptionsДокумент9 страницEgg Dropping Puzzle: Here Is The AssumptionsKan SamuelОценок пока нет
- Data VisualДокумент14 страницData VisualKan SamuelОценок пока нет
- Xtys4: Theorem Example Coefficient of x3 Expansion CxtyДокумент1 страницаXtys4: Theorem Example Coefficient of x3 Expansion CxtyKan SamuelОценок пока нет
- (10 Marks) : Sample AnswerДокумент1 страница(10 Marks) : Sample AnswerKan SamuelОценок пока нет
- DSE 2018 P1 EngДокумент24 страницыDSE 2018 P1 EngKan Samuel50% (2)
- Chapter 3 Supplementary: (Recall That N (N) )Документ5 страницChapter 3 Supplementary: (Recall That N (N) )Kan SamuelОценок пока нет
- EstimationsДокумент183 страницыEstimationsKan Samuel100% (1)
- 3.1 Definition and ... : The Chinese University of Hong KongДокумент3 страницы3.1 Definition and ... : The Chinese University of Hong KongKan SamuelОценок пока нет
- Chapter 2 Supplymentary NotesДокумент8 страницChapter 2 Supplymentary NotesKan SamuelОценок пока нет
- Chapter 1 Mathematical Modelling by Differential Equations: Du DXДокумент7 страницChapter 1 Mathematical Modelling by Differential Equations: Du DXKan SamuelОценок пока нет
- Chapter Nine QuadrilateralsДокумент9 страницChapter Nine QuadrilateralsKan SamuelОценок пока нет
- 5.1 Working Principles: The Chinese University of Hong KongДокумент2 страницы5.1 Working Principles: The Chinese University of Hong KongKan SamuelОценок пока нет
- L20 March 3 CPT: Wednesday, February 25, 2015 8:53 PMДокумент7 страницL20 March 3 CPT: Wednesday, February 25, 2015 8:53 PMKan SamuelОценок пока нет
- 2.1 General Principle: The Chinese University of Hong KongДокумент6 страниц2.1 General Principle: The Chinese University of Hong KongKan SamuelОценок пока нет
- 1.1 Goal and Setting: The Chinese University of Hong KongДокумент2 страницы1.1 Goal and Setting: The Chinese University of Hong KongKan SamuelОценок пока нет
- MATH3290 Assignment 3Документ2 страницыMATH3290 Assignment 3Kan SamuelОценок пока нет
- 2010 Pure Mathematics Paper 1Документ7 страниц2010 Pure Mathematics Paper 1Kan SamuelОценок пока нет
- HKALE Pure Maths Question Distribution (1988-2001)Документ3 страницыHKALE Pure Maths Question Distribution (1988-2001)Kan Samuel100% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Statistical Mechanics Lecture Notes (2006), L28Документ5 страницStatistical Mechanics Lecture Notes (2006), L28OmegaUserОценок пока нет
- Mechanics Chap 3-parts1-2+TD-2021Документ34 страницыMechanics Chap 3-parts1-2+TD-2021Mat MatttОценок пока нет
- Tips For CSIR NET For Physical SciencesДокумент24 страницыTips For CSIR NET For Physical SciencesboltuОценок пока нет
- CATIAДокумент1 403 страницыCATIAanon_188037793100% (1)
- Lecture 19Документ92 страницыLecture 19zahraa allamiОценок пока нет
- Particle On A RingДокумент9 страницParticle On A RingSurendra KarwaОценок пока нет
- Chapter11 PDFДокумент19 страницChapter11 PDFMiguel RamirezОценок пока нет
- Introduction To Quantum Groups by George Lusztig (Auth.)Документ361 страницаIntroduction To Quantum Groups by George Lusztig (Auth.)Gillian SeedОценок пока нет
- Physical ScienceДокумент11 страницPhysical ScienceJosie DilaoОценок пока нет
- Some Double Integral ProblemsДокумент2 страницыSome Double Integral ProblemsShadiOoОценок пока нет
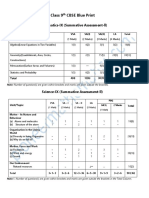
- Class 9th CBSE Blue PrintДокумент2 страницыClass 9th CBSE Blue PrintYash BawiskarОценок пока нет
- Possible Contribution of X-Ray Binary Jets To The Galactic Cosmic Ray and Neutrino FluxДокумент17 страницPossible Contribution of X-Ray Binary Jets To The Galactic Cosmic Ray and Neutrino FluxAndrewОценок пока нет
- Vectors and MatricesДокумент8 страницVectors and MatricesdorathiОценок пока нет
- Ilovepdf MergedДокумент464 страницыIlovepdf Mergedfardous elbadriОценок пока нет
- Chapter 6.4-5 Modeling Shapes With Polygonal MeshesДокумент40 страницChapter 6.4-5 Modeling Shapes With Polygonal MeshesFranklinОценок пока нет
- The Derivative As The Slope of The Tangent Line: (At A Point)Документ20 страницThe Derivative As The Slope of The Tangent Line: (At A Point)Levi LeuckОценок пока нет
- Hydraulic Conductivity and Permeability As Tensors) : 1. Intuitive ThinkingДокумент3 страницыHydraulic Conductivity and Permeability As Tensors) : 1. Intuitive ThinkingwiedzieОценок пока нет
- Chapter 6 - Stress and Strain - A4Документ15 страницChapter 6 - Stress and Strain - A4steven_gog0% (1)
- Assignme nt1: Submitted By: Hamza Yousuf & Fatima ShuaibДокумент7 страницAssignme nt1: Submitted By: Hamza Yousuf & Fatima ShuaibYusra ShuaibОценок пока нет
- 전자기학 1장 솔루션Документ13 страниц전자기학 1장 솔루션이재하Оценок пока нет
- 03 Quadratic FunctionДокумент8 страниц03 Quadratic FunctionVivianne YongОценок пока нет
- Harmonic Analysis and Group RepДокумент9 страницHarmonic Analysis and Group RepStephanie Pacheco100% (1)
- Acknowledgement: Aravindakshan M, HOD, Department of Electronics and Communication ForДокумент24 страницыAcknowledgement: Aravindakshan M, HOD, Department of Electronics and Communication Forsree vishnuОценок пока нет
- A Note On Generalized Cramer's RuleДокумент2 страницыA Note On Generalized Cramer's RuleSuleman AwanОценок пока нет
- Lec 05 (Atomic Structure V)Документ3 страницыLec 05 (Atomic Structure V)Md Abdus SaburОценок пока нет
- Model Exam - I-Question BankДокумент9 страницModel Exam - I-Question BankSyed Safeequr RahmanОценок пока нет
- H.W OF CHAPTER 2 (Using Basic Integration Formulas) PDFДокумент12 страницH.W OF CHAPTER 2 (Using Basic Integration Formulas) PDFJWAN RA YA3QOBОценок пока нет
- Practical-8 Plot The Integral Surfaces of A Given First Order PDE With Initial DataДокумент9 страницPractical-8 Plot The Integral Surfaces of A Given First Order PDE With Initial DataAashna GuptaОценок пока нет
- FileДокумент448 страницFileTs SodariОценок пока нет
- 12c Apostol MRДокумент21 страница12c Apostol MRMarvinApostolОценок пока нет