Вам также может понравиться
- Machine Learning AssignmentsДокумент3 страницыMachine Learning AssignmentsUjesh MauryaОценок пока нет
- Quizz SolutionДокумент10 страницQuizz SolutionPhuc SJОценок пока нет
- Fuzzy ModelingДокумент65 страницFuzzy ModelingAbouzar SekhavatiОценок пока нет
- 201041Документ15 страниц201041Kimeu EstherОценок пока нет
- Application of Back-Propagation Neural Network in Data ForecastДокумент23 страницыApplication of Back-Propagation Neural Network in Data ForecastEngineeringОценок пока нет
- Exercise 7 Submission Group 12Документ22 страницыExercise 7 Submission Group 12Mehmet YalçınОценок пока нет
- Dimension ReductionДокумент15 страницDimension ReductionShreyas VaradkarОценок пока нет
- Mandatory - Exercise 2Документ11 страницMandatory - Exercise 2redalert4ever4Оценок пока нет
- LP1 1Документ129 страницLP1 1Sagar KhodeОценок пока нет
- Cs3491-Ai&ml Lab Manual EceДокумент42 страницыCs3491-Ai&ml Lab Manual EceabiraminitcseОценок пока нет
- ANN7Документ15 страницANN7ARPIT SANJAY AVASARMOL R2566003Оценок пока нет
- Clustering (Unit 3)Документ71 страницаClustering (Unit 3)vedang maheshwari100% (1)
- Arpan ML 2.1Документ8 страницArpan ML 2.1Harwinder KaurОценок пока нет
- CSL0777 L26Документ33 страницыCSL0777 L26Konkobo Ulrich ArthurОценок пока нет
- Course Code::: Neural Network and Fuzzy Logics ECE3008Документ11 страницCourse Code::: Neural Network and Fuzzy Logics ECE3008sankeerthОценок пока нет
- Software Process and RequirementДокумент25 страницSoftware Process and RequirementUnicorn54Оценок пока нет
- Title: Implement Support Vector Machine Classifier: Department of Computer Science and EngineeringДокумент5 страницTitle: Implement Support Vector Machine Classifier: Department of Computer Science and EngineeringreilyshawnОценок пока нет
- Chap 6 EmbeddingДокумент44 страницыChap 6 EmbeddingHRITWIK GHOSHОценок пока нет
- 21MCI1126 - Nikhil - Raj 2.2Документ9 страниц21MCI1126 - Nikhil - Raj 2.2nikhilsinghraj11Оценок пока нет
- MODULE 2 Deep LearningДокумент26 страницMODULE 2 Deep LearningENG20DS0040 SukruthaGОценок пока нет
- AgnivaДокумент16 страницAgnivalernerquickОценок пока нет
- 30 Assignments PDFДокумент5 страниц30 Assignments PDFAgent SharonОценок пока нет
- Intro 2 NetlabДокумент10 страницIntro 2 NetlabBhaumik BhuvaОценок пока нет
- Machine Learning NotesДокумент6 страницMachine Learning NotesNikhita NairОценок пока нет
- 17IT8029Документ7 страниц17IT8029AlexОценок пока нет
- MLOPS Summary Every DayДокумент23 страницыMLOPS Summary Every DayvineethОценок пока нет
- DNN ALL Practical 28Документ34 страницыDNN ALL Practical 284073Himanshu PatleОценок пока нет
- Computer GraphisДокумент7 страницComputer GraphisAlbin Ps PlappallilОценок пока нет
- Ch02 Primitive Data Definite LoopsДокумент76 страницCh02 Primitive Data Definite LoopsNiranchandraVunnamОценок пока нет
- Asn HS07Документ6 страницAsn HS07saravanan_nallusamyОценок пока нет
- Optimization Presentation 2015Документ80 страницOptimization Presentation 2015fnagiОценок пока нет
- ML QB SolutionssДокумент16 страницML QB SolutionssKunj TrivediОценок пока нет
- Metode Data Mining SomДокумент22 страницыMetode Data Mining SomAnonymous N22g3i4Оценок пока нет
- Soft Computing 0105IT171089Документ17 страницSoft Computing 0105IT171089OMSAINATH MPONLINEОценок пока нет
- Printed and Handwritten Digits Recognition Using Neural NetworksДокумент5 страницPrinted and Handwritten Digits Recognition Using Neural NetworksParshu RamОценок пока нет
- Neural Networks and Deep Learning PracticalДокумент15 страницNeural Networks and Deep Learning PracticalMs.R.KalaiyarasiОценок пока нет
- Mandelbrot Zoom ReportДокумент9 страницMandelbrot Zoom ReportmorrisblausteinОценок пока нет
- Neural Networks - Basics Matlab PDFДокумент59 страницNeural Networks - Basics Matlab PDFWesley DoorsamyОценок пока нет
- DWM Experiment5 E059Документ15 страницDWM Experiment5 E059Shubham GuptaОценок пока нет
- AI-based Chatbot For Skin Disease Prediction Using CNN and ID3 Decision TreeДокумент46 страницAI-based Chatbot For Skin Disease Prediction Using CNN and ID3 Decision TreeChumma SpamОценок пока нет
- MPI The Best Possible PractiseДокумент5 страницMPI The Best Possible Practisekam_anwОценок пока нет
- AmmmathalliДокумент83 страницыAmmmathalliThota sivasriОценок пока нет
- Numerical Libraries For Petascale Computing: Brett Bode William GroppДокумент34 страницыNumerical Libraries For Petascale Computing: Brett Bode William GroppPeng XuОценок пока нет
- Experiment 1Документ17 страницExperiment 1saeed wedyanОценок пока нет
- Assignment 1Документ3 страницыAssignment 1Muhammad Danish KhanОценок пока нет
- ML 1Документ20 страницML 1Adwait RaichОценок пока нет
- Lecture 7: Software Testing White Box TestingДокумент24 страницыLecture 7: Software Testing White Box TestingOmama MaazОценок пока нет
- Parameter EstimationДокумент24 страницыParameter EstimationMina Arya100% (1)
- 82.2.-TopoShaper - Isocontour APIДокумент4 страницы82.2.-TopoShaper - Isocontour APIGrupo ByrОценок пока нет
- Homework 1Документ2 страницыHomework 1Hendra LimОценок пока нет
- Matlab - Khushal VermaДокумент38 страницMatlab - Khushal VermaANNANYA BADARYAОценок пока нет
- Lab Manual - AETN2302 - L2 (Lirterals and Variables)Документ7 страницLab Manual - AETN2302 - L2 (Lirterals and Variables)Zille HumaОценок пока нет
- Assignment PDFДокумент5 страницAssignment PDFSaurabh Raghuvanshi0% (1)
- Integer Optimization and its Computation in Emergency ManagementОт EverandInteger Optimization and its Computation in Emergency ManagementОценок пока нет
- DEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABОт EverandDEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABОценок пока нет
- DATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSОт EverandDATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSОценок пока нет
- Group Method of Data Handling: Fundamentals and Applications for Predictive Modeling and Data AnalysisОт EverandGroup Method of Data Handling: Fundamentals and Applications for Predictive Modeling and Data AnalysisОценок пока нет
- Line Drawing Algorithm: Mastering Techniques for Precision Image RenderingОт EverandLine Drawing Algorithm: Mastering Techniques for Precision Image RenderingОценок пока нет
- Multiple Models Approach in Automation: Takagi-Sugeno Fuzzy SystemsОт EverandMultiple Models Approach in Automation: Takagi-Sugeno Fuzzy SystemsОценок пока нет
- Literature SurveyДокумент6 страницLiterature SurveyPhuc SJОценок пока нет
- A Review On The Role of Machine Learning in Agriculture: AbstractДокумент8 страницA Review On The Role of Machine Learning in Agriculture: AbstractPhuc SJОценок пока нет
- Application of Artificial Intelligence in Indian AgricultureДокумент10 страницApplication of Artificial Intelligence in Indian AgriculturePhuc SJОценок пока нет
- MATH324 Syllabus and Schedule, 2011-2012 Class: 09ECE: Danang University of TechnologyДокумент2 страницыMATH324 Syllabus and Schedule, 2011-2012 Class: 09ECE: Danang University of TechnologyPhuc SJОценок пока нет
- Report Lab 1Документ29 страницReport Lab 1Phuc SJОценок пока нет
- HCDE333 Peer Review ProposalДокумент2 страницыHCDE333 Peer Review ProposalPhuc SJОценок пока нет
- "Baby Desktop Farmer" Desktop Controlled Growth Chamber EE/AA 449 Final ReportДокумент10 страниц"Baby Desktop Farmer" Desktop Controlled Growth Chamber EE/AA 449 Final ReportPhuc SJОценок пока нет
- A Fingerprint Recognition Algorithm Combining Phase-Based Image Matching and Feature-Based MatchingДокумент10 страницA Fingerprint Recognition Algorithm Combining Phase-Based Image Matching and Feature-Based MatchingPhuc SJОценок пока нет
- HCDE333 Elevator Pitch AssignmentДокумент2 страницыHCDE333 Elevator Pitch AssignmentPhuc SJОценок пока нет
- ECON200 Chapter15Документ48 страницECON200 Chapter15Phuc SJОценок пока нет
- Verilog Overview - The Verilog Hardware Description LanguageДокумент41 страницаVerilog Overview - The Verilog Hardware Description LanguagePhuc SJОценок пока нет
- Machine Learning QuestionsДокумент13 страницMachine Learning QuestionsAnwarul Bashir ShuaibОценок пока нет
- Resume AmazonДокумент3 страницыResume Amazonrawdy babyОценок пока нет
- Lec 01Документ31 страницаLec 01indrahermawanОценок пока нет
- Somerford Splunk IT Service Intelligence Workshop WorkbookДокумент131 страницаSomerford Splunk IT Service Intelligence Workshop WorkbookAbdourahmane thiawОценок пока нет
- Kernel Methods: Feature Mapping at No CostДокумент25 страницKernel Methods: Feature Mapping at No CostPooja PatwariОценок пока нет
- Real FinalДокумент32 страницыReal Finalbigmeeru80Оценок пока нет
- How To Derive Errors in Neural Network With The Backpropagation Algorithm?Документ7 страницHow To Derive Errors in Neural Network With The Backpropagation Algorithm?Андрей МаляренкоОценок пока нет
- Lecture 2 Autoregressive ModelsДокумент113 страницLecture 2 Autoregressive Modelsalbertoluin10Оценок пока нет
- Machine Learning and Structural Health Monitoring Overview With Emerging Technology and High-Dimensional Data Source HighlightsДокумент50 страницMachine Learning and Structural Health Monitoring Overview With Emerging Technology and High-Dimensional Data Source Highlightsbrettharvey555Оценок пока нет
- Naive Bayes Classifier in Machine Learning - JavatpointДокумент19 страницNaive Bayes Classifier in Machine Learning - Javatpointmangotwin22Оценок пока нет
- Machine Learning Algorithm For Financial Fruad DetectionДокумент25 страницMachine Learning Algorithm For Financial Fruad DetectionJOHN ETSUОценок пока нет
- Topic 6a - Introduction To ClusteringДокумент11 страницTopic 6a - Introduction To ClusteringNurizzati Md NizamОценок пока нет
- Artificial Intelligence and Machine Learning in Satellite CommunicationДокумент13 страницArtificial Intelligence and Machine Learning in Satellite CommunicationSalahuddinKhanОценок пока нет
- Top Links August 2019Документ292 страницыTop Links August 2019Andrew Richard ThompsonОценок пока нет
- JUPIMAN+-+Vol 2,+no 4+desember+2023+hal+108-123Документ16 страницJUPIMAN+-+Vol 2,+no 4+desember+2023+hal+108-123Alamria PramanaОценок пока нет
- Chatbor Report (Covid19)Документ19 страницChatbor Report (Covid19)RaglandОценок пока нет
- Código K-Means en SpyderДокумент3 страницыCódigo K-Means en SpyderManuel Calva ZОценок пока нет
- CSC3200 Lecture 1Документ18 страницCSC3200 Lecture 1palden khambaОценок пока нет
- Supervised Learning: Adane Letta Mamuye (PHD)Документ41 страницаSupervised Learning: Adane Letta Mamuye (PHD)ABDULHAMIDОценок пока нет
- Convolutional Neural Network For Image RecognitionДокумент8 страницConvolutional Neural Network For Image RecognitionIJRASETPublicationsОценок пока нет
- NLP Quick NOtesДокумент15 страницNLP Quick NOtesAshutosh Kumar ShahiОценок пока нет
- Minggu04 - Convolutional Neural Network (CNN)Документ55 страницMinggu04 - Convolutional Neural Network (CNN)Terves AlexanderОценок пока нет
- TSP Cmes 43921Документ34 страницыTSP Cmes 43921digicommagencyОценок пока нет
- Stay Current On Your Favorite Topics: Revolutionizing Indi-Rect Procurement For The 2020sДокумент1 страницаStay Current On Your Favorite Topics: Revolutionizing Indi-Rect Procurement For The 2020sNavdeep ChahalОценок пока нет
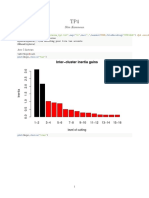
- Inter Cluster Inertia Gains: Slim KammounДокумент13 страницInter Cluster Inertia Gains: Slim KammounJames OptimisteОценок пока нет
- AI ConferenceДокумент250 страницAI ConferenceramapvkОценок пока нет
- Ijtpp 07 00020Документ19 страницIjtpp 07 00020Tuan AnhОценок пока нет
- DL Slides 2Документ162 страницыDL Slides 2ABI RAJESH GANESHA RAJAОценок пока нет
- Artificial Intelligence in 5GДокумент34 страницыArtificial Intelligence in 5GSakhawat Ali SahgalОценок пока нет
- Plant Disease Detection Using Drones in PrecisionДокумент21 страницаPlant Disease Detection Using Drones in PrecisionSandeep GaikwadОценок пока нет