Вам также может понравиться
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- Nclex 100 Questions and Answers With Rationale (Pediatric Nursing)Документ206 страницNclex 100 Questions and Answers With Rationale (Pediatric Nursing)maj91% (242)
- TIMELINE TransportationДокумент1 страницаTIMELINE Transportationsny007Оценок пока нет
- Nurse Application LetterДокумент5 страницNurse Application LetterYano Sipit100% (1)
- Presentatio 4 NДокумент1 страницаPresentatio 4 Nsny007Оценок пока нет
- Bleeding in Early and Late: PregnancyДокумент31 страницаBleeding in Early and Late: Pregnancysny007Оценок пока нет
- 081-831-1005 (First Aid To Prevent or Control Shock)Документ13 страниц081-831-1005 (First Aid To Prevent or Control Shock)sny007Оценок пока нет
- NursingCribcom Nursing Care Plan Impaired Urinary EliminationДокумент2 страницыNursingCribcom Nursing Care Plan Impaired Urinary Eliminationsny007Оценок пока нет
- Advent Chapel 2Документ11 страницAdvent Chapel 2sny007Оценок пока нет
- Presentation 1Документ1 страницаPresentation 1sny007Оценок пока нет
- Results. All Five Fractures United in Good Position With No: HOW THE Simmonds-Thompson Test WorksДокумент2 страницыResults. All Five Fractures United in Good Position With No: HOW THE Simmonds-Thompson Test Workssny007Оценок пока нет
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Priyajit's Resume NewДокумент3 страницыPriyajit's Resume Newamrit mohantyОценок пока нет
- Marchel Solis Research PerseveranceДокумент10 страницMarchel Solis Research PerseveranceTata Duero LachicaОценок пока нет
- Scholarship Application FormДокумент4 страницыScholarship Application FormAnonymous fY1HXgJRkzОценок пока нет
- The Falklands War: Causes and LessonsДокумент13 страницThe Falklands War: Causes and Lessonsgtrazor100% (1)
- 15.1 Composition of MatterДокумент23 страницы15.1 Composition of MatterKunal GaikwadОценок пока нет
- US National Design Policy Summit ReportДокумент90 страницUS National Design Policy Summit Reportearthtomj100% (1)
- A320Документ41 страницаA320Varun Kapoor75% (4)
- Discussion QuestionsДокумент9 страницDiscussion QuestionsyourhunkieОценок пока нет
- Fundamentals of Momentum, Heat and Mass TransferДокумент87 страницFundamentals of Momentum, Heat and Mass TransferSlim KanounОценок пока нет
- Chapter 5 - GasesДокумент72 страницыChapter 5 - GasesAmbar WatiОценок пока нет
- Pitch Lesson PlanДокумент6 страницPitch Lesson Planapi-318222702Оценок пока нет
- Importance of Communication in SocietyДокумент16 страницImportance of Communication in SocietyPh843 King's Kids StudentCenterОценок пока нет
- Sunforce 50232 30 Watt Folding Solar Panel Owner's ManualДокумент6 страницSunforce 50232 30 Watt Folding Solar Panel Owner's Manual21st-Century-Goods.comОценок пока нет
- Stereotypes in General-Advantages and Disadvantages: Being Typically EnglishДокумент2 страницыStereotypes in General-Advantages and Disadvantages: Being Typically EnglishDiana IrimieaОценок пока нет
- xr602t Receiver ManualДокумент7 страницxr602t Receiver Manualrizky tantyoОценок пока нет
- Operational Categorization STДокумент3 страницыOperational Categorization STFalcon Peregrine100% (1)
- Notebook Three: Leadership Begins With An AttitudeДокумент19 страницNotebook Three: Leadership Begins With An AttitudeJessie James YapaoОценок пока нет
- Resume of Tahmina Hossain BitheeДокумент3 страницыResume of Tahmina Hossain BitheeJahid HasanОценок пока нет
- Commercial Drafting and Detailing 4th Edition by Jefferis and Smith ISBN Solution ManualДокумент8 страницCommercial Drafting and Detailing 4th Edition by Jefferis and Smith ISBN Solution Manualmatthew100% (22)
- MBDRДокумент4 страницыMBDRenjoydasilenceОценок пока нет
- EVENT MANAGEMENT AssignmentДокумент2 страницыEVENT MANAGEMENT AssignmentYed Alias56% (9)
- 1st Grading Exam in MILДокумент3 страницы1st Grading Exam in MILArchie Alipongoy KolokoyОценок пока нет
- DavidBaker CurranДокумент1 страницаDavidBaker CurranAbhinav DhingraОценок пока нет
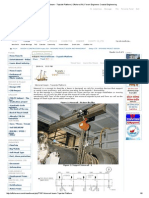
- Monorail Beam - Topside Platform - OffshoreДокумент6 страницMonorail Beam - Topside Platform - OffshoreBolarinwaОценок пока нет
- Acknowledgemt: at The Outset of This Project, I Would Like To Express My Deep Gratitude To Mr. RajnishДокумент6 страницAcknowledgemt: at The Outset of This Project, I Would Like To Express My Deep Gratitude To Mr. RajnishPraveen SehgalОценок пока нет
- Rman Command DocumentДокумент22 страницыRman Command DocumentanandОценок пока нет
- Cca IvgДокумент40 страницCca IvgKhan MohhammadОценок пока нет
- Probset 1 PDFДокумент2 страницыProbset 1 PDFDharavathu AnudeepnayakОценок пока нет
- Acoustical Determinations On A Composite Materials (Extruded Polystyrene Type/ Cork)Документ6 страницAcoustical Determinations On A Composite Materials (Extruded Polystyrene Type/ Cork)pinoyarkiОценок пока нет
- Survey CompressedДокумент394 страницыSurvey CompressedAjay PakhareОценок пока нет