Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- UntitledДокумент37 страницUntitledUnknown UserОценок пока нет
- John Hopkins Evidence Table - Systematic ReviewДокумент2 страницыJohn Hopkins Evidence Table - Systematic Reviewsandy ThylsОценок пока нет
- MT4400 STRG Flo Amp ValveДокумент7 страницMT4400 STRG Flo Amp ValveBrian Careel0% (1)
- H&M Case Study AssignmentДокумент7 страницH&M Case Study AssignmentwqvyakОценок пока нет
- Centralized PurchasingДокумент2 страницыCentralized PurchasingbiyyamobulreddyОценок пока нет
- Pearson Letter To ParentsДокумент2 страницыPearson Letter To ParentsPatricia WillensОценок пока нет
- Effect of Liquidity Risk On Performance of Deposit Money Banks in NigeriaДокумент6 страницEffect of Liquidity Risk On Performance of Deposit Money Banks in NigeriaEditor IJTSRDОценок пока нет
- Avinash Uttareshwar MeherДокумент6 страницAvinash Uttareshwar MeheravinashОценок пока нет
- Himachal Pradesh Staff Selection Commission Hamirpur - 177001Документ2 страницыHimachal Pradesh Staff Selection Commission Hamirpur - 177001Verma JagdeepОценок пока нет
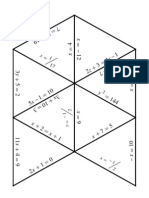
- Algebra1 Review PuzzleДокумент3 страницыAlgebra1 Review PuzzleNicholas Yates100% (1)
- Research 9: Activity 4: Background of The StudyДокумент7 страницResearch 9: Activity 4: Background of The StudyPhilip AmelingОценок пока нет
- Secondary GeographyДокумент127 страницSecondary GeographyAbcdОценок пока нет
- Assignment 2 Grammar Lesson PlanДокумент26 страницAssignment 2 Grammar Lesson PlanKesia Kerspay100% (1)
- HVS Hotel Cost Estimating Guide 2021Документ124 страницыHVS Hotel Cost Estimating Guide 2021pascal rosasОценок пока нет
- ENGLISH TOEFL Structure (3rd Exercise)Документ5 страницENGLISH TOEFL Structure (3rd Exercise)susannnnnnОценок пока нет
- Chapter 1 MPLS OAM Configuration Commands ...................................................................... 1-1Документ27 страницChapter 1 MPLS OAM Configuration Commands ...................................................................... 1-1Randy DookheranОценок пока нет
- Basic Program Structure in C++: Study Guide For Module No. 2Документ9 страницBasic Program Structure in C++: Study Guide For Module No. 2Ji YoungОценок пока нет
- Systematic Literature Review SvenskaДокумент6 страницSystematic Literature Review Svenskafihum1hadej2100% (1)
- 02.certificate of Compliance FM UkДокумент10 страниц02.certificate of Compliance FM Ukmyatthura870Оценок пока нет
- Catalogo Perylsa CompletoДокумент221 страницаCatalogo Perylsa CompletoAlvaro Diaz0% (1)
- Permeability Estimation PDFДокумент10 страницPermeability Estimation PDFEdison Javier Acevedo ArismendiОценок пока нет
- IES 2001 - I ScanДокумент20 страницIES 2001 - I ScanK.v.SinghОценок пока нет
- Engine Torque Settings and Spec's 3.0L V6 SCДокумент4 страницыEngine Torque Settings and Spec's 3.0L V6 SCMario MaravillaОценок пока нет
- Anatomy & Physiology MCQsДокумент26 страницAnatomy & Physiology MCQsMuskan warisОценок пока нет
- Bhaktavatsalam Memorial College For Women: Hand Book 2020 - 21Документ37 страницBhaktavatsalam Memorial College For Women: Hand Book 2020 - 21Anu RsОценок пока нет
- Revised Research ZoomДокумент51 страницаRevised Research ZoomAubrey Unique EvangelistaОценок пока нет
- Researchpaper Should Removable Media Be Encrypted - PDF - ReportДокумент15 страницResearchpaper Should Removable Media Be Encrypted - PDF - ReportSakshi Dhananjay KambleОценок пока нет
- Term Test Pointers For Review - 1st TermДокумент2 страницыTerm Test Pointers For Review - 1st Termjessica holgadoОценок пока нет
- Analisa AgriculturalДокумент6 страницAnalisa AgriculturalFEBRINA SARLINDA, STОценок пока нет