Вам также может понравиться
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Bill Paying WorksheetДокумент1 страницаBill Paying WorksheetDenis SherОценок пока нет
- Re-Negotiating Czechoslovakia. The State and The Jews in Communis PDFДокумент689 страницRe-Negotiating Czechoslovakia. The State and The Jews in Communis PDFDenis SherОценок пока нет
- Restitution of Jewish Property in The Czech RepublicДокумент25 страницRestitution of Jewish Property in The Czech RepublicDenis SherОценок пока нет
- Re-Negotiating Czechoslovakia. The State and The Jews in Communis PDFДокумент689 страницRe-Negotiating Czechoslovakia. The State and The Jews in Communis PDFDenis SherОценок пока нет
- Flash On English For Tourism - Answer Key and Transcripts: Unit 1, Pp. 4-7Документ15 страницFlash On English For Tourism - Answer Key and Transcripts: Unit 1, Pp. 4-7phuongang252006100% (1)
- PMP Memory Sheets PDFДокумент9 страницPMP Memory Sheets PDFDenis SherОценок пока нет
- Genre: - Locations For Characters in Action - Scenery: Lyrical / Fantastic / SymbolicДокумент2 страницыGenre: - Locations For Characters in Action - Scenery: Lyrical / Fantastic / SymbolicDenis SherОценок пока нет
- The G. Gatsby Review. Book Vs MovieДокумент7 страницThe G. Gatsby Review. Book Vs MovieDenis SherОценок пока нет
- Pride and Prejudice AnalysisДокумент5 страницPride and Prejudice AnalysisDenis Sher100% (1)
- Plot SummariesДокумент1 страницаPlot SummariesDenis SherОценок пока нет
- Test Assessing A Language LevelДокумент15 страницTest Assessing A Language LevelDenis SherОценок пока нет
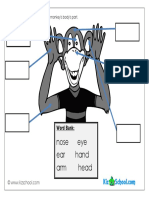
- BodyParts - Label Face PDFДокумент1 страницаBodyParts - Label Face PDFDenis SherОценок пока нет
- Bibliography. QuestionnairesДокумент44 страницыBibliography. QuestionnairesDenis SherОценок пока нет
- Andrews M. Evaluating The Contribution of Intra-Linguistic and Extra-LinguisticДокумент6 страницAndrews M. Evaluating The Contribution of Intra-Linguistic and Extra-LinguisticDenis SherОценок пока нет
- Andrews M. Evaluating The Contribution of Intra-Linguistic and Extra-LinguisticДокумент6 страницAndrews M. Evaluating The Contribution of Intra-Linguistic and Extra-LinguisticDenis SherОценок пока нет
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- (Language, Discourse, Society) Ian Hunter, David Saunders, Dugald Williamson (Auth.) - On Pornography - Literature, Sexuality and Obscenity Law-Palgrave Macmillan UK (1993) PDFДокумент302 страницы(Language, Discourse, Society) Ian Hunter, David Saunders, Dugald Williamson (Auth.) - On Pornography - Literature, Sexuality and Obscenity Law-Palgrave Macmillan UK (1993) PDFnaciye tasdelenОценок пока нет
- Vb-Mapp Transition Scoring FormДокумент1 страницаVb-Mapp Transition Scoring FormEstima CGОценок пока нет
- BCBA BCaBA Task List 5th Ed PDFДокумент5 страницBCBA BCaBA Task List 5th Ed PDFMaria PascuОценок пока нет
- 1984 Shimp Consumer Ethnocentrism The Concept and A Preliminary Empirical TestДокумент7 страниц1984 Shimp Consumer Ethnocentrism The Concept and A Preliminary Empirical Testhchmelo100% (2)
- Quantitative Annotated BibliographyДокумент2 страницыQuantitative Annotated Bibliographyapi-310552722Оценок пока нет
- Expressing OpinionsДокумент8 страницExpressing OpinionsYulia Rizki Damanik0% (1)
- Human Resource Management 15Th Edition Dessler Solutions Manual Full Chapter PDFДокумент35 страницHuman Resource Management 15Th Edition Dessler Solutions Manual Full Chapter PDFEricHowardftzs100% (7)
- (Pocket Guide To Social Work Research Methods) James Drisko, Tina Maschi - Content Analysis (2015, Oxford University Press) PDFДокумент209 страниц(Pocket Guide To Social Work Research Methods) James Drisko, Tina Maschi - Content Analysis (2015, Oxford University Press) PDFCarolina Bagattolli100% (2)
- 123 Magic Parent Brochure FinalДокумент2 страницы123 Magic Parent Brochure Finalapi-293836948Оценок пока нет
- Introduction: A Practical Guide For ReadingДокумент31 страницаIntroduction: A Practical Guide For ReadingMarbie Joyce Aspe100% (1)
- Operations StrategyДокумент41 страницаOperations StrategyClarisse Mendoza100% (1)
- PerDev Q1 Module-30-31Документ30 страницPerDev Q1 Module-30-31Kurt RempilloОценок пока нет
- Phonemic Awareness and The Teaching of ReadingДокумент10 страницPhonemic Awareness and The Teaching of ReadingDavid Woo100% (2)
- Family Style Meal ServiceДокумент1 страницаFamily Style Meal ServiceOsama AbdulganiОценок пока нет
- Marxism and Literary Criticism PDFДокумент11 страницMarxism and Literary Criticism PDFUfaque PaikerОценок пока нет
- Anecdotal Record PDFДокумент3 страницыAnecdotal Record PDFRycel Mae dela TorreОценок пока нет
- Peta MindaДокумент9 страницPeta Mindalccjane8504Оценок пока нет
- Carretero Haste Bermudez 2016 Civic Education - Handbook of Educational Psychology Ch-22Документ15 страницCarretero Haste Bermudez 2016 Civic Education - Handbook of Educational Psychology Ch-22Chanda KaminsaОценок пока нет
- Group6 Bsrt1eДокумент16 страницGroup6 Bsrt1e9z4h9hj7knОценок пока нет
- ACR PDF Legal SizeДокумент2 страницыACR PDF Legal SizeSAYAN BHATTAОценок пока нет
- Njau - Challenges Facing Human Resource Management Function at Kenyatta National HospitalДокумент64 страницыNjau - Challenges Facing Human Resource Management Function at Kenyatta National HospitalAdrahОценок пока нет
- Artifact 6 STD 9 - Pre-Student Teaching PortfolioДокумент2 страницыArtifact 6 STD 9 - Pre-Student Teaching Portfolioapi-240921658Оценок пока нет
- College English and Business Communication 10th Edition by Camp Satterwhite ISBN Test BankДокумент55 страницCollege English and Business Communication 10th Edition by Camp Satterwhite ISBN Test Bankgladys100% (20)
- Fernandez. (2016) - Past Present and Future of Neuropsychology in ArgentinaДокумент26 страницFernandez. (2016) - Past Present and Future of Neuropsychology in ArgentinaFernandoОценок пока нет
- English Second Grade - Didactic Sequence 2 - Term 1Документ17 страницEnglish Second Grade - Didactic Sequence 2 - Term 1Natalia Zapata CuartasОценок пока нет
- Great Barrier Reef Educator GuideДокумент24 страницыGreat Barrier Reef Educator GuideLendry NormanОценок пока нет
- Art Direction Mood BoardДокумент13 страницArt Direction Mood BoardBE-K.Оценок пока нет
- Unang Arifin,+1598 Siska+Febriyani+97-104Документ8 страницUnang Arifin,+1598 Siska+Febriyani+97-1044491 Tarisa Veronika PutriОценок пока нет
- Language (50 Marks) 21 - 25 16 - 20 11 - 15 6 - 10 1 - 5: Revised Written Report Scoring RubricДокумент3 страницыLanguage (50 Marks) 21 - 25 16 - 20 11 - 15 6 - 10 1 - 5: Revised Written Report Scoring Rubricsilent spritsОценок пока нет
- God, Abraham, and The Abuse of Isaac: Erence RetheimДокумент9 страницGod, Abraham, and The Abuse of Isaac: Erence RetheimIuanОценок пока нет