Вам также может понравиться
- MB048 Operations ResearchДокумент10 страницMB048 Operations ResearchKaran SharmaОценок пока нет
- MB 0045Документ6 страницMB 0045Sandeep KumarОценок пока нет
- MB048 Operations ResearchДокумент10 страницMB048 Operations ResearchKaran SharmaОценок пока нет
- Finance ManagementДокумент8 страницFinance ManagementKaran SharmaОценок пока нет
- Paper ID (A0412)Документ2 страницыPaper ID (A0412)Karan SharmaОценок пока нет
- MB0048Документ25 страницMB0048Wasim_Siddiqui_31Оценок пока нет
- Punjab Technical University Jalandhar Syllabus SchemeДокумент35 страницPunjab Technical University Jalandhar Syllabus Schemesushant100% (1)
- Part-III: Admission Procedure Profile of InstitutionsДокумент5 страницPart-III: Admission Procedure Profile of InstitutionsKaran SharmaОценок пока нет
- Project Report On Online Shopping in JAVAДокумент75 страницProject Report On Online Shopping in JAVAManish Yadav83% (35)
- Relationships Beyond Banking: Star House, Plot C-5, "G" Block, Bandra-Kurla Complex, Bandra (East), MumbaiДокумент18 страницRelationships Beyond Banking: Star House, Plot C-5, "G" Block, Bandra-Kurla Complex, Bandra (East), Mumbairockyj47Оценок пока нет
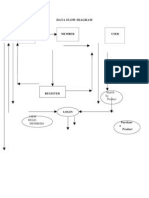
- Admin Member User: Data Flow DiagramДокумент2 страницыAdmin Member User: Data Flow DiagramKaran SharmaОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Problem Set 3 SOLUTIONSДокумент7 страницProblem Set 3 SOLUTIONSLuca VanzОценок пока нет
- WLP Statistics Probability Week 8Документ3 страницыWLP Statistics Probability Week 8Love RazeОценок пока нет
- Test of Hypothesis - T and Z Tests. Chi-Square Test. F Test.Документ15 страницTest of Hypothesis - T and Z Tests. Chi-Square Test. F Test.Barath RajОценок пока нет
- Chapter 08Документ41 страницаChapter 08Hasan TarekОценок пока нет
- Pretest PostestДокумент4 страницыPretest PostestClare GardoseОценок пока нет
- Tests of HypothesisДокумент48 страницTests of HypothesisDenmark Aleluya0% (1)
- Applied Logistic RegressionДокумент15 страницApplied Logistic RegressionjoeОценок пока нет
- Project Part IIДокумент6 страницProject Part IIScott UnderwoodОценок пока нет
- Research Methodology Solved Mcqs Set 14Документ7 страницResearch Methodology Solved Mcqs Set 14Alok ChaurasiaОценок пока нет
- Chen 2007Документ42 страницыChen 2007Jonathan MansillaОценок пока нет
- Stat 101 Mid Term 2021Документ6 страницStat 101 Mid Term 2021صلاح الصلاحيОценок пока нет
- ch4 302mktДокумент41 страницаch4 302mktPrinces April ArrezaОценок пока нет
- Cen Math08 AmparolrДокумент108 страницCen Math08 Amparolrqwe23 asdОценок пока нет
- Quantitative MathematicsДокумент4 страницыQuantitative MathematicsCayla Mae TransfiguracionОценок пока нет
- STAT (Assignment #1)Документ1 страницаSTAT (Assignment #1)Mika MolinaОценок пока нет
- Stat2 2020 - Practice ExamДокумент26 страницStat2 2020 - Practice ExamSeptian Nendra SaidОценок пока нет
- Exam Practise QuestionsДокумент42 страницыExam Practise Questionsngcamusiphesihle12Оценок пока нет
- Test Anxiety and Academic Achievement in Thiruvannamalai DistrictДокумент4 страницыTest Anxiety and Academic Achievement in Thiruvannamalai DistrictEditor IJTSRDОценок пока нет
- Hypothesis Testing in The Multiple Regression ModelДокумент23 страницыHypothesis Testing in The Multiple Regression ModelMartinОценок пока нет
- Buss. Stat CH-2Документ13 страницBuss. Stat CH-2Jk K100% (1)
- English and Stastics SAT 1Документ5 страницEnglish and Stastics SAT 1Kassahun TerechaОценок пока нет
- Module 5 - AnovaДокумент7 страницModule 5 - AnovaIvy BautistaОценок пока нет
- Business Statistics NOtesДокумент46 страницBusiness Statistics NOtesChetanОценок пока нет
- Grade 10 4th QuarterДокумент13 страницGrade 10 4th QuarterJaninne Villa Del ReyОценок пока нет
- 3.1987 - An Extended Quasi-Likelihood Functions - Nelder-PregibonДокумент13 страниц3.1987 - An Extended Quasi-Likelihood Functions - Nelder-PregibonsssОценок пока нет
- Quarter 4 MATHEMATICS 10: Week 1-3 - Measures of PositionДокумент10 страницQuarter 4 MATHEMATICS 10: Week 1-3 - Measures of Positionnelsonalec049Оценок пока нет
- Chapter 1: Introduction To Survey AdjustmentДокумент6 страницChapter 1: Introduction To Survey AdjustmentNoor Faizah ZohardinОценок пока нет
- StatisticsДокумент8 страницStatisticsMarinel Mae ChicaОценок пока нет
- Multistage SamplingДокумент29 страницMultistage SamplingRizki Amalia Puji SantosaОценок пока нет
- The Impact of Information System (IS) On Organziational Performace: With Special Refernce To Ethio-Telecom Southern Region, HawassaДокумент9 страницThe Impact of Information System (IS) On Organziational Performace: With Special Refernce To Ethio-Telecom Southern Region, HawassatristiansamuelОценок пока нет