Вам также может понравиться
- Cours Gestion de ProjetДокумент27 страницCours Gestion de Projet08151579100% (1)
- Modele Fiche Suivi ProjetДокумент5 страницModele Fiche Suivi Projet0815157975% (4)
- Exo ProbaДокумент9 страницExo Proba08151579Оценок пока нет
- Etude ImplantationДокумент2 страницыEtude Implantation08151579Оценок пока нет
- Template UCPДокумент8 страницTemplate UCPLisa ADOUMAОценок пока нет
- Guide D Utilisation de REAPER v3 ch1 11Документ214 страницGuide D Utilisation de REAPER v3 ch1 11Gilles MalatrayОценок пока нет
- ch1 DSPДокумент53 страницыch1 DSPRami MeshriОценок пока нет
- TruenasДокумент55 страницTruenasIT TG CAP100% (1)
- Sujet 1 PDFДокумент2 страницыSujet 1 PDFChristine Mbongo100% (4)
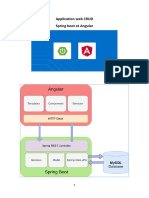
- Atelier 1 - Projet Spring BootДокумент10 страницAtelier 1 - Projet Spring BootJouhaina NasriОценок пока нет
- Cour-Systèmes DistribuésДокумент37 страницCour-Systèmes DistribuésSihem JebariОценок пока нет
- Tuto4you - Installer Mac OSX Sur Son PC - Hackintosh PDFДокумент42 страницыTuto4you - Installer Mac OSX Sur Son PC - Hackintosh PDFLee DestructeurОценок пока нет
- Correction Travaux Dirigés Algo TD3Документ3 страницыCorrection Travaux Dirigés Algo TD3hermannibetowa0% (1)
- SyllabusДокумент30 страницSyllabuselisee NtumbaОценок пока нет
- Introduction À La Programmation Avec Python 2Документ18 страницIntroduction À La Programmation Avec Python 2XenosОценок пока нет
- V1010 French UG B5FJ-5231-01FR-00UGText 0824Документ162 страницыV1010 French UG B5FJ-5231-01FR-00UGText 0824brahimОценок пока нет
- ReseauxДокумент5 страницReseauxtaheniiОценок пока нет
- Script BatchДокумент27 страницScript BatchyzariОценок пока нет
- Programmation en MikroC PROДокумент5 страницProgrammation en MikroC PROFethi BenmassoudeОценок пока нет
- Rapport PFAДокумент31 страницаRapport PFAOussema Bersellou100% (1)
- Distribution RehHat D'openstackДокумент44 страницыDistribution RehHat D'openstackDali HadricheОценок пока нет
- Etiquette EnexistantДокумент4 страницыEtiquette Enexistantkelekey moussa DiakhateОценок пока нет
- Le Grand RobertДокумент4 страницыLe Grand Robertfitzaz1213Оценок пока нет
- Complements-Commandes TPДокумент10 страницComplements-Commandes TPMohammed TesjaleОценок пока нет
- Epson-LQ-350-Fiche Technique PDFДокумент2 страницыEpson-LQ-350-Fiche Technique PDFHasina Tiguan100% (1)
- Formation Implémentation Et Administration Des Solutions CiscoДокумент2 страницыFormation Implémentation Et Administration Des Solutions CiscoTrong Oganort GampoulaОценок пока нет
- Formation Windows 2003 ServerДокумент2 страницыFormation Windows 2003 ServerAbdillah AbdillahОценок пока нет
- Cours C++ 1 PDFДокумент468 страницCours C++ 1 PDFOussam OuadidiОценок пока нет
- 2015 04 25 Supports de CoursДокумент48 страниц2015 04 25 Supports de CoursMohãmed Charâbi100% (1)
- Introduction À NS2Документ25 страницIntroduction À NS2foko sindjoung miguel landryОценок пока нет
- BasededonneesrelationnellesДокумент29 страницBasededonneesrelationnellesivoire net computОценок пока нет
- IngéДокумент2 страницыIngéStartОценок пока нет
- Démarrer Avec Les MFC Par Farscape Version Pour Visual 6.0 Introduction 3Документ97 страницDémarrer Avec Les MFC Par Farscape Version Pour Visual 6.0 Introduction 3Antonio RodrigoОценок пока нет
- Part1 Analyse LexicaleДокумент58 страницPart1 Analyse LexicaleFouad Khatt AriОценок пока нет