Вам также может понравиться
- Homework 1 Tarea 1Документ11 страницHomework 1 Tarea 1Anette Wendy Quipo Kancha100% (1)
- Ramrajya 2025Документ39 страницRamrajya 2025maxabs121Оценок пока нет
- BTL Marketing CompanyДокумент30 страницBTL Marketing Companypradip_kumarОценок пока нет
- Practice Problems For Modulus and Logarithm Section-I: FiitjeeДокумент8 страницPractice Problems For Modulus and Logarithm Section-I: FiitjeePratham SharmaОценок пока нет
- Data Integrity Proofs in Cloud StorageДокумент9 страницData Integrity Proofs in Cloud StorageDaya ReaddeeОценок пока нет
- Image SteganographyДокумент43 страницыImage SteganographyAnuОценок пока нет
- Automated and Digitalized Campus Management System of Iil: V.C.GAUTHAM (REG. NO: 08FD015)Документ8 страницAutomated and Digitalized Campus Management System of Iil: V.C.GAUTHAM (REG. NO: 08FD015)Gautham VcОценок пока нет
- Ajay Kumar A Synopsis On-Cloud ComputingДокумент10 страницAjay Kumar A Synopsis On-Cloud ComputingwebstdsnrОценок пока нет
- 5 Steps To Designing An Embedded Software Architecture, Step 3Документ7 страниц5 Steps To Designing An Embedded Software Architecture, Step 3sclu2000Оценок пока нет
- 2014-Data Structure Archaeology - Scrape Away The Dirt and Glue Back The PiecesДокумент20 страниц2014-Data Structure Archaeology - Scrape Away The Dirt and Glue Back The PiecesabolfazlshamsОценок пока нет
- End-To-End Arguments in System DesignДокумент12 страницEnd-To-End Arguments in System DesignblahОценок пока нет
- SteganographyДокумент32 страницыSteganographysathishОценок пока нет
- International Journal of Engineering Research and Development (IJERD)Документ5 страницInternational Journal of Engineering Research and Development (IJERD)IJERDОценок пока нет
- Activities ESPДокумент4 страницыActivities ESPIcha Ramadhany MОценок пока нет
- Cloud Computing Dynamin Key GenerationДокумент20 страницCloud Computing Dynamin Key GenerationrajtalwarОценок пока нет
- Final Report 3Документ44 страницыFinal Report 3Barath Kumar DhanushОценок пока нет
- On Adaptive Grid Middleware New Orleans, LA, September 2003Документ15 страницOn Adaptive Grid Middleware New Orleans, LA, September 2003Federico Di MattiaОценок пока нет
- Cloud ComputingДокумент17 страницCloud ComputingUdit KathpaliaОценок пока нет
- INTRODUCTION To DFDДокумент19 страницINTRODUCTION To DFDAshish Kumar SinghОценок пока нет
- Mc0071 - Software Engineering SET-1 4. What About The Programming For Reliability?Документ8 страницMc0071 - Software Engineering SET-1 4. What About The Programming For Reliability?9937116687Оценок пока нет
- Mc0071-Software Engineering Test 4.what About The Programming For Reliability?Документ4 страницыMc0071-Software Engineering Test 4.what About The Programming For Reliability?9937116687Оценок пока нет
- Optimal Performance of Security by Fragmentation and Replication of Data in CloudДокумент6 страницOptimal Performance of Security by Fragmentation and Replication of Data in CloudIJRASETPublicationsОценок пока нет
- IJRASET35861 PaperДокумент6 страницIJRASET35861 PaperNeha Verma MehlawatОценок пока нет
- Algorithm For Intelligent Network Visualization and Threat AnalysisДокумент6 страницAlgorithm For Intelligent Network Visualization and Threat Analysissurendiran123Оценок пока нет
- Third Party Auditing For Secure Data Storage in Cloud Through Trusted Third Party Auditor Using RC5Документ5 страницThird Party Auditing For Secure Data Storage in Cloud Through Trusted Third Party Auditor Using RC5International Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- SSRN Id3909350Документ14 страницSSRN Id3909350manjusha s nОценок пока нет
- Discovering and Mitigating Software Vulnerabilities Through Large Scale CollaborationДокумент43 страницыDiscovering and Mitigating Software Vulnerabilities Through Large Scale Collaborationjamessabraham2Оценок пока нет
- Literature Review On Visual CryptographyДокумент8 страницLiterature Review On Visual Cryptographyafmyervganedba100% (1)
- Bilinear Pairing Based Public Auditing For Secure Cloud Storage Using TpaДокумент10 страницBilinear Pairing Based Public Auditing For Secure Cloud Storage Using TpaInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- WhitepaperДокумент11 страницWhitepaperapi-252145303Оценок пока нет
- Design Patterns - Embedded Software Design - A Practical Approach To Architecture, Processes, and Coding TechniquesДокумент30 страницDesign Patterns - Embedded Software Design - A Practical Approach To Architecture, Processes, and Coding TechniquesamiteshanandОценок пока нет
- Complete DocumentДокумент33 страницыComplete DocumentnebulaaОценок пока нет
- Srs and DesignДокумент8 страницSrs and DesignVipin Kumar NОценок пока нет
- Steganography ReportДокумент62 страницыSteganography Reportkamal_sanwal100% (2)
- Project DocumentationДокумент57 страницProject DocumentationMahesh PalaniОценок пока нет
- CQRS Documents by Greg YoungДокумент56 страницCQRS Documents by Greg YoungAndrey ChasovskikhОценок пока нет
- Thesis Report On Image EncryptionДокумент4 страницыThesis Report On Image EncryptionKarin Faust100% (2)
- Book Information+Security UNIT+IIДокумент30 страницBook Information+Security UNIT+IIHerculesОценок пока нет
- Thesis Information SecurityДокумент7 страницThesis Information Securityaflowlupyfcyye100% (1)
- Matrimonial Portal DocumentДокумент11 страницMatrimonial Portal DocumentthangatpОценок пока нет
- Welcome To International Journal of Engineering Research and Development (IJERD)Документ3 страницыWelcome To International Journal of Engineering Research and Development (IJERD)IJERDОценок пока нет
- Efficient Data Storage Security Analysis Using Randomized Algorithm in CloudДокумент6 страницEfficient Data Storage Security Analysis Using Randomized Algorithm in CloudmanikantaОценок пока нет
- Cloud Drop: Student InformationДокумент9 страницCloud Drop: Student InformationManal FaluojiОценок пока нет
- B 17 SynopsisДокумент7 страницB 17 SynopsissanketОценок пока нет
- Computer Forensics Research Paper OutlineДокумент8 страницComputer Forensics Research Paper Outlineikrndjvnd100% (1)
- Data Storage 2pdfДокумент5 страницData Storage 2pdfIsrat6730 JahanОценок пока нет
- Graphical Password AuthenticationДокумент9 страницGraphical Password AuthenticationHaritha Chowdary ChagarlamudiОценок пока нет
- Rupesh SynoДокумент8 страницRupesh SynoAshokupadhye1955Оценок пока нет
- ProjectДокумент69 страницProjectChocko AyshuОценок пока нет
- Watermarking Synopsis AДокумент13 страницWatermarking Synopsis AAshish BhardwajОценок пока нет
- Part 1: What Is N-Tier Architecture?: Karim HyattДокумент8 страницPart 1: What Is N-Tier Architecture?: Karim HyattSurendra BansalОценок пока нет
- CCL ProjectДокумент13 страницCCL Projectenggeng7Оценок пока нет
- Example Application of The Risk Analysis Tool (RAT)Документ6 страницExample Application of The Risk Analysis Tool (RAT)eliasox123Оценок пока нет
- Dishant Synopsis 1Документ9 страницDishant Synopsis 1Rina MoonОценок пока нет
- E-Fraud DetectionДокумент49 страницE-Fraud DetectionUDAY SOLUTIONSОценок пока нет
- Introduction and SRS: Chapter-1Документ38 страницIntroduction and SRS: Chapter-1Akash MishraОценок пока нет
- A Methodology To Conceal QR Codes For Security AppДокумент8 страницA Methodology To Conceal QR Codes For Security AppIvan JordanОценок пока нет
- First Level ReportДокумент38 страницFirst Level ReportsaranОценок пока нет
- 1NH16MCA22Документ73 страницы1NH16MCA22Deepan KarthikОценок пока нет
- Cloud Computing ReportДокумент40 страницCloud Computing ReportAmanpwl92100% (3)
- Our Approach 3.1. Problem DescriptionДокумент3 страницыOur Approach 3.1. Problem DescriptionDeepak SelvakumarОценок пока нет
- Cloud Computing Term Paper: Ahsan ArshadДокумент6 страницCloud Computing Term Paper: Ahsan ArshadRana AhsanОценок пока нет
- Research Papers Computer Network SecurityДокумент7 страницResearch Papers Computer Network Securitytigvxstlg100% (1)
- Cloud: Get All The Support And Guidance You Need To Be A Success At Using The CLOUDОт EverandCloud: Get All The Support And Guidance You Need To Be A Success At Using The CLOUDОценок пока нет
- Customized and Secure Image Steganography Through Random Numbers LogicДокумент16 страницCustomized and Secure Image Steganography Through Random Numbers LogicjyotsnaroopОценок пока нет
- College Hostel Management System: A Mini Project Report Submitted in Partial Fulfillment For The Award of Degree ofДокумент37 страницCollege Hostel Management System: A Mini Project Report Submitted in Partial Fulfillment For The Award of Degree ofjyotsnaroopОценок пока нет
- Steganography: Data Hiding Using LSB AlgorithmДокумент63 страницыSteganography: Data Hiding Using LSB AlgorithmNani Koduri94% (31)
- A Cautionary Note On Image DowngradingДокумент7 страницA Cautionary Note On Image DowngradingjyotsnaroopОценок пока нет
- Steganography - Messages Hidden in Bits: Jonathan WatkinsДокумент10 страницSteganography - Messages Hidden in Bits: Jonathan WatkinsjyotsnaroopОценок пока нет
- Analysis of Modern Steganographic Techniques: Remya UnnikrishnanДокумент4 страницыAnalysis of Modern Steganographic Techniques: Remya UnnikrishnanjyotsnaroopОценок пока нет
- B.E. CSEgbДокумент98 страницB.E. CSEgbjyotsnaroopОценок пока нет
- Research Journal Our ProjectДокумент7 страницResearch Journal Our ProjectjyotsnaroopОценок пока нет
- Steganography - Messages Hidden in Bits: Jonathan WatkinsДокумент10 страницSteganography - Messages Hidden in Bits: Jonathan WatkinsjyotsnaroopОценок пока нет
- Analysis of Modern Steganographic Techniques: Remya UnnikrishnanДокумент4 страницыAnalysis of Modern Steganographic Techniques: Remya UnnikrishnanjyotsnaroopОценок пока нет
- Customized and Secure Image Steganography Through Random Numbers LogicДокумент16 страницCustomized and Secure Image Steganography Through Random Numbers LogicjyotsnaroopОценок пока нет
- Steganography - Messages Hidden in Bits: Jonathan WatkinsДокумент10 страницSteganography - Messages Hidden in Bits: Jonathan WatkinsjyotsnaroopОценок пока нет
- Steganography - Messages Hidden in Bits: Jonathan WatkinsДокумент10 страницSteganography - Messages Hidden in Bits: Jonathan WatkinsjyotsnaroopОценок пока нет
- MyResume RecentДокумент1 страницаMyResume RecentNish PatwaОценок пока нет
- Chapter 1Документ20 страницChapter 1Li YuОценок пока нет
- RAMSCRAM-A Flexible RAMJET/SCRAMJET Engine Simulation ProgramДокумент4 страницыRAMSCRAM-A Flexible RAMJET/SCRAMJET Engine Simulation ProgramSamrat JanjanamОценок пока нет
- 面向2035的新材料强国战略研究 谢曼Документ9 страниц面向2035的新材料强国战略研究 谢曼hexuan wangОценок пока нет
- Problem Solving Questions: Solutions (Including Comments)Документ25 страницProblem Solving Questions: Solutions (Including Comments)Narendrn KanaesonОценок пока нет
- VISCOLAM202 D20 Acrylic 20 Thickeners 202017Документ33 страницыVISCOLAM202 D20 Acrylic 20 Thickeners 202017Oswaldo Manuel Ramirez MarinОценок пока нет
- Minimization Z Z Z Z Maximization Z Z : LP IPДокумент13 страницMinimization Z Z Z Z Maximization Z Z : LP IPSandeep Kumar JhaОценок пока нет
- W1 - V1 MultipleWorksheets SolnДокумент3 страницыW1 - V1 MultipleWorksheets SolnAKHIL RAJ SОценок пока нет
- Digital Economy 1Документ11 страницDigital Economy 1Khizer SikanderОценок пока нет
- Calculating Measures of Position Quartiles Deciles and Percentiles of Ungrouped DataДокумент43 страницыCalculating Measures of Position Quartiles Deciles and Percentiles of Ungrouped DataRea Ann ManaloОценок пока нет
- Analysis of Mozarts k.475Документ2 страницыAnalysis of Mozarts k.475ASPASIA FRAGKOUОценок пока нет
- Topic 3 - Analyzing The Marketing EnvironmentДокумент28 страницTopic 3 - Analyzing The Marketing Environmentmelissa chlОценок пока нет
- Strategy Guide To Twilight Imperium Third EditionДокумент74 страницыStrategy Guide To Twilight Imperium Third Editioninquartata100% (1)
- What Are The Challenges and Opportunities of ResearchingДокумент5 страницWhat Are The Challenges and Opportunities of ResearchingmelkyОценок пока нет
- GP 43-45-DRAFT - Site RestorationДокумент48 страницGP 43-45-DRAFT - Site Restorationmengelito almonte100% (1)
- Aruba 8325 Switch SeriesДокумент51 страницаAruba 8325 Switch SeriesgmtrlzОценок пока нет
- Anzsco SearchДокумент6 страницAnzsco SearchytytОценок пока нет
- Industrial Training ReportДокумент19 страницIndustrial Training ReportKapil Prajapati33% (3)
- Inkolo Namasiko Kuyamakha Umuntu - Brainly - inДокумент1 страницаInkolo Namasiko Kuyamakha Umuntu - Brainly - inxqxfkqpy5qОценок пока нет
- 2062 TSSR Site Sharing - Rev02Документ44 страницы2062 TSSR Site Sharing - Rev02Rio DefragОценок пока нет
- Put Them Into A Big Bowl. Serve The Salad in Small Bowls. Squeeze Some Lemon Juice. Cut The Fruits Into Small Pieces. Wash The Fruits. Mix The FruitsДокумент2 страницыPut Them Into A Big Bowl. Serve The Salad in Small Bowls. Squeeze Some Lemon Juice. Cut The Fruits Into Small Pieces. Wash The Fruits. Mix The FruitsNithya SweetieОценок пока нет
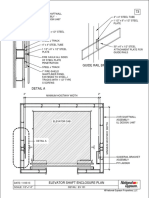
- Guide Rail Bracket AssemblyДокумент1 страницаGuide Rail Bracket AssemblyPrasanth VarrierОценок пока нет
- Consumer PresentationДокумент30 страницConsumer PresentationShafiqur Rahman KhanОценок пока нет
- BERKLYNInformation SheetДокумент6 страницBERKLYNInformation SheetvillatoreubenОценок пока нет
- Genstat Release 10.3de (Pc/Windows 7) 28 May 2012 06:35:59Документ6 страницGenstat Release 10.3de (Pc/Windows 7) 28 May 2012 06:35:59Anna Nur HidayatiОценок пока нет
- APPSC GR I Initial Key Paper IIДокумент52 страницыAPPSC GR I Initial Key Paper IIdarimaduguОценок пока нет