Вам также может понравиться
- Things To Do ListdfДокумент2 страницыThings To Do ListdfLydda CadienteОценок пока нет
- Phil PostДокумент2 страницыPhil PostLydda CadienteОценок пока нет
- Physics Formula NotesДокумент3 страницыPhysics Formula NotesLydda CadienteОценок пока нет
- Useful Email PhrasesДокумент7 страницUseful Email PhrasesLydda CadienteОценок пока нет
- Title Mentorship FinalДокумент1 страницаTitle Mentorship FinalLydda CadienteОценок пока нет
- Useful Email PhrasesДокумент7 страницUseful Email PhrasesLydda CadienteОценок пока нет
- 10-1 Introduction To MetabolismДокумент2 страницы10-1 Introduction To MetabolismLydda CadienteОценок пока нет
- Tokugawa ShogunateДокумент11 страницTokugawa ShogunateLydda CadienteОценок пока нет
- WedДокумент1 страницаWedLydda CadienteОценок пока нет
- Basic Histology of The Respiratory SystemДокумент1 страницаBasic Histology of The Respiratory SystemLydda CadienteОценок пока нет
- BackgroundДокумент1 страницаBackgroundLydda CadienteОценок пока нет
- Medical Board SubjectsДокумент1 страницаMedical Board SubjectsLydda CadienteОценок пока нет
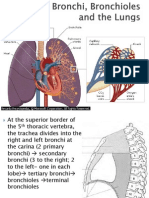
- The Bronchi, Bronchioles and The LungsДокумент12 страницThe Bronchi, Bronchioles and The LungsLydda CadienteОценок пока нет
- PvsДокумент21 страницаPvsLydda Cadiente100% (1)
- Summary of Verb TensesДокумент3 страницыSummary of Verb TensesSisil Vana Hs100% (1)
- 20071121085616L2 U4 Gradable AdjsДокумент1 страница20071121085616L2 U4 Gradable AdjsLydda CadienteОценок пока нет
- Providing FeedbackДокумент92 страницыProviding FeedbackLydda CadienteОценок пока нет
- Gradable and Non-Gradable AdjectivesДокумент5 страницGradable and Non-Gradable AdjectivesLydda Cadiente100% (1)
- McKinsey Problem Solving Test - Practice TestBДокумент28 страницMcKinsey Problem Solving Test - Practice TestBproyecto20132014Оценок пока нет
- MGI Reverse The Curse - Executive Summary - Dec 2013Документ30 страницMGI Reverse The Curse - Executive Summary - Dec 2013Lydda CadienteОценок пока нет
- Medical Board SubjectsДокумент1 страницаMedical Board SubjectsLydda CadienteОценок пока нет
- Sampling DistributionДокумент9 страницSampling DistributionLydda CadienteОценок пока нет
- Summary of Verb TensesДокумент3 страницыSummary of Verb TensesSisil Vana Hs100% (1)
- Death Toll Surpasses 100 As Sewol Search Speeds UpДокумент4 страницыDeath Toll Surpasses 100 As Sewol Search Speeds UpLydda CadienteОценок пока нет
- Medical Board SubjectsДокумент1 страницаMedical Board SubjectsLydda CadienteОценок пока нет
- The Respiratory SystemДокумент1 страницаThe Respiratory SystemLydda CadienteОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- Submission Guidelines - Scientific ReportsДокумент17 страницSubmission Guidelines - Scientific ReportsRoni RoyОценок пока нет
- Module No. 4: Estimation of Parameters: Math 2 - Statistics and Probability 2nd Semester - AY 2020-2021Документ15 страницModule No. 4: Estimation of Parameters: Math 2 - Statistics and Probability 2nd Semester - AY 2020-2021rheena espirituОценок пока нет
- 4SSMN902 May 2022Документ10 страниц4SSMN902 May 2022MattОценок пока нет
- Spot Speed PDFДокумент14 страницSpot Speed PDFরাগীব শুভОценок пока нет
- Student Sol 064 eДокумент98 страницStudent Sol 064 eMinh NguyễnОценок пока нет
- This Study Resource Was: Due at Noon On Friday, March 16, 2007Документ9 страницThis Study Resource Was: Due at Noon On Friday, March 16, 2007Brayan AcostaОценок пока нет
- The Extended Jones-Dole EquationДокумент5 страницThe Extended Jones-Dole EquationYesid Tapiero MartínezОценок пока нет
- Coursera Basic Statistics Final Exam AnswersДокумент9 страницCoursera Basic Statistics Final Exam AnswersFurkan Memmedov100% (2)
- UGC Notes: Research Methodology and AptitudeДокумент7 страницUGC Notes: Research Methodology and AptitudeSowmya KoneruОценок пока нет
- Chapter 10, Two-Stage Cluster SamplingДокумент27 страницChapter 10, Two-Stage Cluster SamplingHelen WangОценок пока нет
- 40 Multiple Choice Questions in Basic StatisticsДокумент38 страниц40 Multiple Choice Questions in Basic StatisticsLokmaniОценок пока нет
- SoltuionsДокумент19 страницSoltuionsBe-fit Be-strongОценок пока нет
- Simulations in Statistical InferenceДокумент12 страницSimulations in Statistical InferenceadmirodebritoОценок пока нет
- Seminsr GarchДокумент14 страницSeminsr GarchHDОценок пока нет
- Statand Prob Q4 M2Документ12 страницStatand Prob Q4 M2Jessa Banawan EdulanОценок пока нет
- Phys 1011labДокумент50 страницPhys 1011labsemabay71% (7)
- ASTM D 2013 - 1986 Standard Method of Preparing Coal Sample For AnalysisДокумент14 страницASTM D 2013 - 1986 Standard Method of Preparing Coal Sample For AnalysisAditya SupriyadiОценок пока нет
- Chapter 3 Analysis and Adjustment of ObservationsДокумент67 страницChapter 3 Analysis and Adjustment of ObservationsAbdul AzimОценок пока нет
- SMK St. Joseph, Kuching - Marking Scheme - STPM Mathematcs Paper 3 - 2014: Section AДокумент6 страницSMK St. Joseph, Kuching - Marking Scheme - STPM Mathematcs Paper 3 - 2014: Section APeng Peng KekОценок пока нет
- Indice de Cambio FiableДокумент3 страницыIndice de Cambio FiableClara NvОценок пока нет
- Chapter 5 Normal Probability DistributionsДокумент22 страницыChapter 5 Normal Probability Distributionsdanilo roblico jr.Оценок пока нет
- Jep 15 4 3Документ8 страницJep 15 4 3Frann AraОценок пока нет
- Debt and Distress - Evaluating The Psychological Cost of CreditДокумент22 страницыDebt and Distress - Evaluating The Psychological Cost of CreditPusatStudyPerilakuEkonomiОценок пока нет
- Quantative Research Methods NotesДокумент50 страницQuantative Research Methods NotesNjeri MbuguaОценок пока нет
- Sampling DistributionДокумент13 страницSampling DistributionImOn NoMiОценок пока нет
- Sampling and Experimental Design PDFДокумент73 страницыSampling and Experimental Design PDFCamila OlmedoОценок пока нет
- Chapter 5 - Random SaplingДокумент25 страницChapter 5 - Random SaplingКонстантин ГришинОценок пока нет
- Quantitative Analysis in FootballДокумент19 страницQuantitative Analysis in FootballTamarai Selvi ArumugamОценок пока нет
- Reading 07-Correlation and RegressionДокумент18 страницReading 07-Correlation and Regression杨坡Оценок пока нет
- Isotope Hydrology Laboratory, IAEA, Vienna Now at Lamont-Doherty Earth Observatory, Columbia University, New YorkДокумент59 страницIsotope Hydrology Laboratory, IAEA, Vienna Now at Lamont-Doherty Earth Observatory, Columbia University, New YorkEduardo IbarraОценок пока нет