Вам также может понравиться
- NET EXAM Paper 1Документ27 страницNET EXAM Paper 1shahid ahmed laskar100% (4)
- A119 Application ExtendedДокумент1 страницаA119 Application Extendedps1188Оценок пока нет
- Analysis and Synthesis of Speech Using MatlabДокумент10 страницAnalysis and Synthesis of Speech Using Matlabps1188Оценок пока нет
- FFT Computation and Generation of SpectrogramДокумент32 страницыFFT Computation and Generation of Spectrogramps1188Оценок пока нет
- Click Here For Full Paper23Документ2 страницыClick Here For Full Paper23ps1188Оценок пока нет
- Stick Diagrams by S.N.bhat, Lecturer, Dept of EC Engg., M.I.T ...Документ19 страницStick Diagrams by S.N.bhat, Lecturer, Dept of EC Engg., M.I.T ...arthy_mariappan3873Оценок пока нет
- Phddissert v24 AugmentedДокумент107 страницPhddissert v24 Augmentedps1188Оценок пока нет
- BDDДокумент17 страницBDDps1188Оценок пока нет
- Carbon Nanotube Circuits: Living With Imperfections and VariationsДокумент6 страницCarbon Nanotube Circuits: Living With Imperfections and Variationsps1188Оценок пока нет
- The Fault DiagnosisДокумент73 страницыThe Fault Diagnosisps1188Оценок пока нет
- LM117/217 LM317: 1.2V To 37V Voltage RegulatorДокумент11 страницLM117/217 LM317: 1.2V To 37V Voltage RegulatorRodrigo Hernandez GonzalezОценок пока нет
- Speech Recognition Using Wavelet TransformДокумент31 страницаSpeech Recognition Using Wavelet TransformabhishekmathurОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- English Literature Coursework Aqa GcseДокумент6 страницEnglish Literature Coursework Aqa Gcsef5d17e05100% (2)
- I. Level of Barriers in ICT Knowledge, Skills, and Competencies No ICT Knowledge, Skills and Competency Barriers SDA DA N A SAДокумент2 страницыI. Level of Barriers in ICT Knowledge, Skills, and Competencies No ICT Knowledge, Skills and Competency Barriers SDA DA N A SAMuhamad KhoerulОценок пока нет
- AOCS Ca 12-55 - 2009 - Phosphorus PDFДокумент2 страницыAOCS Ca 12-55 - 2009 - Phosphorus PDFGeorgianaОценок пока нет
- GP 43-45-DRAFT - Site RestorationДокумент48 страницGP 43-45-DRAFT - Site Restorationmengelito almonte100% (1)
- E&i QC Inspector Resum and DocumentsДокумент24 страницыE&i QC Inspector Resum and DocumentsIrfan 786pakОценок пока нет
- Amplifier Frequency ResponseДокумент28 страницAmplifier Frequency ResponseBenj MendozaОценок пока нет
- MY-SDK-10000-EE-005 - Method Statement For Concrete Pole Installation - GVB Rev1Документ7 страницMY-SDK-10000-EE-005 - Method Statement For Concrete Pole Installation - GVB Rev1Seeths NairОценок пока нет
- Put Them Into A Big Bowl. Serve The Salad in Small Bowls. Squeeze Some Lemon Juice. Cut The Fruits Into Small Pieces. Wash The Fruits. Mix The FruitsДокумент2 страницыPut Them Into A Big Bowl. Serve The Salad in Small Bowls. Squeeze Some Lemon Juice. Cut The Fruits Into Small Pieces. Wash The Fruits. Mix The FruitsNithya SweetieОценок пока нет
- RAMSCRAM-A Flexible RAMJET/SCRAMJET Engine Simulation ProgramДокумент4 страницыRAMSCRAM-A Flexible RAMJET/SCRAMJET Engine Simulation ProgramSamrat JanjanamОценок пока нет
- Fashion Goes VirtualДокумент1 страницаFashion Goes VirtualJessica MichaultОценок пока нет
- Digital Economy 1Документ11 страницDigital Economy 1Khizer SikanderОценок пока нет
- Ingredients EnsaymadaДокумент3 страницыIngredients Ensaymadajessie OcsОценок пока нет
- MSC 200Документ18 страницMSC 200Amit KumarОценок пока нет
- Iot Practical 1Документ15 страницIot Practical 1A26Harsh KalokheОценок пока нет
- Plant Gardening AerationДокумент4 страницыPlant Gardening Aerationut.testbox7243Оценок пока нет
- Final Sent Technical Specification 14.03.2019Документ16 страницFinal Sent Technical Specification 14.03.2019harishОценок пока нет
- D-Dimer DZ179A Parameters On The Beckman AU680 Rev. AДокумент1 страницаD-Dimer DZ179A Parameters On The Beckman AU680 Rev. AAlberto MarcosОценок пока нет
- Chapter 5 - Shear and Diagonal Tension On Beams PDFДокумент55 страницChapter 5 - Shear and Diagonal Tension On Beams PDFJhe Taguines100% (1)
- 0apageo Catalogue Uk 2022Документ144 страницы0apageo Catalogue Uk 2022Kouassi JaurèsОценок пока нет
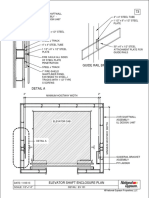
- Guide Rail Bracket AssemblyДокумент1 страницаGuide Rail Bracket AssemblyPrasanth VarrierОценок пока нет
- CHAPTER I KyleДокумент13 страницCHAPTER I KyleCresiel Pontijon100% (1)
- Multidimensional Scaling Groenen Velden 2004 PDFДокумент14 страницMultidimensional Scaling Groenen Velden 2004 PDFjoséОценок пока нет
- Understand Fox Behaviour - Discover WildlifeДокумент1 страницаUnderstand Fox Behaviour - Discover WildlifeChris V.Оценок пока нет
- Design and Implementation of Hotel Management SystemДокумент36 страницDesign and Implementation of Hotel Management Systemaziz primbetov100% (2)
- Lite Indicator Admin ManualДокумент16 страницLite Indicator Admin Manualprabakar070Оценок пока нет
- DS WhitePaper Troubleshooting 3DEXPERIENCE ABEND SituationsДокумент26 страницDS WhitePaper Troubleshooting 3DEXPERIENCE ABEND SituationsSam AntonyОценок пока нет
- E-Cat35xt014 Xtro PhantomsДокумент32 страницыE-Cat35xt014 Xtro PhantomsKari Wilfong100% (5)
- Antibiotic I and II HWДокумент4 страницыAntibiotic I and II HWAsma AhmedОценок пока нет
- Practice Problems For Modulus and Logarithm Section-I: FiitjeeДокумент8 страницPractice Problems For Modulus and Logarithm Section-I: FiitjeePratham SharmaОценок пока нет
- Available Online Through: International Journal of Mathematical Archive-4 (12), 2013Документ4 страницыAvailable Online Through: International Journal of Mathematical Archive-4 (12), 2013Gwen WalkerОценок пока нет