Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Sample MidTerm Multiple Choice Spring 2018Документ3 страницыSample MidTerm Multiple Choice Spring 2018Barbie LCОценок пока нет
- Event Guide: CGT Asset Disposal and Other EventsДокумент8 страницEvent Guide: CGT Asset Disposal and Other EventsVMROОценок пока нет
- Introduction of Unilever: These Main Target and Objectives AreДокумент2 страницыIntroduction of Unilever: These Main Target and Objectives AresanameharОценок пока нет
- Credit Risk Management of Pubali Bank LimitedДокумент11 страницCredit Risk Management of Pubali Bank Limitedsweet-smileОценок пока нет
- 4831 S2016 PS2 AnswerKeyДокумент9 страниц4831 S2016 PS2 AnswerKeyAmy20160302Оценок пока нет
- Sap Press Catalog 2008 SpringДокумент32 страницыSap Press Catalog 2008 Springmehul_sap100% (1)
- Food and Beverage OperationsДокумент6 страницFood and Beverage OperationsDessa F. GatilogoОценок пока нет
- Group Presentation Guides: Real Company Analysis Improvement InitiativesДокумент9 страницGroup Presentation Guides: Real Company Analysis Improvement InitiativesVy LêОценок пока нет
- NFT Data Startup Snickerdoodle Labs Raises $2.3M Seed Round From Kenetic, Blockchain Capital, Tribe Capital and FTX/Sam Bankman-FriedДокумент3 страницыNFT Data Startup Snickerdoodle Labs Raises $2.3M Seed Round From Kenetic, Blockchain Capital, Tribe Capital and FTX/Sam Bankman-FriedPR.comОценок пока нет
- The Ultimate Meeting Guide - How To Run A Meeting Like A ProДокумент21 страницаThe Ultimate Meeting Guide - How To Run A Meeting Like A ProAca ChchОценок пока нет
- Asst. Manager - Materials Management (Feed & Fuel Procurement)Документ1 страницаAsst. Manager - Materials Management (Feed & Fuel Procurement)mohanmba11Оценок пока нет
- Ch04 Environmental Scanning and Industry AnalysisДокумент38 страницCh04 Environmental Scanning and Industry AnalysisMona LeeОценок пока нет
- Manual Guía de Operaciones HSBCNetДокумент14 страницManual Guía de Operaciones HSBCNetJorge SanchezОценок пока нет
- Integration The Growth Strategies of Hotel ChainsДокумент14 страницIntegration The Growth Strategies of Hotel ChainsTatiana PosseОценок пока нет
- CAPE Management of Business 2008 U2 P2Документ4 страницыCAPE Management of Business 2008 U2 P2Sherlock LangevineОценок пока нет
- EU-28 - SBA Fact Sheet 2019Документ52 страницыEU-28 - SBA Fact Sheet 2019Ardy BОценок пока нет
- FB - Solution Readiness Dashboard - L2 - SP06Документ34 страницыFB - Solution Readiness Dashboard - L2 - SP06Alison MartinsОценок пока нет
- Big Data Management and Data AnalyticsДокумент6 страницBig Data Management and Data AnalyticsLelaki Pertama TamboenОценок пока нет
- Ohsas 18001 2007Документ29 страницOhsas 18001 2007не мораОценок пока нет
- Forexbee Co Order Blocks ForexДокумент11 страницForexbee Co Order Blocks ForexMr WatcherОценок пока нет
- Hidden Costof Quality AReviewДокумент21 страницаHidden Costof Quality AReviewmghili2002Оценок пока нет
- Financial Performance of Western India Plywoods LtdДокумент105 страницFinancial Performance of Western India Plywoods LtdMeena SivasubramanianОценок пока нет
- REVIEWER UFRS (Finals)Документ5 страницREVIEWER UFRS (Finals)cynthia karylle natividadОценок пока нет
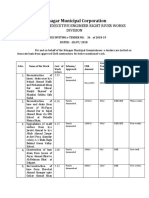
- Srinagar Municipal Corporation: Office of The Executive Engineer Right River Works DivisionДокумент7 страницSrinagar Municipal Corporation: Office of The Executive Engineer Right River Works DivisionBeigh Umair ZahoorОценок пока нет
- Quiz 1-CfasДокумент8 страницQuiz 1-CfasRizelle ViloriaОценок пока нет
- AUD QuizesДокумент9 страницAUD QuizesDanielОценок пока нет
- Chapter 6 B629Документ60 страницChapter 6 B629Ahmed DahiОценок пока нет
- Mcgraw-Hill/Irwin: Levy/Weitz: Retailing Management, 4/EДокумент19 страницMcgraw-Hill/Irwin: Levy/Weitz: Retailing Management, 4/ESatprit HanspalОценок пока нет
- Observation Commercial Banks PDFДокумент52 страницыObservation Commercial Banks PDFyash_dalal123Оценок пока нет
- Resume Amit KR Singh NewДокумент3 страницыResume Amit KR Singh NewCharlie GuptaОценок пока нет