Вам также может понравиться
- Note-Stat Ch2 EstimationДокумент8 страницNote-Stat Ch2 EstimationRHLОценок пока нет
- SAA For JCCДокумент18 страницSAA For JCCShu-Bo YangОценок пока нет
- A-level Maths Revision: Cheeky Revision ShortcutsОт EverandA-level Maths Revision: Cheeky Revision ShortcutsРейтинг: 3.5 из 5 звезд3.5/5 (8)
- Maximum LikelihoodДокумент7 страницMaximum LikelihoodBhogendra MishraОценок пока нет
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)От EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)Оценок пока нет
- Variational Problems in Machine Learning and Their Solution With Finite ElementsДокумент11 страницVariational Problems in Machine Learning and Their Solution With Finite ElementsJohn David ReaverОценок пока нет
- Difference Equations in Normed Spaces: Stability and OscillationsОт EverandDifference Equations in Normed Spaces: Stability and OscillationsОценок пока нет
- Point Estimation: Definition of EstimatorsДокумент8 страницPoint Estimation: Definition of EstimatorsUshnish MisraОценок пока нет
- Elgenfunction Expansions Associated with Second Order Differential EquationsОт EverandElgenfunction Expansions Associated with Second Order Differential EquationsОценок пока нет
- 3 Bayesian Deep LearningДокумент33 страницы3 Bayesian Deep LearningNishanth ManikandanОценок пока нет
- Very-High-Precision Normalized Eigenfunctions For A Class of SCHR Odinger Type EquationsДокумент6 страницVery-High-Precision Normalized Eigenfunctions For A Class of SCHR Odinger Type EquationshiryanizamОценок пока нет
- Random Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilityДокумент14 страницRandom Signals: 1 Kolmogorov's Axiomatic Definition of ProbabilitySeham RaheelОценок пока нет
- On The Markov Chain Monte Carlo (MCMC) Method: Rajeeva L KarandikarДокумент24 страницыOn The Markov Chain Monte Carlo (MCMC) Method: Rajeeva L KarandikarDiana DilipОценок пока нет
- Resampling Methods For Time SeriesДокумент5 страницResampling Methods For Time SeriesMark Carlos SecadaОценок пока нет
- EM AlgoДокумент8 страницEM AlgocoolaclОценок пока нет
- HMWK 4Документ5 страницHMWK 4Jasmine NguyenОценок пока нет
- Introduction To Stochastic Approximation AlgorithmsДокумент14 страницIntroduction To Stochastic Approximation AlgorithmsMassimo TormenОценок пока нет
- Lemaire Et Al. - 2020 - New Weak Error Bounds and Expansions For Optimal QДокумент25 страницLemaire Et Al. - 2020 - New Weak Error Bounds and Expansions For Optimal QManuel MirandaОценок пока нет
- Non Linear Root FindingДокумент16 страницNon Linear Root FindingMichael Ayobami AdelekeОценок пока нет
- Solved Examples of Cramer Rao Lower BoundДокумент6 страницSolved Examples of Cramer Rao Lower BoundIk RamОценок пока нет
- 6 Monte Carlo Simulation: Exact SolutionДокумент10 страниц6 Monte Carlo Simulation: Exact SolutionYuri PazaránОценок пока нет
- Markov Models: 1 DefinitionsДокумент10 страницMarkov Models: 1 DefinitionsraviОценок пока нет
- Ridge 3Документ4 страницыRidge 3manishnegiiОценок пока нет
- Hoeffding BoundsДокумент9 страницHoeffding Boundsphanminh91Оценок пока нет
- Large Deviations: S. R. S. VaradhanДокумент12 страницLarge Deviations: S. R. S. VaradhanLuis Alberto FuentesОценок пока нет
- Empirical ProcessesДокумент47 страницEmpirical Processesalin444444Оценок пока нет
- Lim 05429427Документ10 страницLim 05429427thisisme987681649816Оценок пока нет
- CS229 Lecture Notes: Supervised LearningДокумент30 страницCS229 Lecture Notes: Supervised LearninganilkramОценок пока нет
- CS229 Lecture Notes: Supervised LearningДокумент30 страницCS229 Lecture Notes: Supervised LearningAlistair GnowОценок пока нет
- Chap7 Random ProcessДокумент21 страницаChap7 Random ProcessSeham RaheelОценок пока нет
- 08 Aos674Документ30 страниц08 Aos674siti hayatiОценок пока нет
- Tutorial 4Документ7 страницTutorial 4Amrit RajОценок пока нет
- CS 229, Spring 2016 Problem Set #1: Supervised Learning: m −y θ x m θ (i) (i)Документ8 страницCS 229, Spring 2016 Problem Set #1: Supervised Learning: m −y θ x m θ (i) (i)Achuthan SekarОценок пока нет
- CS 229, Autumn 2016 Problem Set #1: Supervised Learning: m −y θ x m θ (i) (i)Документ8 страницCS 229, Autumn 2016 Problem Set #1: Supervised Learning: m −y θ x m θ (i) (i)patrickОценок пока нет
- Lempa 2012Документ28 страницLempa 2012fgОценок пока нет
- ESL: Chapter 1: 1.1 Introduction To Linear RegressionДокумент4 страницыESL: Chapter 1: 1.1 Introduction To Linear RegressionPete Jacopo Belbo CayaОценок пока нет
- 10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon UniversityДокумент6 страниц10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon Universitytarun guptaОценок пока нет
- Cramer Raoh and Out 08Документ13 страницCramer Raoh and Out 08Waranda AnutaraampaiОценок пока нет
- Chapter 8 Estimation of Parameters and Fitting of Probability DistributionsДокумент20 страницChapter 8 Estimation of Parameters and Fitting of Probability DistributionshoithanhОценок пока нет
- MIT14 30s09 Lec17Документ9 страницMIT14 30s09 Lec17Thahir HussainОценок пока нет
- Lecture 5 - Dirac Delta Functions, Characteristic Functions, and The Law of Large NumbersДокумент3 страницыLecture 5 - Dirac Delta Functions, Characteristic Functions, and The Law of Large NumbersRobert WexlerОценок пока нет
- Report4 Density Estimation AllДокумент63 страницыReport4 Density Estimation AllJohnОценок пока нет
- Statistics 512 Notes I D. SmallДокумент8 страницStatistics 512 Notes I D. SmallSandeep SinghОценок пока нет
- Roots of Equations: 1.0.1 Newton's MethodДокумент20 страницRoots of Equations: 1.0.1 Newton's MethodMahmoud El-MahdyОценок пока нет
- Limiting Average Cost Control Problems in A Class of Discrete-Time Stochastic SystemsДокумент13 страницLimiting Average Cost Control Problems in A Class of Discrete-Time Stochastic SystemsLuis Alberto FuentesОценок пока нет
- Second-Order Nonlinear Least Squares Estimation: Liqun WangДокумент18 страницSecond-Order Nonlinear Least Squares Estimation: Liqun WangJyoti GargОценок пока нет
- 15.097: Probabilistic Modeling and Bayesian AnalysisДокумент42 страницы15.097: Probabilistic Modeling and Bayesian AnalysisSarbani DasguptsОценок пока нет
- BMCjisjksdДокумент11 страницBMCjisjksdErikaОценок пока нет
- Nussbaum 19 I SingДокумент13 страницNussbaum 19 I SingFNОценок пока нет
- Andersson Djehiche - AMO 2011Документ16 страницAndersson Djehiche - AMO 2011artemischen0606Оценок пока нет
- Monte CarloДокумент19 страницMonte CarloRopan EfendiОценок пока нет
- Probability Theory: 1 Heuristic IntroductionДокумент17 страницProbability Theory: 1 Heuristic IntroductionEpic WinОценок пока нет
- 1 Preliminaries: 1.1 Dynkin's π-λ TheoremДокумент13 страниц1 Preliminaries: 1.1 Dynkin's π-λ TheoremvdoblinОценок пока нет
- Homework 2Документ4 страницыHomework 2Muhammad MurtazaОценок пока нет
- Basic Monte Carlo TechniquesДокумент10 страницBasic Monte Carlo TechniquesMobeen AhmadОценок пока нет
- July 1, 2009 11:54 WSPC/102-IDAQPRT 00360Документ17 страницJuly 1, 2009 11:54 WSPC/102-IDAQPRT 00360Mehdi RezaieОценок пока нет
- Random ProcessДокумент21 страницаRandom ProcessgkmkkОценок пока нет
- On Convergence Rates in The Central Limit Theorems For Combinatorial StructuresДокумент18 страницOn Convergence Rates in The Central Limit Theorems For Combinatorial StructuresValerio CambareriОценок пока нет
- SimulationДокумент8 страницSimulationrebsonОценок пока нет
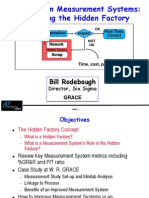
- Six Sigma in Measurement Systems Evaluating The Hidden FactoryДокумент30 страницSix Sigma in Measurement Systems Evaluating The Hidden FactorymaniiscribdОценок пока нет
- The Reality of PrayerДокумент54 страницыThe Reality of Prayerfaithefin100% (3)
- GHTF Process Validation GuideДокумент36 страницGHTF Process Validation GuidexLarcXDОценок пока нет
- HW14 SolutionДокумент4 страницыHW14 SolutionVictoria MooreОценок пока нет
- Measurement System AnalysisДокумент19 страницMeasurement System AnalysisVictoria MooreОценок пока нет
- ChemistryGoodInfo Chemistry I Exam 2Документ17 страницChemistryGoodInfo Chemistry I Exam 2Victoria MooreОценок пока нет
- SIMAN CarWash OutputДокумент1 страницаSIMAN CarWash OutputVictoria MooreОценок пока нет
- HW 3 Spring 2003Документ9 страницHW 3 Spring 2003Victoria MooreОценок пока нет
- In Zone Worksheet: Session 1 Session 2 Session 3 Session 4 All 8 WeeksДокумент2 страницыIn Zone Worksheet: Session 1 Session 2 Session 3 Session 4 All 8 WeeksVictoria MooreОценок пока нет
- Chemical FormulasДокумент9 страницChemical FormulasVictoria MooreОценок пока нет
- Find I in The Circuit Using Nodal Analysis: V V I MaДокумент6 страницFind I in The Circuit Using Nodal Analysis: V V I MaVictoria MooreОценок пока нет
- Chemistry 101 - 2001 Answers To Questions For Assignment #8 and Quiz #8Документ14 страницChemistry 101 - 2001 Answers To Questions For Assignment #8 and Quiz #8Victoria MooreОценок пока нет
- ProbStat Key 1Документ5 страницProbStat Key 1Victoria Moore100% (2)
- Circuits Practice HW 1 Spring 2003Документ7 страницCircuits Practice HW 1 Spring 2003Victoria MooreОценок пока нет
- Arena 8 RandomVariateGenerationДокумент12 страницArena 8 RandomVariateGenerationVictoria MooreОценок пока нет
- Chemistry 101 - 2001 Answers Assignment #2 and Quiz 2Документ7 страницChemistry 101 - 2001 Answers Assignment #2 and Quiz 2Victoria MooreОценок пока нет
- Dow Chemical Design For Six Sigma Rail Delivery ProjectДокумент4 страницыDow Chemical Design For Six Sigma Rail Delivery ProjectVictoria MooreОценок пока нет
- Circuits Midterm 1 SolutionsДокумент6 страницCircuits Midterm 1 SolutionsVictoria MooreОценок пока нет
- Circuits PracticeHW 2 Spring 2003Документ8 страницCircuits PracticeHW 2 Spring 2003Victoria MooreОценок пока нет
- Problem 3.10 Use Nodal Analysis To Find and in The Circuit ShownДокумент18 страницProblem 3.10 Use Nodal Analysis To Find and in The Circuit ShownVictoria MooreОценок пока нет
- Circuits Quiz 2 SolutionДокумент1 страницаCircuits Quiz 2 SolutionVictoria MooreОценок пока нет
- Simulation: Key QuestionsДокумент38 страницSimulation: Key QuestionsVictoria MooreОценок пока нет
- Circuits S03test1solutionsДокумент4 страницыCircuits S03test1solutionsVictoria MooreОценок пока нет
- One Page of Notes, Front and Back. Closed Book. 50 MinutesДокумент5 страницOne Page of Notes, Front and Back. Closed Book. 50 MinutesVictoria MooreОценок пока нет
- Circuits Quiz 1 SolutionДокумент2 страницыCircuits Quiz 1 SolutionVictoria MooreОценок пока нет
- Arena Simulation Information Different Book - 7Документ55 страницArena Simulation Information Different Book - 7Victoria MooreОценок пока нет
- Circuits HW9solnsДокумент3 страницыCircuits HW9solnsVictoria MooreОценок пока нет
- HW #2 Solutions E245B: Problem 2.10Документ4 страницыHW #2 Solutions E245B: Problem 2.10Victoria MooreОценок пока нет
- Circuits FormulaSheetДокумент1 страницаCircuits FormulaSheetVictoria MooreОценок пока нет
- Signals and Systems SyllabusДокумент3 страницыSignals and Systems SyllabusSeema P DiwanОценок пока нет
- MATH 219: Fall 2014Документ4 страницыMATH 219: Fall 2014Serdar BilgeОценок пока нет
- Naval Research Laboratory Washington, DC 20375-5320 Nrl/Mr/6410!93!7192Документ134 страницыNaval Research Laboratory Washington, DC 20375-5320 Nrl/Mr/6410!93!7192oldakiОценок пока нет
- Complementary Angles: Maths in FocusДокумент2 страницыComplementary Angles: Maths in FocussОценок пока нет
- Lab 3Документ3 страницыLab 3Nutankumar KMОценок пока нет
- 1 Big-O Notation: Plots: 1.1 DefinitionsДокумент16 страниц1 Big-O Notation: Plots: 1.1 DefinitionsTignangshu ChatterjeeОценок пока нет
- Linear Span: From ImportДокумент4 страницыLinear Span: From ImportVINAY BHARADWAJ DS 2147326Оценок пока нет
- Lawvere, Cohesive ToposesДокумент11 страницLawvere, Cohesive Toposesflores3831_814460512100% (1)
- Finding Missing Sides and Angles Using SOHCAHTOAДокумент14 страницFinding Missing Sides and Angles Using SOHCAHTOAFranca OkechukwuОценок пока нет
- Trace Formulae of Characteristic Polynomial and Cayley-Hamilton's Theorem, and Applications To Chiral Perturbation Theory and General RelativityДокумент10 страницTrace Formulae of Characteristic Polynomial and Cayley-Hamilton's Theorem, and Applications To Chiral Perturbation Theory and General RelativityAs AshiffuОценок пока нет
- ML Aggarwal Dec2020 Solutions Class 10 Maths Chapter 4Документ17 страницML Aggarwal Dec2020 Solutions Class 10 Maths Chapter 4evilteam600Оценок пока нет
- 3 1BasicMathДокумент43 страницы3 1BasicMathAliОценок пока нет
- Most Important Simplification Tricks and Techniques For IBPS ExamsДокумент10 страницMost Important Simplification Tricks and Techniques For IBPS ExamsJanardhan ChОценок пока нет
- Mathematical Functions in CДокумент31 страницаMathematical Functions in CLEESHMAОценок пока нет
- Calculus I - L'Hospital's Rule and Indeterminate FormsДокумент7 страницCalculus I - L'Hospital's Rule and Indeterminate FormsAdemolaОценок пока нет
- Nonlinear Analysis of Cable Structures by PDFДокумент7 страницNonlinear Analysis of Cable Structures by PDFmorteza90Оценок пока нет
- Math10 q1 Mod3of8 Illustrate-A-geometric-sequence v2Документ27 страницMath10 q1 Mod3of8 Illustrate-A-geometric-sequence v2Guada Guan FabioОценок пока нет
- Lect 12 - 13 - Velocity Distributions - More Independent VariablesДокумент10 страницLect 12 - 13 - Velocity Distributions - More Independent VariablesSatyajit SamalОценок пока нет
- Linear Programming: Sensitivity Analysis and Interpretation of SolutionДокумент56 страницLinear Programming: Sensitivity Analysis and Interpretation of Solutionjony96100% (1)
- 3-Linear OptimizationДокумент31 страница3-Linear OptimizationJas MinОценок пока нет
- MAT Trigonometry PracticeДокумент3 страницыMAT Trigonometry PracticeSanil KatulaОценок пока нет
- 01a 4MB1 Paper 1 - January 2019Документ24 страницы01a 4MB1 Paper 1 - January 2019Mehwish Arif100% (1)
- MA Sample PaperДокумент7 страницMA Sample Paperdummymailfor1dayОценок пока нет
- Low-PAPR OFDM Waveform Design For Radar and Communication SystemsДокумент6 страницLow-PAPR OFDM Waveform Design For Radar and Communication Systemssharmaald901Оценок пока нет
- EED364: Grpah Signal Processing: ObjectiveДокумент10 страницEED364: Grpah Signal Processing: ObjectivesagrvОценок пока нет
- Bian - Deep Learning On Smooth ManifoldsДокумент6 страницBian - Deep Learning On Smooth ManifoldsmattОценок пока нет
- Lyapunov StabilityДокумент16 страницLyapunov StabilitySukhbir DhillonОценок пока нет
- 1.1b Complex - Analysis DV Eisma PHD Math EdДокумент30 страниц1.1b Complex - Analysis DV Eisma PHD Math EdMark ValdezОценок пока нет
- UNit 2-Prob Dist-DiscreteДокумент5 страницUNit 2-Prob Dist-DiscreteS SОценок пока нет
- How to Improve English Speaking: How to Become a Confident and Fluent English SpeakerОт EverandHow to Improve English Speaking: How to Become a Confident and Fluent English SpeakerРейтинг: 4.5 из 5 звезд4.5/5 (56)
- Weapons of Mass Instruction: A Schoolteacher's Journey Through the Dark World of Compulsory SchoolingОт EverandWeapons of Mass Instruction: A Schoolteacher's Journey Through the Dark World of Compulsory SchoolingРейтинг: 4.5 из 5 звезд4.5/5 (149)
- The 16 Undeniable Laws of Communication: Apply Them and Make the Most of Your MessageОт EverandThe 16 Undeniable Laws of Communication: Apply Them and Make the Most of Your MessageРейтинг: 5 из 5 звезд5/5 (73)
- How to Talk to Anyone: Learn the Secrets of Good Communication and the Little Tricks for Big Success in RelationshipОт EverandHow to Talk to Anyone: Learn the Secrets of Good Communication and the Little Tricks for Big Success in RelationshipРейтинг: 4.5 из 5 звезд4.5/5 (1135)
- Dumbing Us Down: The Hidden Curriculum of Compulsory SchoolingОт EverandDumbing Us Down: The Hidden Curriculum of Compulsory SchoolingРейтинг: 4.5 из 5 звезд4.5/5 (496)
- Summary: The Laws of Human Nature: by Robert Greene: Key Takeaways, Summary & AnalysisОт EverandSummary: The Laws of Human Nature: by Robert Greene: Key Takeaways, Summary & AnalysisРейтинг: 4.5 из 5 звезд4.5/5 (30)
- Summary: Greenlights: by Matthew McConaughey: Key Takeaways, Summary & AnalysisОт EverandSummary: Greenlights: by Matthew McConaughey: Key Takeaways, Summary & AnalysisРейтинг: 4 из 5 звезд4/5 (6)
- Summary: I'm Glad My Mom Died: by Jennette McCurdy: Key Takeaways, Summary & AnalysisОт EverandSummary: I'm Glad My Mom Died: by Jennette McCurdy: Key Takeaways, Summary & AnalysisРейтинг: 4.5 из 5 звезд4.5/5 (2)
- Summary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisОт EverandSummary: The 5AM Club: Own Your Morning. Elevate Your Life. by Robin Sharma: Key Takeaways, Summary & AnalysisРейтинг: 4.5 из 5 звезд4.5/5 (22)
- Stoicism The Art of Happiness: How the Stoic Philosophy Works, Living a Good Life, Finding Calm and Managing Your Emotions in a Turbulent World. New VersionОт EverandStoicism The Art of Happiness: How the Stoic Philosophy Works, Living a Good Life, Finding Calm and Managing Your Emotions in a Turbulent World. New VersionРейтинг: 5 из 5 звезд5/5 (51)
- Summary: Trading in the Zone: Trading in the Zone: Master the Market with Confidence, Discipline, and a Winning Attitude by Mark Douglas: Key Takeaways, Summary & AnalysisОт EverandSummary: Trading in the Zone: Trading in the Zone: Master the Market with Confidence, Discipline, and a Winning Attitude by Mark Douglas: Key Takeaways, Summary & AnalysisРейтинг: 5 из 5 звезд5/5 (15)
- Summary: It Didn't Start with You: How Inherited Family Trauma Shapes Who We Are and How to End the Cycle By Mark Wolynn: Key Takeaways, Summary & AnalysisОт EverandSummary: It Didn't Start with You: How Inherited Family Trauma Shapes Who We Are and How to End the Cycle By Mark Wolynn: Key Takeaways, Summary & AnalysisРейтинг: 5 из 5 звезд5/5 (3)
- Why Smart People Hurt: A Guide for the Bright, the Sensitive, and the CreativeОт EverandWhy Smart People Hurt: A Guide for the Bright, the Sensitive, and the CreativeРейтинг: 3.5 из 5 звезд3.5/5 (54)
- Summary of The Power of Habit: Why We Do What We Do in Life and Business by Charles DuhiggОт EverandSummary of The Power of Habit: Why We Do What We Do in Life and Business by Charles DuhiggРейтинг: 4.5 из 5 звезд4.5/5 (261)
- Summary: 12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure Entrepreneur by Ryan Daniel Moran: Key Takeaways, Summary & AnalysisОт EverandSummary: 12 Months to $1 Million: How to Pick a Winning Product, Build a Real Business, and Become a Seven-Figure Entrepreneur by Ryan Daniel Moran: Key Takeaways, Summary & AnalysisРейтинг: 5 из 5 звезд5/5 (2)
- Follow The Leader: A Collection Of The Best Lectures On LeadershipОт EverandFollow The Leader: A Collection Of The Best Lectures On LeadershipРейтинг: 5 из 5 звезд5/5 (122)
- Learn French: The Essentials You Need to Go From an Absolute Beginner to Intermediate and AdvancedОт EverandLearn French: The Essentials You Need to Go From an Absolute Beginner to Intermediate and AdvancedОценок пока нет
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindОт EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindОценок пока нет
- Make It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningОт EverandMake It Stick by Peter C. Brown, Henry L. Roediger III, Mark A. McDaniel - Book Summary: The Science of Successful LearningРейтинг: 4.5 из 5 звезд4.5/5 (55)
- You Are Not Special: And Other EncouragementsОт EverandYou Are Not Special: And Other EncouragementsРейтинг: 4.5 из 5 звезд4.5/5 (6)
- Grit: The Power of Passion and PerseveranceОт EverandGrit: The Power of Passion and PerseveranceРейтинг: 4.5 из 5 звезд4.5/5 (1873)