Вам также может понравиться
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
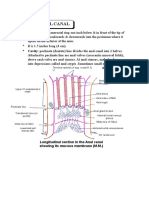
- Anatomy Anal CanalДокумент14 страницAnatomy Anal CanalBela Ronaldoe100% (1)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Pt3 English Module 2018Документ63 страницыPt3 English Module 2018Annie Abdul Rahman50% (4)
- (123doc) - Toefl-Reading-Comprehension-Test-41Документ8 страниц(123doc) - Toefl-Reading-Comprehension-Test-41Steve XОценок пока нет
- DQ Vibro SifterДокумент13 страницDQ Vibro SifterDhaval Chapla67% (3)
- Project - New Restuarant Management System The Grill HouseДокумент24 страницыProject - New Restuarant Management System The Grill HouseMayank Mahajan100% (3)
- Mark Garside Resume May 2014Документ3 страницыMark Garside Resume May 2014api-199955558Оценок пока нет
- WebLMT HelpДокумент12 страницWebLMT HelpJoão LopesОценок пока нет
- Unit 7: Anthropology: Q2e Listening & Speaking 4: Audio ScriptДокумент6 страницUnit 7: Anthropology: Q2e Listening & Speaking 4: Audio ScriptĐại học Bạc Liêu Truyền thông100% (1)
- Chapter 23Документ21 страницаChapter 23Amsalu WalelignОценок пока нет
- Payment: USD 2,277.03: Bank DetailsДокумент1 страницаPayment: USD 2,277.03: Bank DetailsAmsalu WalelignОценок пока нет
- NETSANETДокумент1 страницаNETSANETAmsalu WalelignОценок пока нет
- DateДокумент1 страницаDateAmsalu WalelignОценок пока нет
- Simple Linear Regression and Correlation Analysis: Chapter FiveДокумент5 страницSimple Linear Regression and Correlation Analysis: Chapter FiveAmsalu WalelignОценок пока нет
- CH1 2011Документ44 страницыCH1 2011Amsalu WalelignОценок пока нет
- Chapter 15 of GlobeДокумент26 страницChapter 15 of GlobeSyed Zakir Hussain ZaidiОценок пока нет
- Interactive Scatter Plots in SPSSДокумент4 страницыInteractive Scatter Plots in SPSSAmsalu WalelignОценок пока нет
- Need Assessment QuestionnaireДокумент2 страницыNeed Assessment QuestionnaireAmsalu WalelignОценок пока нет
- Population. Usually, We Cannot Ask Everyone in Our Population (Like All ISU Students) So SampleДокумент2 страницыPopulation. Usually, We Cannot Ask Everyone in Our Population (Like All ISU Students) So SampleAmsalu WalelignОценок пока нет
- Generalized Ordered Logit Models: April 2, 2010 Richard Williams, Notre Dame Sociology, Gologit2 Support PageДокумент6 страницGeneralized Ordered Logit Models: April 2, 2010 Richard Williams, Notre Dame Sociology, Gologit2 Support PageAmsalu WalelignОценок пока нет
- STAT10010 Tutorial 5. Week 7Документ1 страницаSTAT10010 Tutorial 5. Week 7Amsalu WalelignОценок пока нет
- Using Stata 11 & 12 For Logistic RegressionДокумент13 страницUsing Stata 11 & 12 For Logistic RegressionAmsalu WalelignОценок пока нет
- IOE 265 Probability and Statistics For Engineers - Winter 2004 Section 200Документ5 страницIOE 265 Probability and Statistics For Engineers - Winter 2004 Section 200Amsalu WalelignОценок пока нет
- Stat10010 1Документ18 страницStat10010 1Amsalu WalelignОценок пока нет
- Stat 10010 Lab 1Документ5 страницStat 10010 Lab 1Amsalu WalelignОценок пока нет
- CEE 203 SyllabusДокумент3 страницыCEE 203 SyllabusAmsalu WalelignОценок пока нет
- Exporting SPSS Data To ExcelДокумент3 страницыExporting SPSS Data To ExcelAmsalu WalelignОценок пока нет
- High Frequency TradingДокумент4 страницыHigh Frequency TradingAmsalu WalelignОценок пока нет
- Al99 20eДокумент28 страницAl99 20eAmsalu WalelignОценок пока нет
- Wilson IntervalДокумент6 страницWilson IntervalAmsalu WalelignОценок пока нет
- Spring 2013 SEEM 2520 Tutorial 1 An Overview of The Financial SystemДокумент2 страницыSpring 2013 SEEM 2520 Tutorial 1 An Overview of The Financial SystemAmsalu WalelignОценок пока нет
- LM74680 Fasson® Fastrans NG Synthetic PE (ST) / S-2050/ CK40Документ2 страницыLM74680 Fasson® Fastrans NG Synthetic PE (ST) / S-2050/ CK40Nishant JhaОценок пока нет
- Revenue and Expenditure AuditДокумент38 страницRevenue and Expenditure AuditPavitra MohanОценок пока нет
- Chapter 2 ProblemsДокумент6 страницChapter 2 ProblemsYour MaterialsОценок пока нет
- Bana LingaДокумент9 страницBana LingaNimai Pandita Raja DasaОценок пока нет
- WEB DESIGN WITH AUSTINE-converted-1Документ9 страницWEB DESIGN WITH AUSTINE-converted-1JayjayОценок пока нет
- Business Plan 3.3Документ2 страницыBusiness Plan 3.3Rojin TingabngabОценок пока нет
- UC 20 - Produce Cement Concrete CastingДокумент69 страницUC 20 - Produce Cement Concrete Castingtariku kiros100% (2)
- Lesson PlanДокумент2 страницыLesson Plannicole rigonОценок пока нет
- Making Effective Powerpoint Presentations: October 2014Документ18 страницMaking Effective Powerpoint Presentations: October 2014Mariam TchkoidzeОценок пока нет
- Organizational ConflictДокумент22 страницыOrganizational ConflictTannya AlexandraОценок пока нет
- Technology Management 1Документ38 страницTechnology Management 1Anu NileshОценок пока нет
- Dtu Placement BrouchureДокумент25 страницDtu Placement BrouchureAbhishek KumarОценок пока нет
- .Urp 203 Note 2022 - 1642405559000Документ6 страниц.Urp 203 Note 2022 - 1642405559000Farouk SalehОценок пока нет
- DP 2 Human IngenuityДокумент8 страницDP 2 Human Ingenuityamacodoudiouf02Оценок пока нет
- Damodaram Sanjivayya National Law University Visakhapatnam, A.P., IndiaДокумент25 страницDamodaram Sanjivayya National Law University Visakhapatnam, A.P., IndiaSumanth RoxtaОценок пока нет
- 18 June 2020 12:03: New Section 1 Page 1Документ4 страницы18 June 2020 12:03: New Section 1 Page 1KarthikNayakaОценок пока нет
- Work ProblemsДокумент19 страницWork ProblemsOfelia DavidОценок пока нет
- Rule 113 114Документ7 страницRule 113 114Shaila GonzalesОценок пока нет
- Retailing in IndiaДокумент11 страницRetailing in IndiaVinod MalkarОценок пока нет
- Gemini Dollar WhitepaperДокумент7 страницGemini Dollar WhitepaperdazeeeОценок пока нет
- Psychological Contract Rousseau PDFДокумент9 страницPsychological Contract Rousseau PDFSandy KhanОценок пока нет
- Study 107 - The Doctrine of Salvation - Part 8Документ2 страницыStudy 107 - The Doctrine of Salvation - Part 8Jason MyersОценок пока нет