Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- The Lecture For Turbo CДокумент82 страницыThe Lecture For Turbo CDvschumacher100% (5)
- Buffer Overflow Attacks, SQL Injection AttacksДокумент42 страницыBuffer Overflow Attacks, SQL Injection AttacksRaymondОценок пока нет
- TCS NQT Questions and Answers For Programming LogicДокумент4 страницыTCS NQT Questions and Answers For Programming LogicSamkit Sanghvi100% (1)
- PIC Semester IIДокумент9 страницPIC Semester IIYagnam JoshiОценок пока нет
- Buffer OverflowДокумент9 страницBuffer OverflowesolchagaОценок пока нет
- CkitДокумент129 страницCkitsdgdsgОценок пока нет
- FYBCA SyllabusДокумент37 страницFYBCA SyllabusJoel AdhavОценок пока нет
- What Is The Purpose of Main Function?: CHAPTER 3: FunctionsДокумент39 страницWhat Is The Purpose of Main Function?: CHAPTER 3: FunctionsvictoriajudeОценок пока нет
- C & DS NotesДокумент83 страницыC & DS NotesAsif Ali KhanОценок пока нет
- Circuit Diagram For Interfacing SIM300 GSM Modem To AT89S52Документ32 страницыCircuit Diagram For Interfacing SIM300 GSM Modem To AT89S52sunpnairОценок пока нет
- PHP W3schools TutorialДокумент25 страницPHP W3schools TutorialRahul AmbadkarОценок пока нет
- Gujarat Technological UniversityДокумент3 страницыGujarat Technological UniversityHema JoshiОценок пока нет
- Functions of String in C++Документ9 страницFunctions of String in C++Khawaja SabbaqОценок пока нет
- PPS FileДокумент70 страницPPS File1234 5678Оценок пока нет
- 1 - Avr-Libc-User-Manual-1.0.3 PDFДокумент185 страниц1 - Avr-Libc-User-Manual-1.0.3 PDFGiuseppe MoreseОценок пока нет
- C Functions ReferenceДокумент656 страницC Functions ReferenceramshivaОценок пока нет
- Microsoft C RunTime Library ReferenceДокумент864 страницыMicrosoft C RunTime Library Referencesaurabhade100% (1)
- Matlab Cheat SheetДокумент4 страницыMatlab Cheat SheetHafeth DawbaaОценок пока нет
- C&ds 3rd Unit For EeeДокумент26 страницC&ds 3rd Unit For Eeeamaraiah2012Оценок пока нет
- StringsДокумент22 страницыStringsNishant AroraОценок пока нет
- Strings: - A String Is A Sequence of Characters Treated As A Group - We Have Already Used Some String LiteralsДокумент48 страницStrings: - A String Is A Sequence of Characters Treated As A Group - We Have Already Used Some String LiteralsJNUОценок пока нет
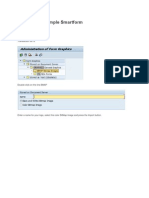
- Creation of A Simple Smartform-EmailДокумент21 страницаCreation of A Simple Smartform-Emailanjan01100% (1)
- Everything You Need To Know About Pointers in CДокумент13 страницEverything You Need To Know About Pointers in CAdewale QuadriОценок пока нет
- Aricent PPRДокумент52 страницыAricent PPRPriyanka GuptaОценок пока нет
- Strings PDFДокумент21 страницаStrings PDFGoutham Mukkera123Оценок пока нет
- Cricket Score Management Mini Project PDF FreeДокумент21 страницаCricket Score Management Mini Project PDF FreeAmit mahi0% (1)
- Absolute C 6th Edition Savitch Solutions ManualДокумент30 страницAbsolute C 6th Edition Savitch Solutions ManualDavidKingprzaОценок пока нет
- Unit-2 C-LanguageДокумент33 страницыUnit-2 C-LanguageklОценок пока нет
- Change LogДокумент29 страницChange LogKITA22Оценок пока нет
- C LanguageДокумент450 страницC LanguagePrince Agyenim Boateng67% (3)