Вам также может понравиться
- Lecture 14Документ17 страницLecture 14Pranav ShreyasОценок пока нет
- Cscu SearchДокумент13 страницCscu Searcholivie lazuardi100% (1)
- 3101 Workbook Version2Документ0 страниц3101 Workbook Version2plume23Оценок пока нет
- CS246: Mining Massive Datasets Jure Leskovec,: Stanford UniversityДокумент53 страницыCS246: Mining Massive Datasets Jure Leskovec,: Stanford UniversitySven De BruynОценок пока нет
- Sparse Vector Methods: Lecture #13 EEE 574 Dr. Dan TylavskyДокумент24 страницыSparse Vector Methods: Lecture #13 EEE 574 Dr. Dan Tylavskyhonestman_usaОценок пока нет
- CS246: Mining Massive Datasets Jure Leskovec,: Stanford UniversityДокумент42 страницыCS246: Mining Massive Datasets Jure Leskovec,: Stanford Universityjure1Оценок пока нет
- Network Dynamics 2013Документ93 страницыNetwork Dynamics 2013Banyan VinesОценок пока нет
- Second-Order Systems: Circuits ElectronicsДокумент19 страницSecond-Order Systems: Circuits Electronicsapi-127299018Оценок пока нет
- EE2092!4!2011 Matrix AnalysisДокумент63 страницыEE2092!4!2011 Matrix AnalysisshrnbolonneОценок пока нет
- 320-2018-2 O1 v1 PDFДокумент18 страниц320-2018-2 O1 v1 PDFJohn SmithОценок пока нет
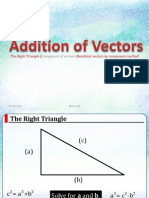
- PPTG101213 - Addition of Vector by Component Method - GALLEGOДокумент26 страницPPTG101213 - Addition of Vector by Component Method - GALLEGORed GallegoОценок пока нет
- Network Design 16.583/483: University of Massachusetts LowellДокумент17 страницNetwork Design 16.583/483: University of Massachusetts LowellEric KialОценок пока нет
- Chapter 5Документ92 страницыChapter 5Asfaw TilahunОценок пока нет
- Community Detection in Social NetworksДокумент64 страницыCommunity Detection in Social NetworksArun ManickОценок пока нет
- MapReduce and Distributed File Systems for Mining Massive DatasetsДокумент48 страницMapReduce and Distributed File Systems for Mining Massive Datasetsvarsha1504Оценок пока нет
- Quiz2 s07 PDFДокумент20 страницQuiz2 s07 PDFAnup RaghuveerОценок пока нет
- Practice Final ExamДокумент17 страницPractice Final ExamSaied Aly SalamahОценок пока нет
- Topic #2Документ24 страницыTopic #2kannan_ei1084Оценок пока нет
- Summarizing DataДокумент20 страницSummarizing Datajoelmx2Оценок пока нет
- The Linear Algebra Behind GoogleДокумент34 страницыThe Linear Algebra Behind Googleanon_990946533Оценок пока нет
- Trajectory Generation L5.MotionPlanningДокумент24 страницыTrajectory Generation L5.MotionPlanningIvan AvramovОценок пока нет
- Ece656 L01Документ21 страницаEce656 L01chinuuu85brОценок пока нет
- Map-Reduce and The New Software Stack: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff UllmanДокумент49 страницMap-Reduce and The New Software Stack: Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff UllmanBunny HoneyОценок пока нет
- Pajek Large Networks PaperДокумент28 страницPajek Large Networks PaperdogajunkОценок пока нет
- Basic Routing Concepts PDFДокумент30 страницBasic Routing Concepts PDFalexisОценок пока нет
- AttenuatorДокумент82 страницыAttenuatoryttan1116Оценок пока нет
- Quiz1 s07Документ26 страницQuiz1 s07Ricardo RodriguezОценок пока нет
- Digital Circuit: Circuits ElectronicsДокумент17 страницDigital Circuit: Circuits Electronicsapi-127299018Оценок пока нет
- Spreadsheet Implementations For Solving Power-Flow ProblemsДокумент21 страницаSpreadsheet Implementations For Solving Power-Flow ProblemsDaryAntoОценок пока нет
- Fast Fourier Transform: VLSI Architectures: Vladimir StojanovićДокумент26 страницFast Fourier Transform: VLSI Architectures: Vladimir StojanovićTharun ThampanОценок пока нет
- Wavelet Based Image Coding: Spring '04 Instructor: Min WuДокумент30 страницWavelet Based Image Coding: Spring '04 Instructor: Min WuzgxfsbjbnОценок пока нет
- Analyses of dam deformations for securityДокумент11 страницAnalyses of dam deformations for securityDjordje NikolicОценок пока нет
- Module 6-: Real Time Big Data ModelsДокумент58 страницModule 6-: Real Time Big Data ModelsAllyОценок пока нет
- Microwave Unit 1Документ141 страницаMicrowave Unit 1AnubhavSaraswatОценок пока нет
- Lecture 15 - P-N Junction (Cont.) March 9, 2007Документ17 страницLecture 15 - P-N Junction (Cont.) March 9, 2007Kenneth Palma CarmonaОценок пока нет
- FDFDДокумент56 страницFDFDjesus1843100% (1)
- Electrical Transient PDFДокумент6 страницElectrical Transient PDFalexwoodwickОценок пока нет
- Internet Tomography: Bin Yu Statistics Department, UC BerkeleyДокумент36 страницInternet Tomography: Bin Yu Statistics Department, UC BerkeleyjoaquimdalmeidaОценок пока нет
- Wavelet Coding and Related IssuesДокумент52 страницыWavelet Coding and Related IssuesullisrinuОценок пока нет
- EE201 Matrix AnalysisДокумент18 страницEE201 Matrix AnalysisAeshwrya PandaОценок пока нет
- Chapter - 2 Power Flow AnalysisДокумент24 страницыChapter - 2 Power Flow AnalysisdivyaОценок пока нет
- Chapter 1Документ28 страницChapter 1uccs1Оценок пока нет
- Basic Routing Concepts: Surasak Sanguanpong Nguan@ku - Ac.thДокумент30 страницBasic Routing Concepts: Surasak Sanguanpong Nguan@ku - Ac.thOnalenna TshupoОценок пока нет
- Inclusion of Tunneling and Size-Quantization Effects in Semi - Classical SimulatorsДокумент41 страницаInclusion of Tunneling and Size-Quantization Effects in Semi - Classical SimulatorsAjayaKumarKavalaОценок пока нет
- CH02 Logic Design With MOSFETsДокумент41 страницаCH02 Logic Design With MOSFETsMohamedОценок пока нет
- Matrix Analysis of Networks: J. R. LucasДокумент63 страницыMatrix Analysis of Networks: J. R. LucasNethmini SamarawickramaОценок пока нет
- WWW - Universityquestions.in: Unit 1 Number Systems and Digital Logic Families Part AДокумент7 страницWWW - Universityquestions.in: Unit 1 Number Systems and Digital Logic Families Part Abunny_589318117Оценок пока нет
- Electromagnetic Field Analysis and Its Applications To Product DevelopmentДокумент9 страницElectromagnetic Field Analysis and Its Applications To Product Developmentkaushikray06Оценок пока нет
- Computer Physics Communications: D. Sokolovski, E. Akhmatskaya, S.K. SenДокумент19 страницComputer Physics Communications: D. Sokolovski, E. Akhmatskaya, S.K. SenDragan SokolovskiОценок пока нет
- MIT 6.002 Circuits and Electronics Quiz #2Документ18 страницMIT 6.002 Circuits and Electronics Quiz #2Vicky SinghОценок пока нет
- 04 CLASS 2012 Scale-Free PropertyДокумент60 страниц04 CLASS 2012 Scale-Free PropertychhistОценок пока нет
- Electricity and Magnetism: Magnetostatics Induction, Vector PotentialДокумент6 страницElectricity and Magnetism: Magnetostatics Induction, Vector PotentialEpic WinОценок пока нет
- CS246: Mining Massive Datasets Jure Leskovec,: Stanford UniversityДокумент58 страницCS246: Mining Massive Datasets Jure Leskovec,: Stanford UniversityTeja KamalОценок пока нет
- ARS CH1 CN BasicsДокумент61 страницаARS CH1 CN Basicskckkb6Оценок пока нет
- Matlab ManualElectromagnetics IДокумент99 страницMatlab ManualElectromagnetics IAnonymous JnvCyu85Оценок пока нет
- Matlab Manual EMFTДокумент99 страницMatlab Manual EMFTpratheep100% (1)
- Method of Moments for 2D Scattering Problems: Basic Concepts and ApplicationsОт EverandMethod of Moments for 2D Scattering Problems: Basic Concepts and ApplicationsОценок пока нет
- MOS Integrated Circuit DesignОт EverandMOS Integrated Circuit DesignE. WolfendaleОценок пока нет
- Spectral Techniques and Fault DetectionОт EverandSpectral Techniques and Fault DetectionMarg KarpovskyОценок пока нет
- CPT105 Final Exam Revision Term1 2013 With AnswersДокумент6 страницCPT105 Final Exam Revision Term1 2013 With Answersmnx4everОценок пока нет
- Microcontroller Talk - Overview of CRES-ARC Voter ID ProjectДокумент31 страницаMicrocontroller Talk - Overview of CRES-ARC Voter ID ProjectSarabjit SinghОценок пока нет
- Hafelle Product PDFДокумент933 страницыHafelle Product PDFSarialam Nababan100% (1)
- Digital Logic ReviewДокумент56 страницDigital Logic ReviewLamija NukicОценок пока нет
- NP 1115 S875WP1TPSДокумент117 страницNP 1115 S875WP1TPSChinnaОценок пока нет
- Inside Intel Management EngineДокумент41 страницаInside Intel Management Engineemazitov-1Оценок пока нет
- IS 12941 (1990): Code of practice for selection and use of super capacity bucket elevatorДокумент14 страницIS 12941 (1990): Code of practice for selection and use of super capacity bucket elevatorXavier LefebvreОценок пока нет
- LF351 PDFДокумент9 страницLF351 PDFIsaac SosaОценок пока нет
- Manual Iq8control eДокумент146 страницManual Iq8control eCiprian BalcanОценок пока нет
- BT Home Hub 5 Engineer Install Guide EI 4.1 (2.0-01)Документ7 страницBT Home Hub 5 Engineer Install Guide EI 4.1 (2.0-01)Istvan IuhaszОценок пока нет
- Cambridge-Audio 540r Ver-2.0 SM PDFДокумент41 страницаCambridge-Audio 540r Ver-2.0 SM PDFTomasz MinsterОценок пока нет
- C Programming MCQsДокумент13 страницC Programming MCQsMaham Tanveer50% (4)
- Msi ms-7125 Rev 0a SCH PDFДокумент33 страницыMsi ms-7125 Rev 0a SCH PDFSebastian QuaroneОценок пока нет
- Face RecognitionДокумент23 страницыFace RecognitionAbdelfattah Al ZaqqaОценок пока нет
- 3694 Prox Chipset Flyer 1Документ3 страницы3694 Prox Chipset Flyer 1resare76Оценок пока нет
- B2150 HSDДокумент310 страницB2150 HSDJuan MayorgaОценок пока нет
- Warranty Terms for HP LaptopsДокумент1 страницаWarranty Terms for HP Laptopsbiggo445Оценок пока нет
- SR-1000 S7-1200 Om 600F51 GB WW 1114-2Документ10 страницSR-1000 S7-1200 Om 600F51 GB WW 1114-2BaroszОценок пока нет
- Mercedes Pass Through GuideДокумент30 страницMercedes Pass Through Guiderobert doddsОценок пока нет
- Simocode Pro System Manual 6316050-22DS01 - 060406Документ504 страницыSimocode Pro System Manual 6316050-22DS01 - 060406sdsmith1972Оценок пока нет
- Flexi EDGE BTSДокумент67 страницFlexi EDGE BTSDel CamachoОценок пока нет
- Musical Instrument Digital InterfaceДокумент30 страницMusical Instrument Digital InterfaceMarcoVillaranReyesОценок пока нет
- Contact WasherДокумент4 страницыContact Washerwuw74824Оценок пока нет
- 170 ADI 350 00 - 32 Pt. Discrete Input Module OverviewДокумент14 страниц170 ADI 350 00 - 32 Pt. Discrete Input Module OverviewGabriel ZorattiОценок пока нет
- Diplocloud Efficient and Scalable Management of RDF Data in The CloudДокумент3 страницыDiplocloud Efficient and Scalable Management of RDF Data in The CloudShaka Technologies100% (1)
- Differential EvolutionДокумент11 страницDifferential EvolutionDuško TovilovićОценок пока нет
- SwitchgearДокумент53 страницыSwitchgearwinsaravananОценок пока нет
- Touchless TouchscreenДокумент11 страницTouchless TouchscreenKrishna Karki100% (1)