Вам также может понравиться
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- 6th Central Pay Commission Salary CalculatorДокумент15 страниц6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Design StandardДокумент201 страницаDesign Standardzaf100% (2)
- Matrix Analysis For ScientistДокумент172 страницыMatrix Analysis For Scientistdialneira7398Оценок пока нет
- (Xian Da) Matrix Analysis (Matrix Inversion Lemma)Документ760 страниц(Xian Da) Matrix Analysis (Matrix Inversion Lemma)Jose Perea Arango100% (2)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Oxygen Cycle: PlantsДокумент3 страницыOxygen Cycle: PlantsApam BenjaminОценок пока нет
- A Philosopher's Understanding of Quantum Mechanics (Vermaas)Документ308 страницA Philosopher's Understanding of Quantum Mechanics (Vermaas)BeatrizFerreira100% (1)
- A Study On School DropoutsДокумент6 страницA Study On School DropoutsApam BenjaminОценок пока нет
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Документ8 страницMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminОценок пока нет
- Lecture7 Module2 Anova 1Документ10 страницLecture7 Module2 Anova 1Apam BenjaminОценок пока нет
- Nitrogen Cycle: Ecological FunctionДокумент8 страницNitrogen Cycle: Ecological FunctionApam BenjaminОценок пока нет
- Research ProposalДокумент6 страницResearch ProposalApam BenjaminОценок пока нет
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenДокумент12 страницCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminОценок пока нет
- Lecture8 Module2 Anova 1Документ13 страницLecture8 Module2 Anova 1Apam BenjaminОценок пока нет
- Lecture6 Module2 Anova 1Документ10 страницLecture6 Module2 Anova 1Apam BenjaminОценок пока нет
- Lecture5 Module2 Anova 1Документ9 страницLecture5 Module2 Anova 1Apam BenjaminОценок пока нет
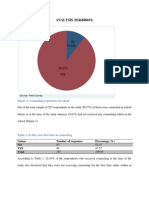
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolДокумент8 страницANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminОценок пока нет
- PLM IiДокумент3 страницыPLM IiApam BenjaminОценок пока нет
- Personal Information: Curriculum VitaeДокумент6 страницPersonal Information: Curriculum VitaeApam BenjaminОценок пока нет
- Hosmer On Survival With StataДокумент21 страницаHosmer On Survival With StataApam BenjaminОценок пока нет
- Finish WorkДокумент116 страницFinish WorkApam BenjaminОценок пока нет
- ARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaДокумент9 страницARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaApam BenjaminОценок пока нет
- PLMДокумент5 страницPLMApam BenjaminОценок пока нет
- Lecture4 Module2 Anova 1Документ9 страницLecture4 Module2 Anova 1Apam BenjaminОценок пока нет
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsДокумент14 страницHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminОценок пока нет
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaДокумент7 страницRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminОценок пока нет
- Ajsms 2 4 348 355Документ8 страницAjsms 2 4 348 355Akolgo PaulinaОценок пока нет
- Trial Questions (PLM)Документ3 страницыTrial Questions (PLM)Apam BenjaminОценок пока нет
- Creating STATA DatasetsДокумент4 страницыCreating STATA DatasetsApam BenjaminОценок пока нет
- How To Write A Paper For A Scientific JournalДокумент10 страницHow To Write A Paper For A Scientific JournalApam BenjaminОценок пока нет
- Banque AtlanticbanДокумент1 страницаBanque AtlanticbanApam BenjaminОценок пока нет
- Project ReportsДокумент31 страницаProject ReportsBilal AliОценок пока нет
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteДокумент1 страницаMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminОценок пока нет
- l.4. Research QuestionsДокумент1 страницаl.4. Research QuestionsApam BenjaminОценок пока нет
- Asri Stata 2013-FlyerДокумент1 страницаAsri Stata 2013-FlyerAkolgo PaulinaОценок пока нет
- Chapter 9-Analytic Geometry in The SpaceДокумент33 страницыChapter 9-Analytic Geometry in The SpaceRicardo RealesОценок пока нет
- M.Sc. (Mathematics) : Proposed Syllabus September 2021Документ49 страницM.Sc. (Mathematics) : Proposed Syllabus September 2021KrishnaОценок пока нет
- 2Документ9 страниц2Sujay SantraОценок пока нет
- Peter Nickolas - Wavelets - A Student Guide-Cambridge University Press (2017)Документ271 страницаPeter Nickolas - Wavelets - A Student Guide-Cambridge University Press (2017)johnnicholasrosettiОценок пока нет
- Business Analytics & Machine Learning: Regression AnalysisДокумент58 страницBusiness Analytics & Machine Learning: Regression AnalysisArda HüseyinoğluОценок пока нет
- Feshbach Projection Formalism For Open Quantum SystemsДокумент5 страницFeshbach Projection Formalism For Open Quantum Systemsdr_do7Оценок пока нет
- Lecture Notes On Ridge RegressionДокумент113 страницLecture Notes On Ridge RegressionMarc RomaníОценок пока нет
- HilbertДокумент91 страницаHilbertalin444444Оценок пока нет
- Linear Algebra PDFДокумент17 страницLinear Algebra PDFIoana CîlniceanuОценок пока нет
- Lecture 4 Orthogonal It yДокумент15 страницLecture 4 Orthogonal It yRamzan8850Оценок пока нет
- Gram-Schmidt Coding AssignmentДокумент8 страницGram-Schmidt Coding AssignmentAlvian Iqbal Hanif NasrullahОценок пока нет
- lecturesLeedsRPF 1Документ9 страницlecturesLeedsRPF 1Mehrosh SeemabОценок пока нет
- Functional Problems PDFДокумент152 страницыFunctional Problems PDFPhouths SptОценок пока нет
- Chapter 7: Dimensionality ReductionДокумент34 страницыChapter 7: Dimensionality Reductions8nd11d UNIОценок пока нет
- Horace Lamb - Statics: Including Hydrostatics and The Elements of The Theory of ElasticityДокумент364 страницыHorace Lamb - Statics: Including Hydrostatics and The Elements of The Theory of ElasticityCrest49Оценок пока нет
- GPU Implementation of An Automatic Target Detection and Classification Algorithm For Hyperspectral Image AnalysisДокумент5 страницGPU Implementation of An Automatic Target Detection and Classification Algorithm For Hyperspectral Image AnalysisSrgio BrnabОценок пока нет
- B.tech Cyber SecurityДокумент166 страницB.tech Cyber SecurityRohit Singh BhatiОценок пока нет
- Kuan C.-M. Introduction To Econometric Theory (LN, Taipei, 2002) (202s) - GLДокумент202 страницыKuan C.-M. Introduction To Econometric Theory (LN, Taipei, 2002) (202s) - GLMateus RamalhoОценок пока нет
- Algebraic Quantum Field Theory: Wojciech DybalskiДокумент51 страницаAlgebraic Quantum Field Theory: Wojciech DybalskiAndrea BeckerОценок пока нет
- Prelims2014-15 Final 1Документ37 страницPrelims2014-15 Final 1SayantanОценок пока нет
- SIGNALPROCESSING KTU Whole SyllabusДокумент65 страницSIGNALPROCESSING KTU Whole Syllabusmanjunath nОценок пока нет
- Introduction To Functional Analysis - Daniel Daners - 2017Документ123 страницыIntroduction To Functional Analysis - Daniel Daners - 2017Carles Vilà i CampsОценок пока нет
- Notes Part 2 PDFДокумент63 страницыNotes Part 2 PDFPraveen KumarОценок пока нет
- Fridberg LinearДокумент16 страницFridberg LinearBryann RSОценок пока нет
- L1-L3 Linear TransformationДокумент35 страницL1-L3 Linear TransformationHarshini MОценок пока нет
- Department of Mathematics MATHS 253: Study Guide For Semester 1, 2017Документ6 страницDepartment of Mathematics MATHS 253: Study Guide For Semester 1, 2017Abdullāh IzzatОценок пока нет