Вам также может понравиться
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Govuscourtsca9briefs1275 BWДокумент898 страницGovuscourtsca9briefs1275 BWmiguel6789Оценок пока нет
- Hearing Committee On Agriculture House of RepresentativesДокумент253 страницыHearing Committee On Agriculture House of Representativesmiguel6789Оценок пока нет
- Newson Minchin From Capture To SaleДокумент388 страницNewson Minchin From Capture To Salemiguel6789100% (1)
- The Gendered Rhetoric of Heroism andДокумент36 страницThe Gendered Rhetoric of Heroism andmiguel6789Оценок пока нет
- The Unveiled Apple Ethnicity Gender and The Limits of Inter-Discursive Interpretation of Iranian Contemporary ArtДокумент22 страницыThe Unveiled Apple Ethnicity Gender and The Limits of Inter-Discursive Interpretation of Iranian Contemporary Artmiguel6789Оценок пока нет
- The Modernization of Iran and The Development of The Persian Carpet Industry The Neo-Classical Era in The Persian Carpet Industry 1925 - 45Документ29 страницThe Modernization of Iran and The Development of The Persian Carpet Industry The Neo-Classical Era in The Persian Carpet Industry 1925 - 45miguel6789Оценок пока нет
- The Concept of Heroism in Samburu Moran EthosДокумент15 страницThe Concept of Heroism in Samburu Moran Ethosmiguel6789Оценок пока нет
- Ocw Poder Dimensiones Interpersonal Organizacional GlobalДокумент3 страницыOcw Poder Dimensiones Interpersonal Organizacional Globalmiguel6789Оценок пока нет
- How Can We Study HeroismДокумент15 страницHow Can We Study Heroismmiguel6789Оценок пока нет
- Heroism: A Conceptual Analysis and Differentiation Between Heroic Action and Altruism - Franco, Blau & Zimbardo 2011Документ15 страницHeroism: A Conceptual Analysis and Differentiation Between Heroic Action and Altruism - Franco, Blau & Zimbardo 2011Zeno FrancoОценок пока нет
- Ocw Humanos y Otros AnimalesДокумент4 страницыOcw Humanos y Otros Animalesmiguel6789Оценок пока нет
- Heroism and The Fear of DeathДокумент3 страницыHeroism and The Fear of Deathmiguel6789Оценок пока нет
- Ocw Grecia AntiguaДокумент1 страницаOcw Grecia Antiguamiguel6789Оценок пока нет
- Ocw Fundamentos de La Cultura I Civilizaciones y TextosДокумент2 страницыOcw Fundamentos de La Cultura I Civilizaciones y Textosmiguel6789Оценок пока нет
- Ocw Origenes Del HombreДокумент2 страницыOcw Origenes Del Hombremiguel6789Оценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Crop MicrometeorologyДокумент22 страницыCrop Micrometeorologyrajkumarpai100% (1)
- Xfoil - Users - Manual 6.9 PDFДокумент38 страницXfoil - Users - Manual 6.9 PDFSepideОценок пока нет
- Oracle Retail Invoice Matching 12.0 Defect Report: Bug Number: Severity: Functional Areas: Cross-Product ImpactДокумент4 страницыOracle Retail Invoice Matching 12.0 Defect Report: Bug Number: Severity: Functional Areas: Cross-Product ImpactBali BalisОценок пока нет
- Sikatop 77d Pds enДокумент2 страницыSikatop 77d Pds enTran Tien DungОценок пока нет
- Market Technician No 44Документ16 страницMarket Technician No 44ppfahdОценок пока нет
- Grammatical Development in A Mayan Sign Language-Austin German-CILLA - IXДокумент26 страницGrammatical Development in A Mayan Sign Language-Austin German-CILLA - IXAustin Allen GermanОценок пока нет
- Superconductivity - V. Ginzburg, E. Andryushin (World, 1994) WWДокумент100 страницSuperconductivity - V. Ginzburg, E. Andryushin (World, 1994) WWPhilip Ngem50% (2)
- TFG Lost in Intercultural Translation (Beta)Документ25 страницTFG Lost in Intercultural Translation (Beta)Oxo AfedoxoОценок пока нет
- Guide To GENEX Assistant Drive Test (20101031)Документ28 страницGuide To GENEX Assistant Drive Test (20101031)Aruna FermadiОценок пока нет
- r121 Auto Cash App ErdДокумент2 страницыr121 Auto Cash App ErdLam TranОценок пока нет
- Exchanger Tube Data Analysis PDFДокумент9 страницExchanger Tube Data Analysis PDFArjed Ali ShaikhОценок пока нет
- University of Khartoum Department of Electrical and Electronic Engineering Fourth YearДокумент61 страницаUniversity of Khartoum Department of Electrical and Electronic Engineering Fourth YearMohamed AlserОценок пока нет
- Unit N°1: Institucion Educativa Politécnico de Soledad English 10ThДокумент3 страницыUnit N°1: Institucion Educativa Politécnico de Soledad English 10ThMaria EscolarОценок пока нет
- Hibernate Search ReferenceДокумент118 страницHibernate Search ReferenceSiarhei SakovichОценок пока нет
- 3 Flowserve CatalogueДокумент268 страниц3 Flowserve CatalogueSudherson JagannathanОценок пока нет
- Pierderea Auzului Cauzata de Afectarea Transmiterii Sunetelor (Surditatea de Transmisie) : SunteleДокумент3 страницыPierderea Auzului Cauzata de Afectarea Transmiterii Sunetelor (Surditatea de Transmisie) : SunteleBianca AndreeaОценок пока нет
- 5 NopauseДокумент95 страниц5 NopauseLA garnerОценок пока нет
- E-Cell DSCOE IIT Bombay - 2018 19Документ12 страницE-Cell DSCOE IIT Bombay - 2018 19abhiОценок пока нет
- 3406 Discrete MathematicsДокумент3 страницы3406 Discrete MathematicsFaiza ShafiqОценок пока нет
- Fieldcrest Division of Fieldcrest MillsДокумент3 страницыFieldcrest Division of Fieldcrest Millsmayur2510.20088662Оценок пока нет
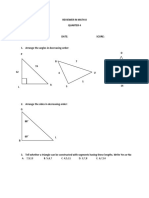
- Reviewer in Math 8Документ13 страницReviewer in Math 8Cañeda AlejanioОценок пока нет
- Stochastic ProgrammingДокумент315 страницStochastic Programmingfeiying1980100% (1)
- Why Slabs Curl - Part1Документ6 страницWhy Slabs Curl - Part1Tim LinОценок пока нет
- A SF Study of Field Marketing Across Europe P IДокумент17 страницA SF Study of Field Marketing Across Europe P IMasud RahmanОценок пока нет
- Burns and Bush Chapter 2Документ14 страницBurns and Bush Chapter 2Naga Avinash0% (1)
- Chapter Three SpeechДокумент12 страницChapter Three SpeechAlex GetachewОценок пока нет
- CREW: Department of Defense: Department of The Army: Regarding PTSD Diagnosis: 6/30/2011 - Release Pgs 1-241 On 24 May 2011Документ241 страницаCREW: Department of Defense: Department of The Army: Regarding PTSD Diagnosis: 6/30/2011 - Release Pgs 1-241 On 24 May 2011CREWОценок пока нет
- HDPOps-ManageAmbari Docker GA Rev3Документ485 страницHDPOps-ManageAmbari Docker GA Rev3narsingthakurОценок пока нет
- Zhong-Lin Lu, Barbara Dosher-Visual Psychophysics - From Laboratory To Theory-The MIT Press (2013)Документ465 страницZhong-Lin Lu, Barbara Dosher-Visual Psychophysics - From Laboratory To Theory-The MIT Press (2013)IrinaОценок пока нет
- Punctuated Equilibrium Theory Explaining Stability and Change in Public Policymaking - Syed Rashedul HossenДокумент21 страницаPunctuated Equilibrium Theory Explaining Stability and Change in Public Policymaking - Syed Rashedul HossenRashed ShukornoОценок пока нет