Вам также может понравиться
- Questionnaire NewДокумент9 страницQuestionnaire NewravimmccОценок пока нет
- Walfield Practical Protection For Personal Storage in The CloudДокумент7 страницWalfield Practical Protection For Personal Storage in The CloudravimmccОценок пока нет
- University Search EngineДокумент4 страницыUniversity Search EngineravimmccОценок пока нет
- Flow ChartДокумент1 страницаFlow ChartravimmccОценок пока нет
- Resume - SethuДокумент4 страницыResume - SethuravimmccОценок пока нет
- List of TablesДокумент2 страницыList of TablesravimmccОценок пока нет
- Chapter No. Chapter Title Page No.: Project Id: 32 Table of ContentДокумент3 страницыChapter No. Chapter Title Page No.: Project Id: 32 Table of ContentravimmccОценок пока нет
- Project Management DescriptionДокумент1 страницаProject Management DescriptionravimmccОценок пока нет
- Table ScriptДокумент3 страницыTable ScriptravimmccОценок пока нет
- Student Management System: An Extension To HmisДокумент1 страницаStudent Management System: An Extension To HmisravimmccОценок пока нет
- Bca 15Документ2 страницыBca 15ravimmccОценок пока нет
- XQuery NotesДокумент2 страницыXQuery NotesravimmccОценок пока нет
- Fault Analysis On Fault Tolerant Inverter With A Leg SwapДокумент5 страницFault Analysis On Fault Tolerant Inverter With A Leg SwapravimmccОценок пока нет
- Actual Expenses DetailsДокумент2 страницыActual Expenses DetailsravimmccОценок пока нет
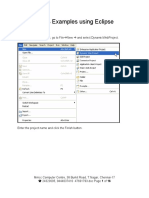
- Struts Examples Using Eclipse: Step: 1Документ16 страницStruts Examples Using Eclipse: Step: 1ravimmccОценок пока нет
- Programmers: Kevin, Iris, BradДокумент21 страницаProgrammers: Kevin, Iris, BradravimmccОценок пока нет
- Software Requirements Specification For Career Bridge: PurposeДокумент10 страницSoftware Requirements Specification For Career Bridge: PurposeravimmccОценок пока нет
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- (688424586) Priyanka Prakash Chouhan II JAVA Developer II IndoreДокумент3 страницы(688424586) Priyanka Prakash Chouhan II JAVA Developer II IndoreGaurav JainОценок пока нет
- Mastering UniPaaSДокумент999 страницMastering UniPaaSVid MalesevicОценок пока нет
- (17CS82) 8 Semester CSE: Big Data AnalyticsДокумент169 страниц(17CS82) 8 Semester CSE: Big Data AnalyticsPrakash GОценок пока нет
- Microsoft Patch Analysis Microsoft Patch Analysis: Yaniv Miron Aka LamentДокумент74 страницыMicrosoft Patch Analysis Microsoft Patch Analysis: Yaniv Miron Aka LamentDebamitra MukherjeeОценок пока нет
- Visio PID Quick Start Guide2016 - 2 - ENДокумент14 страницVisio PID Quick Start Guide2016 - 2 - ENsoorenaОценок пока нет
- C Excersice Programs PDFДокумент118 страницC Excersice Programs PDFGanesh SanjeevОценок пока нет
- Design Patterns in OO ABAPДокумент53 страницыDesign Patterns in OO ABAPyakubshah67% (3)
- Azure Application GatewayДокумент574 страницыAzure Application GatewayJonnathan De La Barra100% (1)
- 50 Web Developer Interview Questions For Sure SuccessДокумент14 страниц50 Web Developer Interview Questions For Sure SuccessRaghu GowdaОценок пока нет
- C Programming NotesДокумент62 страницыC Programming NotestheantarikshaОценок пока нет
- Correlacion LRДокумент6 страницCorrelacion LRAlicia Peña GomezОценок пока нет
- NetBackup82 Plug-In Nutanix-AHV GuideДокумент72 страницыNetBackup82 Plug-In Nutanix-AHV Guidetepotat479Оценок пока нет
- 20486a 01Документ21 страница20486a 01edgardoОценок пока нет
- Socket ProgrammingДокумент15 страницSocket Programmingshubhamg_38Оценок пока нет
- Interview QuestionДокумент41 страницаInterview QuestionAshish KumarОценок пока нет
- Mastering Ruby On Rails - A Beginner's Guide-CRC Press (2022)Документ341 страницаMastering Ruby On Rails - A Beginner's Guide-CRC Press (2022)Danilo CândidoОценок пока нет
- Clad Sample Exam14Документ19 страницClad Sample Exam14Chen Li-RenkoskiОценок пока нет
- Tle7 8 q1 wk2Документ23 страницыTle7 8 q1 wk2CALAPIZ, JANE CLAIRE, R.Оценок пока нет
- React From Zero Sample Chapter React From Zero SampleДокумент36 страницReact From Zero Sample Chapter React From Zero Sampleaditya morajkarОценок пока нет
- Paras Sachdev - Manual TestingДокумент4 страницыParas Sachdev - Manual TestingSumit MishraОценок пока нет
- ReactJS An Open Source JavaScript PDFДокумент44 страницыReactJS An Open Source JavaScript PDFcaretronicsОценок пока нет
- Product Modeling - Best Practice 081110Документ54 страницыProduct Modeling - Best Practice 081110bkrishna.crmОценок пока нет
- SAPR3 Maps ProductДокумент1 страницаSAPR3 Maps Productvenkat576Оценок пока нет
- Ahp31 Ma1phДокумент24 страницыAhp31 Ma1phRittal 96Оценок пока нет
- SC2000 V1.0.392.8 Program Update InstructionsДокумент24 страницыSC2000 V1.0.392.8 Program Update Instructionstan duyОценок пока нет
- Import BuddyДокумент164 страницыImport BuddyRimon HabibОценок пока нет
- Embedded C For MPДокумент57 страницEmbedded C For MPkdtkopОценок пока нет
- Experimentation in Software Engineering An Introduction PDFДокумент2 страницыExperimentation in Software Engineering An Introduction PDFGabe100% (1)
- Chapter 1 - Introduction To Data Structure PDFДокумент35 страницChapter 1 - Introduction To Data Structure PDFSyira RzliОценок пока нет
- JIRA Tutorial: What Is JIRA Software?Документ9 страницJIRA Tutorial: What Is JIRA Software?sudarshanОценок пока нет