Вам также может понравиться
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- High Performance DjangoДокумент170 страницHigh Performance DjangoThiago MonteiroОценок пока нет
- Toyota (Automobile) - Waqas FinalДокумент55 страницToyota (Automobile) - Waqas FinalRaza HassanОценок пока нет
- Vmax All Flash FamilyДокумент44 страницыVmax All Flash Familyhimanshu shekharОценок пока нет
- Enterprise Firewall 6.2 Study Guide-Online PDFДокумент529 страницEnterprise Firewall 6.2 Study Guide-Online PDFfasih60% (5)
- Fishing Industry of PakistanДокумент17 страницFishing Industry of PakistanRaza Hassan100% (2)
- Basic Guidelines - Mortgage UnderwritingДокумент3 страницыBasic Guidelines - Mortgage UnderwritingRaza HassanОценок пока нет
- Quality Control and TQM: SC Johnson & Sons Pakistan (PVT) LTDДокумент35 страницQuality Control and TQM: SC Johnson & Sons Pakistan (PVT) LTDRaza Hassan100% (2)
- Imamat: The Perfection of Deen: Quran (2:30)Документ8 страницImamat: The Perfection of Deen: Quran (2:30)Raza HassanОценок пока нет
- CM Report FinalДокумент30 страницCM Report FinalRaza HassanОценок пока нет
- The Communication Process: Mcgraw-Hill/IrwinДокумент15 страницThe Communication Process: Mcgraw-Hill/IrwinuuuuufffffОценок пока нет
- DescartesДокумент7 страницDescartesRaza HassanОценок пока нет
- Imamat: The Perfection of Deen: Quran (2:30)Документ8 страницImamat: The Perfection of Deen: Quran (2:30)Raza HassanОценок пока нет
- FIm301 Slides01Документ22 страницыFIm301 Slides01Raza HassanОценок пока нет
- HBL Case Study-FinalДокумент11 страницHBL Case Study-FinalRaza HassanОценок пока нет
- YouthCentral CV-Template VCE NoExperienceДокумент5 страницYouthCentral CV-Template VCE NoExperienceRaza HassanОценок пока нет
- Drug Control OrganizationДокумент6 страницDrug Control OrganizationRaza HassanОценок пока нет
- The Role of Imc in The Marketing Process: Mcgraw-Hill/IrwinДокумент15 страницThe Role of Imc in The Marketing Process: Mcgraw-Hill/IrwinRaza HassanОценок пока нет
- Report DetailsДокумент2 страницыReport DetailsRaza HassanОценок пока нет
- Privatization of PTCLДокумент2 страницыPrivatization of PTCLRaza HassanОценок пока нет
- Bank History + ProfileДокумент1 страницаBank History + ProfileRaza HassanОценок пока нет
- Summary Economic GrowthДокумент3 страницыSummary Economic GrowthRaza HassanОценок пока нет
- Financial Institutions and MarketsДокумент3 страницыFinancial Institutions and MarketsRaza HassanОценок пока нет
- 28 April 2012Документ1 страница28 April 2012Raza HassanОценок пока нет
- Questionnaire EditedДокумент12 страницQuestionnaire EditedRaza HassanОценок пока нет
- MerckДокумент3 страницыMerckRaza HassanОценок пока нет
- Group Dynamics: Proposal: Organizational BehaviourДокумент6 страницGroup Dynamics: Proposal: Organizational BehaviourRaza HassanОценок пока нет
- Open SSLProgrammingДокумент28 страницOpen SSLProgrammingsandydaОценок пока нет
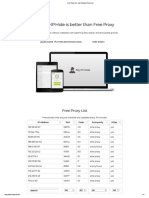
- Free Proxy List - Just Checked Proxy ListДокумент4 страницыFree Proxy List - Just Checked Proxy ListHarish KumarОценок пока нет
- SRDF AДокумент80 страницSRDF Apadhiary jagannathОценок пока нет
- DB LOB Sizing v54Документ17 страницDB LOB Sizing v54Jebabalanmari JebabalanОценок пока нет
- Operating Systems Sample Exam AnswersДокумент49 страницOperating Systems Sample Exam AnswersPrabir K DasОценок пока нет
- CAA-Online Exam UpdateДокумент2 страницыCAA-Online Exam UpdateBidisha gogoiОценок пока нет
- CsgoДокумент41 страницаCsgoYash HartalkarОценок пока нет
- Cache ManagementДокумент38 страницCache ManagementRight BrainОценок пока нет
- MegaTron User GuideДокумент84 страницыMegaTron User GuideGustavo VarelaОценок пока нет
- CS 3853 Computer Architecture - Memory HierarchyДокумент37 страницCS 3853 Computer Architecture - Memory HierarchyJothi RamasamyОценок пока нет
- Design Patterns for Building Network Agnostic Android AppsДокумент62 страницыDesign Patterns for Building Network Agnostic Android AppsShree DiiОценок пока нет
- System On Chip Architecture: James E. Stine Advanced Architectures - CachesДокумент24 страницыSystem On Chip Architecture: James E. Stine Advanced Architectures - CachesThi NguyenОценок пока нет
- Guidelines For Report Development in CognosДокумент5 страницGuidelines For Report Development in CognosArpit AgrawalОценок пока нет
- JQuery DataTables Interaction With Server Side CachingДокумент10 страницJQuery DataTables Interaction With Server Side CachingGabriel GomesОценок пока нет
- Cache Fusion and RAC BGДокумент3 страницыCache Fusion and RAC BGsreeharirao kadaliОценок пока нет
- It Research PaperДокумент5 страницIt Research PaperJunaidОценок пока нет
- Redp5474 - FlashSystem A9000 Model 425Документ34 страницыRedp5474 - FlashSystem A9000 Model 425kenneth corradineОценок пока нет
- Daily Activity Report - COATS-PRD Systems 15th Oct 2015Документ47 страницDaily Activity Report - COATS-PRD Systems 15th Oct 2015Aryan ChoudharyОценок пока нет
- BlueCoat Roger GotthardssonДокумент81 страницаBlueCoat Roger GotthardssonBerrezeg MahieddineОценок пока нет
- HP StoreAll Storage File System User GuideДокумент294 страницыHP StoreAll Storage File System User GuideSamuel LekhbakОценок пока нет
- Linkedin Communication Architecture: Ruslan Belkin, Sean DawsonДокумент31 страницаLinkedin Communication Architecture: Ruslan Belkin, Sean DawsonVikrant SawatkarОценок пока нет
- Netapp CFДокумент9 страницNetapp CFmanas199Оценок пока нет
- Hyperion System 9 Financial Management Subcube Architecture 0406Документ12 страницHyperion System 9 Financial Management Subcube Architecture 0406ligiamolguin9426Оценок пока нет
- Acer AMS2100 2300 Product Presentation v2.0 20100803Документ31 страницаAcer AMS2100 2300 Product Presentation v2.0 20100803rejnanОценок пока нет
- RedSysTech Cloud AWS Day 10Документ24 страницыRedSysTech Cloud AWS Day 10SouravОценок пока нет
- AU80 v17.5 To v18.0 XG Firewall Training UpdateДокумент109 страницAU80 v17.5 To v18.0 XG Firewall Training UpdateEudes MillánОценок пока нет
- VNX5600 Storage ConfigurationДокумент8 страницVNX5600 Storage ConfigurationTestiesОценок пока нет