International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
Face Tracking and Robot Shoot
Kulkarni Priyanka R.1, Rane Kantilal P.2
1
PG Student, Department of E&TC, GFs Godavari COE, Jalgaon 2 Asso. Prof., Department of E&TC, GFs Godavari CoE, Jalgaon
Abstract
Adaboost has been widely used to improve the accuracy of any given learning algorithm. Here we focus on designing an algorithm to employ combination of Adaboost with Support Vector Machine (SVM) as weak component classifiers to be used in Face Detection Task. To obtain a set of effective SVM-weaklearner Classifier, this algorithm adaptively adjusts the kernel parameter in SVM instead of using a fixed one. Proposed combination outperforms in generalization in comparison with SVM on imbalanced classification problem. The proposed here method is compared, in terms of classification accuracy, to other commonly used Adaboost methods, such as Decision Trees and Neural Networks, on CMU+MIT face database. Results indicate that the performance of the proposed method is overall superior to previous Adaboost approaches. Also a technique for detecting faces in color images using AdaBoost algorithm combined with skin colour segmentation. First,skin colour model in the YCbCr chrominance space is built to segment the non-skin-colour pixels from the image. Then, mathematical morphological operators are used to remove noisy regions and fill holes in the skin-color region, so we can extract candidate human face regions. Finally,these face candidates are scanned by cascade classifier based on AdaBoost for more accurate face detection. This system can also detect human face in different scales, various poses, different expressions, lighting conditions, and orientation. Experimental results show the proposed system obtains competitive results and improves detection performance substantially.
Index TermsRatl time video, face detection, face tracking, robotics vision. I. INTRODUCTION Given the rather ambitious task of developing a robust face tracking algorithm which could be seamlessly integrated with Sayas vision system, we embarked on a journey of exploration of the various techniques kindly available for research. In light of the fact that first attempts at face detection date back to the late 90s, the amountof data archived so far was quite overwhelming. Our first attempts included subtraction of subsequent frames and subtraction of frames against a predefined background. These ideas failed to achieve the basic goals and where quickly banned.The next attempt was to implement a method based on skin color filtering in chromatic color space and Gaussianskin color model[1][2]. This method was chosen mostly for its ability to be unaffected by luminosity changes. While looking promising at first and given a great deal of attention and effort, it was also rejected in favor of a method based on Haar-like features[3] which will be discussed in this report. There is substantial study based on the topic of face tracking. Basically, all the study can be simply divided into two categories. One is real time face detection, and the other is the combination of face detection and face tracking. Specifically, some face detection algorithms can get the faces in each frame timely, which can directly achieve the goal of face tracking; the other way to implement face tracking is to detect the face at the start frame first, and then adopt the object tracking algorithm to follow the face in the other frames. The second method of tracking face has been used in this project. In detail, viola jones face detection algorithm and camshift has been adopted to obtain the face and tracking the face, respectively. II. RELATED WORK Face detection is the process of finding all possible faces in a given image. More precisely, we can say face detector has to determine the locations and sizes of all possible human faces in given image. It is a more complex case than face localization in which the number of faces is already known. On the other hand, face detection is the essential first step towards many advanced computer vision, biometrics recognition and multimedia applications, such as face tracking, face recognition, and video surveillance. Face detection is one of the most popular topics of research in computer vision field. In recent years, face recognition has attracted much attention and its research has rapidly expanded by not only engineers but also neuroscientists, since it has many potential applications in computer vision communication and automatic access control system. However, face detection is not straight forward because it has lots of variations of image appearance, such as pose variation (front,non-front), image orientation, illuminating condition and facial expression. a) The goal of face detection The goal of the project is to create a face detector which will be able to find out face candidate present in a given input image and return the image location of each face. For doing that we have to come up with a good algorithm which will be able to give a good detection rate.
Volume 2, Issue 12, December 2013
Page 461
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
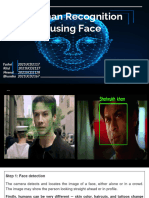
b) Problems closely related to face detection Face localization In face localization we have to determine the image position of single face [10].This is simplified detection problem with assumption that an input image contains only one face. Facial feature detection The goal of facial feature detection is to detect the presence and location of features, such as eyes, nose, nostrils, eyebrow, mouth, lips, ears, etc, with the assumption that there is only one face in an image [10]. Face recognition or face identification In face recognition or face identification it compares an input image against a database and reports a match, if any. The purpose of face authentication is to verify the claim of the identity of an individual in an input image [3]. Face tracking Face tracking methods continuously estimate the location and possibly the orientation of a face in an image sequence in real time[8]. Facial expression recognition Facial expression recognition concerns identifying the affective states of humans like happy, sad, disgusted etc. c) Basic terms Detection rate: It is defined as the ratio between the number of faces correctly detected and the number of faces determined by a human [15]. False negative: In which faces are missed resulting in low detection rates [15]. False positive: In which an image region is declared to be face but it is not [15]. d) Challenges in face Detection: Due to scale, rotation, pose and illumination variation, face detection involves many research challenges. How to detect different scales of faces, how to be robust to illumination variation, how to achieve high detection rate with low false detection rates are only few of all issues a face detection algorithm needs to be consider. For face detection following problems need to be considered: Size: A face detector should be able to detect faces in different sizes. This we can achieved by scaling the input image. And small faces are more difficult to detect than the large face. Expressions: The appearance of a face changes considerably for different facial expressions and, thus, makes the face detection more difficult. The simplest type of variability of images of a face can be expressed independently of the face itself, by rotating, translating, scaling and mirroring its image. Also changes in the overall brightness and contrast of the image and conclusion by other objects. Pose variation: The images of face vary due to relative camera-face pose(frontal,45 degree, profile), and some facial features such as an eye or the nose may become partially or wholly occluded. Another source of variation is the distance of the face from the camera, changes in which can result in perspective distortion. Lighting and Texture Variation: Now we will describe how the variation caused by the object and its environment, specifically the objects surface properties and the light sources. Changes in the light source in particular can change a faces appearance. Background Variation: When an object has predictable shape, it is possible to extract a window which contains only pixels within the object, and to ignore the background. However, for profile faces, the border of the face itself is the most important feature, and its shape varies from person to person. Thus the boundary is not predictable, so the background cannot be simply masked off and ignored. Presence or absence of structural components: Facial features such as beards, moustaches and glasses may or may not be present. And also there may be variability among these components including shape, color and size. Shape Variation: Shape variation includes facial expressions, ether the mouth and eyes are open or closed, and the shape of the individuals face. The appearance of faces are directly affected by persons facial expression. Occlusion: Faces may be partially occluded by other objects. In an image with a group of people some faces may partially occlude other faces. Partial occlusions of faces can be caused by objects within the environment (e.g, poles and people), objects worn by the person (glasses, scarf, mask), Other body parts of person (hands) and shadows. Image orientation: Faces can appear in different orientation the image plane depending on the the angle of the camera and the face. Images directly vary for different rotations about the cameras optical axis. III. REVIEW ON EXISTING FACE DETECTION METHODS Detection Methods: In this chapter we will discuss existing techniques to detect faces from a single intensity or color image. Single image detection methods can be classify into four categories:
Volume 2, Issue 12, December 2013
Page 462
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
Knowledge-based methods[9]: Knowledge-based methods use human-coded rules to model facial features, such as two symmetric eyes, a nose in the middle and a mouth underneath the nose. Feature invariant approches[9]: These algorithm aim to find structural features that exist even when the pose, viewpoint, or lighting conditions vary, and then use these to locate faces. Skin color, edges and shapes falls into this category. Template matching methods[9]: Template matching methods calculate the correlation between a test image and pre-selected facial templates. Several standard patterns of face are stored to describe the face as whole or the facial features separately. Appearance-based methods[9]: The last category, appearance-based, adopts machine learning techniques to extract discriminative features from a prelabelled training set. a) Knowledge-based Top-Down Methods [9] In this approach, face detection methods are developed based on human coded rules to model facial features. It is very easy to make simple rules to describe the features of a face and their relationships. For example, there will be often two eyes in an image that are symmetric to each other, there will be also a nose and a mouth. We can represent the relationship between these features by their relative distances and positions.
Yang and Huang used a hierarchical knowledge-based method to detect faces [6]. Their system consists of three levels of rules. At the highest level, all possible face candidates are found by scanning a window over the input image and applying a set of rules at each location. The rules at a higher level are general descriptions of what a face looks like while the rules at lower levels rely on details of facial features. A multi resolution hierarchy of images is created by averaging and sub sampling, and an example is shown in Fig 2.1. Examples of the coded rules used to locate face candidates in the lowest resolution include:the centre part of the face (the dark shaded parts in Fig3.2.) has four cells with a basically uniform intensity, the upper round part of a face (the light shaded parts in Fig.3.2) has a basically uniform intensity, and the difference between the average gray values of the centre part and the upper round part is significant.
Figure 2.2A typical Face used in knowledge base top down method b) Bottom-up Feature-Based Methods [9] In this method we determine the features which do not vary with different poses or different lighting condition. Facial
Volume 2, Issue 12, December 2013
Page 463
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
features such as eyebrows, eyes, nose, mouth and hair line. These features are commonly extracted using edge detectors.Based on this we can built a model which describe their relationships and verify the existence of face. Main problem with these feature based algorithms is that the image features can be badly corrupted due to illumination, noise and occlusion. Facial features Five features two eyes, two nostrils and nose or lip junction are used to describe a typical face. For any pair of facial features of the same type like left eye, right eye pair their relative distance is computed. Sirohey proposed a localization method to segment a face from a cluttered background for face identification [12]. It uses an edge map and heuristics to remove and group edges so that only the ones on the face contour are preserved. An ellipse is then fit to the boundary between the head region and the background. This algorithm achieves 80 percent accuracy on a database of 48 images with cluttered backgrounds. Graf developed a method to locate facial features and faces in gray scale images [7]. After band pass filtering, morphological operations are applied to enhance regions with high intensity that have certain shapes (e.g., eyes). The histogram of the processed image typically exhibits a prominent peak. Based on the peak value and its width, adaptive threshold values are selected in order to generate two binarised images. Connected components are identified in both binarised images to identify the areas of candidate facial features. Combinations of such areas are then evaluated with classifiers, to determine whether and where a face is present. Their method has been tested with head-shoulder images of 40 individuals and with five video sequences where each sequence consists of 100 to 200 frames. However, it is not clear how morphological operations are performed and how the candidate facial features are combined to locate a face. Texture Human faces have a distinct texture that can be used to separate them from different objects. Augusteijn and Skufca developed a method that explains the presence of a face through the identification of face-like textures [6]. The texture are computed using second-order statistical features (SGLD) on subimages of 16 16 pixels. Three types of features are considered: skin, hair, and others. They used a cascade correlation neural network for supervised classification of textures and a Kohonen self-organizing feature map [2] to form clusters for different texture classes. To infer the presence of a face from the texture labels, they suggest using votes of the occurrence of hair and skin textures. However, only the result of texture classification is reported, not face localization or detection. Skin Color Human skin color can be used for face detection. Although different people have different skin color, according to studies it has been found that major differences lies largely between their intensity rather than their chrominance. Many methods have been proposed to build a skin color model. The simplest model is to define a region of skin tone pixels using Cr, Cb values [9], i.e., R(Cr,Cb), from samples of skin color pixels. With carefully chosen thresholds, [Cr1,Cr2] and [Cb1,Cb2], a pixel is classified to have skin tone if its values (Cr,Cb) fall within the ranges, i.e.,
a) Appearance-Based Methods [9] In template matching method templates are predefined by experts. While in appearance-based methods templates are learned from examples in images .In general appearance-based methods uses machine learning techniques to find the relevant characteristics of face and nonface images. The learned characteristics are in the form of distribution models or discriminate functions that are used for face detection. Many appearance-based methods can be understood in a probabilistic framework. An image or feature vector derived from an image is viewed as a random variable x, and this random variable is characterized for faces and nonfaces by the class-conditional density functions p(x|face) and p(x|nonface).
Volume 2, Issue 12, December 2013
Page 464
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
Bayesian classification or maximum likelihood can be used to classify a candidate image location as face or nonface. Unfortunately, a straightforward implementation of Bayesian classification is infeasible because of the high dimensionality of x, because p(x|face) and p(x|nonface) are multimodal, and because it is not yet understood if there are natural parameterized forms for p(x|face) and p(x|nonface). Hence, much of the work in an appearancebased method concerns empirically validated parametric and nonparametric approximations to p(x|face) and p(x|nonface). Another approach in appearance-based methods is to find a discriminate function (i.e., decision surface, separating hyper plane, threshold function) between face and nonface classes. Conventionally, image patterns are projected to a lower dimensional space and then a discriminate function is formed (usually based on distance metrics) for classification , or a nonlinear decision surface can be formed using multilayer neural networks [11,15]. Recently, support vector machines and other kernel methods have been proposed. These methods implicitly project patterns to a higher dimensional space and then form a decision surface between the projected face and nonface patterns. b) AdaBoost Technique The AdaBoost-based face detection method uses a set of simple rectangular features to detect faces [14]. Three kinds of rectangles are used, a tworectangle feature, a three- rectangle feature and a four-rectangle feature, as shown in Fig2.7. For a given feature, the sum of pixels in the white rectangles is subtracted from the sum of pixels in the black rectangles. Based on these simple features, the AdaBoost based face detection method proposed three significant contributions which make face detection fast. The block diagram is shown in Fig 2.8.First, by utilizing the integral image representation, the simple features can be rapidly computed in linear time. Second, a machine learning method, based on AdaBoost, trains an over-completed feature set and obtains a reduced set of critical features. Third, a cascade architecture of increasingly
Integral Image: An image is first converted into its corresponding integral image. The integral image at location (x, y) is the sum of all pixel values above and to the left of (x, y), inclusive [14].
where ii is the integral image and i is the original image. Any rectangular sum can be computed efficiently by using integral images.
Using the integral image, any rectangular sum can be computed in fourpoint access. Therefore, no matter what the size or the location of feature is, a two-rectangle feature, three-rectangle feature and four-rectangle feature can be computed in six, eight and nine data references, respectively. AdaBoost Learning: AdaBoost is a machine learning technique that allows computers to learn based on known dataset. Recall that there are over 180,000 features in each sub-window. It is infeasible to compute the completed set of features, even if we can compute them very efficiently. According to the hypothesis that small number of features can be associated to form an effective classifier [14], the challenge now turns to be how to find these features. To achieve this goal, the AdaBoost algorithm is designed, for each iteration, to select the single rectangular feature among the 180,000 features available that best separates the positive samples from the negative examples, and determines the optimal threshold for this feature. A weak classifier
Volume 2, Issue 12, December 2013
Page 465
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
hj(x) thus consists of a feature f, a threshold j and a parity pj indicating the direction of the inequality sign:
complex classifiers was proposed to quickly eliminate background windows and focus on more face-like windows.
Cascade Architecture : Along with the integral image representation, the cascade architecture is the Important property which makes the detection fast. The idea of the cascade architecture is that simple classifiers, with fewer features ( which require a shorter computational time) can reject many negative sub-windows while detecting almost all positive objects. The classifiers with more features (and more computational effort) then evaluate only the sub-windows that have passed the simple classifiers. Fig 2.9 shows the cascade architecture consisting of n stages of classifiers. Generally,the later stages contain more features than the early ones. IV. BASIC ALGORITHMS a) MCT (Modified Census Transform) MCT presents the structural information of the window with the binary pattern {0, 1} moving the 33 window in an image small enough to assume that lightness value is almost constant, though the value is actually variable. This pattern contains information on the edges, contours, intersections, etc. MCT can be defined with the equation below: Here X represents a pixel in the image, the 33 window of which X is the center is W(X); N is a set of pixels in W(X) and Y represents nine pixels each in the window. In addition, is the average value of pixels in the window, and is the brightness value of each pixel in the window. As a comparison function, becomes 1 in the case of , other cases are 0. As a set operator, connects binary patterns of function, and then nine binary patterns are connected through operations. As a result, a total of 511 structures can be produced, as theoretically not all nine-pixel values can be 1. Thus connected binary patterns are transformed into binary numbers, which are the values of the pixels in MCT-transformed images. b) Adaboost learning Algorithm Adaboost learning algorithm is created high-reliable learning data as an early stage for face-detection using faces data. Viola and Jones [18] have proposed fast, high performance face-detection algorithm. It is composed of cascade structure with 38 phases, using extracted features to effectively distinguish face and non-face areas through the Adaboost learning algorithm proposed by Freund and Schapire [17]. Furthermore, Froba and Ernst[18] have introduced MCT transformed images and a face detector consisting of a cascade structure with 4 phases using the Adaboost learning algorithm. This paper consists of a face detector with a single-layer structure, using only the fourth phase of the cascade structure proposed by Froba and Ernst.
Volume 2, Issue 12, December 2013
Page 466
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
Figure 2.10 Flow of Face Detection Algorithm V. PROPOSED HARDWARE STRUCTURE
EXPERIMENTAL RESULTS
The developed face detection system has verified superb performance of 99.76 % detection-rate in various illumination environments using Yale face database [20] and BioID face database [20] as shown in Table 1, Table 2, and Figure 5.1. And also we had verified superb performance in real-time hardware though FPGA and ASIC as shown in figure 5.1. First, the system was implemented using Virtex5 LX330 Board [21] with QVGA(320x240) class camera, LCD display. The developed face-detection FPGA system can be processed at a maximum speed of 149 frames per second in real-time and detects at a maximum of 32 faces simultaneously. Additionally, we developed ASIC Chip [22] of 1.2 cm x 1.2 cm BGA type through 0.18um, 1-Poly / 6-Metal CMOS Logic process. Consequently, we verified developed face-detection engine at real-time by 30 frames per second within 13.5 MHz clock frequency with 226 mW power consumption.
Figure 2.11 Original Image
Volume 2, Issue 12, December 2013
Page 467
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
Figure 2.12 Face Detected Image ( Ideal Result )
VI. CONCLUSION & DISCUSSIONS This paper has verified a process that overcomes low detection rates caused by variations in illuminations thanks to the MCT techniques. The proposed face-detection hardware structure that can detect faces with high reliability in real-time was developed with optimized learning data through the Adaboost algorithm. Consequently, the developed face detection engine has strength in various illumination conditions and has ability to detect 32 various sizes of faces simultaneously. The developed FPGA module can detect faces with high reliability in real-time. This technology can be applied to human face-detection logic for cutting-edge digital cameras or recently developed smart phones. Finally, face-detection chip was developed after verifying and implementing through FPGA and it has advantage in real-time, low power consumption and low cost. So we expect this chip can be easily used in mobile applications. By using SVM classifier it would have been achieved better detection rate for all kind of images. Since SVM aims to find the optimal hyper plane that minimizes the generalization error under the theoretical upper bounds. REFERENCES [1] C.J. Taylor, A. Lanitis and T.F. Cootes. An automatic face identification system using fexible appearance models, Image and Vision computing,1995. [2] A.Jain. Fundamentals of Digital Image Processing, prentice-hall, 1986. [3] D. Chai , K. N. Ngan, Locating Facial Region of a Head-and-Shoulders Color Image, Proceedings of the 3rd. International Conference on Face Gesture Recognition, p.124, April 14-16, 1998 [4] Y. Dai, Y. Nakano, Face-texture model-based on SGLD and its application in face detection in a color scene, Pattern Recognition, Vol. 29, No. 6, 1996. [5] R. Freund, E. Osuna and F. Girosi.Training support vector machines: An application to face detection, proc. IEEE conf.computer vision and pattern recognition, pp. 130-136, 1997. [6] R. Gonzalez and R. Woods. Digital Image Processing, addison-wesley publishing company, 1992. [7] E. Petajan, H.P. Graf, T. Chen and E. Cosatto. Locating faces and facial parts, proc. 1st international workshop automatic face and gesture recognition, 1995. [8] Seok-wun Ha Jing Zhang, Yang Liu. A novel approach of face detection based on skin color segmentation and pca,IEEE conf. the 9th international conference for young computer scientists, 2008. [9] Ming-Hsuan Yang, David J. Kriegman, and Narendra Ahuja, Detecting faces in images: A survey,IEEE transactions on pattern analysis and machine intelligence, vol. 24, no. 1, january 2002. [10] Divya S. Vidyadharan Praseeda Lekshmi V, Dr. SasiKumar. Face detection and localization of facial features in still and video images,IEEE conf. 1st international conference on emerging trends in engineering and technology, 2008. [11] H. Rowley, S. Baluja and T. Kanade, Invariant Neural Network-Based Face Detection, IEEE Conf. Computer Vision and Pattern Recognition, pp. 38-44, 1998. [12] S.A. Sirohey, Human face segmentation and identification, technical report cs-tr-3176, univ. of maryland,, 1993. [13] K.-K. Sung and T. Poggio. Example-based learning for view-based human face detection,IEEE transactions on pattern analysis and machine intelligence, 1998. [14] P. Viola and M J. Jones. Rapid object detection using a boosted cascade of simple features, IEEE Conference on Computer vision and pattern Recognition, 2001, [15] Tong Li Wang Zhanjie. A face detection system based skin color and neural network,IEEE International
Volume 2, Issue 12, December 2013
Page 468
International Journal of Application or Innovation in Engineering & Management (IJAIEM)
Web Site: www.ijaiem.org Email: editor@ijaiem.org, editorijaiem@gmail.com Volume 2, Issue 12, December 2013 ISSN 2319 - 4847
conference on computer science and software engineering, 2008. [16] Paul Viola and Michael J. Jones, Robust real-time face detection In International Journal of Computer Vision, pp. 137-154, 2004. [17] Yoav Freund and Robert E. Schapire. "A decision-theoretic generalization of on-line learning and an application to boosting" in Journal of Computer and System Sciences, pp. 119-139, 1997. [18] Bernhard Froba and Andreas Ernst, "Face detection with the Modified Census Transform", IEEE International Conference. On Automatic Face and Gesture Recognition, pp. 91-96, Seoul, Korea, May. 2004. [19] Georghiades, A. : Yale Face Database, Center for computational Vision and Control at Yale University, http: //cvc.yale.edu /projects /yalefaces /yalefa [20] The BioID face database: [http : //www.bioid.com /downloads /facedb/facedatabase.html] [21] Dongil Han, Hyunjong Cho, Jongho Choi, Jaeil Cho, "Design and Implementation of real-time high performance face detection engine", SP(Signal Processing), 47th Book, 3 Issue, The Institute of Electronics Engineers of Korea Publication(IEEK), March, 2010. [22] Seung-Min Choi, Jiho Chang, Jaeil Cho, Dae-Hwan Hwang, "Implementation of Robust Real-time Face Detection ASIC", IEEK Conference 33th Book, 1 Issue, 467-470, Jeju, Korea, June, 2010.
Volume 2, Issue 12, December 2013
Page 469
Вам также может понравиться
- Face Tracking and Robot Shoot Using Adaboost MethodДокумент7 страницFace Tracking and Robot Shoot Using Adaboost MethodInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Face Detection and Recognition - A ReviewДокумент8 страницFace Detection and Recognition - A ReviewHenry MagdayОценок пока нет
- Eigenfaces For Face Recognition: ECE 533 Final Project Report, Fall 03Документ20 страницEigenfaces For Face Recognition: ECE 533 Final Project Report, Fall 03Youssef KamounОценок пока нет
- A Survey of Feature Base Methods For Human Face Detection: Hiyam Hatem, Zou Beiji and Raed MajeedДокумент18 страницA Survey of Feature Base Methods For Human Face Detection: Hiyam Hatem, Zou Beiji and Raed MajeedRolandoRamosConОценок пока нет
- Detecting Faces in Images: A SurveyДокумент25 страницDetecting Faces in Images: A Surveyالدنيا لحظهОценок пока нет
- Emotion Recognition PDFДокумент7 страницEmotion Recognition PDFRama DeviОценок пока нет
- B2Документ44 страницыB2orsangobirukОценок пока нет
- A Fuzzy Logic Based Human Behavioural Analysis Model Using Facial Feature Extraction With Perceptual ComputingДокумент6 страницA Fuzzy Logic Based Human Behavioural Analysis Model Using Facial Feature Extraction With Perceptual ComputingInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Redundancy in Face Image RecognitionДокумент4 страницыRedundancy in Face Image RecognitionIJAERS JOURNALОценок пока нет
- Are View On Face Detection MethodsДокумент12 страницAre View On Face Detection MethodsQuang MinhОценок пока нет
- 1.1. Overview: Department of Computer Science & Engineering, VITS, Satna (M.P.) IndiaДокумент36 страниц1.1. Overview: Department of Computer Science & Engineering, VITS, Satna (M.P.) IndiamanuОценок пока нет
- 2D Face Detection and Recognition MSC (I.T)Документ61 страница2D Face Detection and Recognition MSC (I.T)Santosh Kodte100% (1)
- Face Recognition Techniques and Its ApplicationДокумент3 страницыFace Recognition Techniques and Its ApplicationInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Face Recognition Report 1Документ26 страницFace Recognition Report 1Binny DaraОценок пока нет
- A Survey On Face Recognition TechniquesДокумент5 страницA Survey On Face Recognition TechniquesIJSTEОценок пока нет
- 6.report Face RecognitionДокумент45 страниц6.report Face RecognitionSuresh MgОценок пока нет
- Background Study and Literature ReviewДокумент22 страницыBackground Study and Literature ReviewHafizuddin TarmiziОценок пока нет
- Human Face Detection and Segmentation of Facial Feature RegionДокумент9 страницHuman Face Detection and Segmentation of Facial Feature RegionGurudev YankanchiОценок пока нет
- Research Paper - Human Face DetectionДокумент8 страницResearch Paper - Human Face DetectionPremchand LukramОценок пока нет
- Machine Learning ApproachДокумент6 страницMachine Learning ApproachArief SeptiawanОценок пока нет
- Face RecognitionДокумент4 страницыFace RecognitionSanket ShahОценок пока нет
- Face Detection and Face RecognitionДокумент7 страницFace Detection and Face RecognitionPranshu AgrawalОценок пока нет
- Face Detection - A Literature Survey: AbstractДокумент4 страницыFace Detection - A Literature Survey: AbstractIjctJournalsОценок пока нет
- Cl311-Face Recognition SystemДокумент24 страницыCl311-Face Recognition SystemBhavik2002Оценок пока нет
- Application of Soft Computing To Face RecognitionДокумент68 страницApplication of Soft Computing To Face RecognitionAbdullah GubbiОценок пока нет
- Introduction To Innovative Projects Face Recognition (Opencv)Документ20 страницIntroduction To Innovative Projects Face Recognition (Opencv)karthik vajjaОценок пока нет
- Face Detection and Its Applications: ISSN: 2320 - 8791Документ10 страницFace Detection and Its Applications: ISSN: 2320 - 8791anon_303010132Оценок пока нет
- Face DetectionДокумент21 страницаFace Detectionعلم الدين خالد مجيد علوانОценок пока нет
- Unit 3 BM Learning Material With ActДокумент17 страницUnit 3 BM Learning Material With ActveeravalliyogeshsaivenkatОценок пока нет
- A Survey On Face Recognition TechniquesДокумент7 страницA Survey On Face Recognition TechniquesAlexander DeckerОценок пока нет
- E D U F N C - C: Fficient Eyes Etection Sing AST Ormalised Ross OrrelationДокумент7 страницE D U F N C - C: Fficient Eyes Etection Sing AST Ormalised Ross OrrelationsipijОценок пока нет
- 10 Chapter1 PDFДокумент5 страниц10 Chapter1 PDFTony ChopperОценок пока нет
- A New Method For Face Recognition Using Variance Estimation and Feature ExtractionДокумент8 страницA New Method For Face Recognition Using Variance Estimation and Feature ExtractionInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- DR - Subbiah RR 09.09.2020Документ4 страницыDR - Subbiah RR 09.09.2020Subbiah SОценок пока нет
- Real Time Face Pose Estimation Based On HAAR For Human-Robot InteractionДокумент9 страницReal Time Face Pose Estimation Based On HAAR For Human-Robot InteractionJandres MaldonadoОценок пока нет
- Effect of Distance Measures in Pca Based Face: RecognitionДокумент15 страницEffect of Distance Measures in Pca Based Face: Recognitionadmin2146Оценок пока нет
- Department of Electrical Engineering: El223: Signals & Systems Lab "Real-Time Face Recognition"Документ7 страницDepartment of Electrical Engineering: El223: Signals & Systems Lab "Real-Time Face Recognition"Zaighi ChohanОценок пока нет
- Face Detection AppДокумент15 страницFace Detection Apprithikashivani06Оценок пока нет
- Face Recognization: A Review: International Journal of Application or Innovation in Engineering & Management (IJAIEM)Документ3 страницыFace Recognization: A Review: International Journal of Application or Innovation in Engineering & Management (IJAIEM)International Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- 3D Face Recognition Based On Deformation Invariant Image Using Symbolic LDAДокумент6 страниц3D Face Recognition Based On Deformation Invariant Image Using Symbolic LDAwarse1Оценок пока нет
- Intro Face Detect RecognitionДокумент43 страницыIntro Face Detect RecognitionHao YuОценок пока нет
- Alamaldin Face DetectionДокумент21 страницаAlamaldin Face Detectionعلم الدين خالد مجيد علوانОценок пока нет
- Design of A Face Recognition SystemДокумент12 страницDesign of A Face Recognition SystemWeights MattersОценок пока нет
- Research PaperДокумент13 страницResearch Paperhakkem bОценок пока нет
- A Literature Survey On Face Recognition TechniquesДокумент6 страницA Literature Survey On Face Recognition TechniquesseventhsensegroupОценок пока нет
- The Use of Neural Networks in Real-Time Face DetectionДокумент16 страницThe Use of Neural Networks in Real-Time Face Detectionkaushik73Оценок пока нет
- A Survey of Face Recognition Approach: Jigar M. Pandya, Devang Rathod, Jigna J. JadavДокумент4 страницыA Survey of Face Recognition Approach: Jigar M. Pandya, Devang Rathod, Jigna J. JadavSalman umerОценок пока нет
- Thesis On Face Recognition PDFДокумент8 страницThesis On Face Recognition PDFScott Bou100% (1)
- Robust Decision Making System Based On Facial Emotional ExpressionsДокумент6 страницRobust Decision Making System Based On Facial Emotional ExpressionsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Pattern RecognitionДокумент12 страницPattern RecognitionHarvinraj MohanapiragashОценок пока нет
- Deepak Result PaperДокумент7 страницDeepak Result Papervikas chawlaОценок пока нет
- EP494 PowerpointFaДокумент30 страницEP494 PowerpointFaBharath KumarОценок пока нет
- 2D Face RecognitionДокумент28 страниц2D Face Recognitionjit_72Оценок пока нет
- Detecting Faces in Images: A SurveyДокумент25 страницDetecting Faces in Images: A SurveySetyo Nugroho100% (17)
- Review of Face Detection System Using Neural NetworkДокумент5 страницReview of Face Detection System Using Neural NetworkVIVA-TECH IJRIОценок пока нет
- Face RecognitionДокумент27 страницFace RecognitionManendra PatwaОценок пока нет
- VA Lecture 23Документ42 страницыVA Lecture 23akshittayal24Оценок пока нет
- Feature-Based Human Face Detection: Kin Choong Yow and Roberto Cipolla August 1996Документ27 страницFeature-Based Human Face Detection: Kin Choong Yow and Roberto Cipolla August 1996Ahmad Thaqib FawwazОценок пока нет
- Detection of Malicious Web Contents Using Machine and Deep Learning ApproachesДокумент6 страницDetection of Malicious Web Contents Using Machine and Deep Learning ApproachesInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Customer Satisfaction A Pillar of Total Quality ManagementДокумент9 страницCustomer Satisfaction A Pillar of Total Quality ManagementInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Analysis of Product Reliability Using Failure Mode Effect Critical Analysis (FMECA) - Case StudyДокумент6 страницAnalysis of Product Reliability Using Failure Mode Effect Critical Analysis (FMECA) - Case StudyInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Study of Customer Experience and Uses of Uber Cab Services in MumbaiДокумент12 страницStudy of Customer Experience and Uses of Uber Cab Services in MumbaiInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- An Importance and Advancement of QSAR Parameters in Modern Drug Design: A ReviewДокумент9 страницAn Importance and Advancement of QSAR Parameters in Modern Drug Design: A ReviewInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Experimental Investigations On K/s Values of Remazol Reactive Dyes Used For Dyeing of Cotton Fabric With Recycled WastewaterДокумент7 страницExperimental Investigations On K/s Values of Remazol Reactive Dyes Used For Dyeing of Cotton Fabric With Recycled WastewaterInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- THE TOPOLOGICAL INDICES AND PHYSICAL PROPERTIES OF n-HEPTANE ISOMERSДокумент7 страницTHE TOPOLOGICAL INDICES AND PHYSICAL PROPERTIES OF n-HEPTANE ISOMERSInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Detection of Malicious Web Contents Using Machine and Deep Learning ApproachesДокумент6 страницDetection of Malicious Web Contents Using Machine and Deep Learning ApproachesInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Study of Customer Experience and Uses of Uber Cab Services in MumbaiДокумент12 страницStudy of Customer Experience and Uses of Uber Cab Services in MumbaiInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Analysis of Product Reliability Using Failure Mode Effect Critical Analysis (FMECA) - Case StudyДокумент6 страницAnalysis of Product Reliability Using Failure Mode Effect Critical Analysis (FMECA) - Case StudyInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- THE TOPOLOGICAL INDICES AND PHYSICAL PROPERTIES OF n-HEPTANE ISOMERSДокумент7 страницTHE TOPOLOGICAL INDICES AND PHYSICAL PROPERTIES OF n-HEPTANE ISOMERSInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Experimental Investigations On K/s Values of Remazol Reactive Dyes Used For Dyeing of Cotton Fabric With Recycled WastewaterДокумент7 страницExperimental Investigations On K/s Values of Remazol Reactive Dyes Used For Dyeing of Cotton Fabric With Recycled WastewaterInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Customer Satisfaction A Pillar of Total Quality ManagementДокумент9 страницCustomer Satisfaction A Pillar of Total Quality ManagementInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- The Mexican Innovation System: A System's Dynamics PerspectiveДокумент12 страницThe Mexican Innovation System: A System's Dynamics PerspectiveInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Staycation As A Marketing Tool For Survival Post Covid-19 in Five Star Hotels in Pune CityДокумент10 страницStaycation As A Marketing Tool For Survival Post Covid-19 in Five Star Hotels in Pune CityInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Soil Stabilization of Road by Using Spent WashДокумент7 страницSoil Stabilization of Road by Using Spent WashInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Design and Detection of Fruits and Vegetable Spoiled Detetction SystemДокумент8 страницDesign and Detection of Fruits and Vegetable Spoiled Detetction SystemInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- A Digital Record For Privacy and Security in Internet of ThingsДокумент10 страницA Digital Record For Privacy and Security in Internet of ThingsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- A Deep Learning Based Assistant For The Visually ImpairedДокумент11 страницA Deep Learning Based Assistant For The Visually ImpairedInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- An Importance and Advancement of QSAR Parameters in Modern Drug Design: A ReviewДокумент9 страницAn Importance and Advancement of QSAR Parameters in Modern Drug Design: A ReviewInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- The Impact of Effective Communication To Enhance Management SkillsДокумент6 страницThe Impact of Effective Communication To Enhance Management SkillsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Performance of Short Transmission Line Using Mathematical MethodДокумент8 страницPerformance of Short Transmission Line Using Mathematical MethodInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- A Comparative Analysis of Two Biggest Upi Paymentapps: Bhim and Google Pay (Tez)Документ10 страницA Comparative Analysis of Two Biggest Upi Paymentapps: Bhim and Google Pay (Tez)International Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Challenges Faced by Speciality Restaurants in Pune City To Retain Employees During and Post COVID-19Документ10 страницChallenges Faced by Speciality Restaurants in Pune City To Retain Employees During and Post COVID-19International Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Secured Contactless Atm Transaction During Pandemics With Feasible Time Constraint and Pattern For OtpДокумент12 страницSecured Contactless Atm Transaction During Pandemics With Feasible Time Constraint and Pattern For OtpInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Anchoring of Inflation Expectations and Monetary Policy Transparency in IndiaДокумент9 страницAnchoring of Inflation Expectations and Monetary Policy Transparency in IndiaInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Advanced Load Flow Study and Stability Analysis of A Real Time SystemДокумент8 страницAdvanced Load Flow Study and Stability Analysis of A Real Time SystemInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Synthetic Datasets For Myocardial Infarction Based On Actual DatasetsДокумент9 страницSynthetic Datasets For Myocardial Infarction Based On Actual DatasetsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Impact of Covid-19 On Employment Opportunities For Fresh Graduates in Hospitality &tourism IndustryДокумент8 страницImpact of Covid-19 On Employment Opportunities For Fresh Graduates in Hospitality &tourism IndustryInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Predicting The Effect of Fineparticulate Matter (PM2.5) On Anecosystemincludingclimate, Plants and Human Health Using MachinelearningmethodsДокумент10 страницPredicting The Effect of Fineparticulate Matter (PM2.5) On Anecosystemincludingclimate, Plants and Human Health Using MachinelearningmethodsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Exploring Nurses' Knowledge of The Glasgow Coma Scale in Intensive Care and Emergency Departments at A Tertiary Hospital in Riyadh City, Saudi ArabiaДокумент9 страницExploring Nurses' Knowledge of The Glasgow Coma Scale in Intensive Care and Emergency Departments at A Tertiary Hospital in Riyadh City, Saudi Arabianishu thapaОценок пока нет
- Paper 11-ICOSubmittedДокумент10 страницPaper 11-ICOSubmittedNhat Tan MaiОценок пока нет
- NRNP PRAC 6665 and 6675 Focused SOAP Note ExemplarДокумент6 страницNRNP PRAC 6665 and 6675 Focused SOAP Note ExemplarLogan ZaraОценок пока нет
- Code of Conduct For Public OfficialДокумент17 страницCode of Conduct For Public OfficialHaОценок пока нет
- The Role of IT in TQM L'Oreal Case StudyДокумент9 страницThe Role of IT in TQM L'Oreal Case StudyUdrea RoxanaОценок пока нет
- An Enhanced RFID-Based Authentication Protocol Using PUF For Vehicular Cloud ComputingДокумент18 страницAn Enhanced RFID-Based Authentication Protocol Using PUF For Vehicular Cloud Computing0dayОценок пока нет
- The Frozen Path To EasthavenДокумент48 страницThe Frozen Path To EasthavenDarwin Diaz HidalgoОценок пока нет
- English 9 Week 5 Q4Документ4 страницыEnglish 9 Week 5 Q4Angel EjeОценок пока нет
- Majan Audit Report Final2Документ46 страницMajan Audit Report Final2Sreekanth RallapalliОценок пока нет
- First Semester-NOTESДокумент182 страницыFirst Semester-NOTESkalpanaОценок пока нет
- Nursing Care Plan TemplateДокумент3 страницыNursing Care Plan TemplateJeffrey GagoОценок пока нет
- Permeability PropertiesДокумент12 страницPermeability Propertieskiwi27_87Оценок пока нет
- Activity 4 - Energy Flow and Food WebДокумент4 страницыActivity 4 - Energy Flow and Food WebMohamidin MamalapatОценок пока нет
- The Politics of GenreДокумент21 страницаThe Politics of GenreArunabha ChaudhuriОценок пока нет
- The Eye WorksheetДокумент3 страницыThe Eye WorksheetCally ChewОценок пока нет
- Lords of ChaosДокумент249 страницLords of ChaosBill Anderson67% (3)
- Good Manufacturing Practices in Postharvest and Minimal Processing of Fruits and VegetablesДокумент40 страницGood Manufacturing Practices in Postharvest and Minimal Processing of Fruits and Vegetablesmaya janiОценок пока нет
- Statistics and Probability Course Syllabus (2023) - SignedДокумент3 страницыStatistics and Probability Course Syllabus (2023) - SignedDarence Fujihoshi De AngelОценок пока нет
- Curriculum Vitae: Educational Background Certification Major Name of Institute PeriodДокумент2 страницыCurriculum Vitae: Educational Background Certification Major Name of Institute PeriodTHEVINESHОценок пока нет
- Procedure Manual - IMS: Locomotive Workshop, Northern Railway, LucknowДокумент8 страницProcedure Manual - IMS: Locomotive Workshop, Northern Railway, LucknowMarjorie Dulay Dumol80% (5)
- TOPIC 2 - Fans, Blowers and Air CompressorДокумент69 страницTOPIC 2 - Fans, Blowers and Air CompressorCllyan ReyesОценок пока нет
- Operator Training ManualДокумент195 страницOperator Training ManualIgnacio MuñozОценок пока нет
- GDCR - Second RevisedДокумент290 страницGDCR - Second RevisedbhaveshbhoiОценок пока нет
- Dadm Assesment #2: Akshat BansalДокумент24 страницыDadm Assesment #2: Akshat BansalAkshatОценок пока нет
- Pelatihan Dan Workshop Peningkatan Kompetensi GuruДокумент6 страницPelatihan Dan Workshop Peningkatan Kompetensi Guruhenry jakatariОценок пока нет
- RL78 L1B UsermanualДокумент1 062 страницыRL78 L1B UsermanualHANUMANTHA RAO GORAKAОценок пока нет
- Hamza Akbar: 0308-8616996 House No#531A-5 O/S Dehli Gate MultanДокумент3 страницыHamza Akbar: 0308-8616996 House No#531A-5 O/S Dehli Gate MultanTalalОценок пока нет
- What Role Does Imagination Play in Producing Knowledge About The WorldДокумент1 страницаWhat Role Does Imagination Play in Producing Knowledge About The WorldNathanael Samuel KuruvillaОценок пока нет
- Industrial Automation Using PLCДокумент29 страницIndustrial Automation Using PLCAditya JagannathanОценок пока нет
- School of Management Studies INDIRA GANDHI NATIONAL OPEN UNIVERSITY Proforma For Approval of Project Proposal (MS-100)Документ12 страницSchool of Management Studies INDIRA GANDHI NATIONAL OPEN UNIVERSITY Proforma For Approval of Project Proposal (MS-100)Pramod ShawОценок пока нет