Вам также может понравиться
- Research ProposalДокумент6 страницResearch ProposalApam BenjaminОценок пока нет
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Документ8 страницMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminОценок пока нет
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenДокумент12 страницCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminОценок пока нет
- Oxygen Cycle: PlantsДокумент3 страницыOxygen Cycle: PlantsApam BenjaminОценок пока нет
- Nitrogen Cycle: Ecological FunctionДокумент8 страницNitrogen Cycle: Ecological FunctionApam BenjaminОценок пока нет
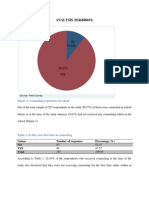
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolДокумент8 страницANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminОценок пока нет
- Lecture7 Module2 Anova 1Документ10 страницLecture7 Module2 Anova 1Apam BenjaminОценок пока нет
- PLM IiДокумент3 страницыPLM IiApam BenjaminОценок пока нет
- Lecture6 Module2 Anova 1Документ10 страницLecture6 Module2 Anova 1Apam BenjaminОценок пока нет
- Lecture5 Module2 Anova 1Документ9 страницLecture5 Module2 Anova 1Apam BenjaminОценок пока нет
- PLMДокумент5 страницPLMApam BenjaminОценок пока нет
- Hosmer On Survival With StataДокумент21 страницаHosmer On Survival With StataApam BenjaminОценок пока нет
- Lecture4 Module2 Anova 1Документ9 страницLecture4 Module2 Anova 1Apam BenjaminОценок пока нет
- Finish WorkДокумент116 страницFinish WorkApam BenjaminОценок пока нет
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsДокумент14 страницHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminОценок пока нет
- 6th Central Pay Commission Salary CalculatorДокумент15 страниц6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- A Study On School DropoutsДокумент6 страницA Study On School DropoutsApam BenjaminОценок пока нет
- Ajsms 2 4 348 355Документ8 страницAjsms 2 4 348 355Akolgo PaulinaОценок пока нет
- ARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaДокумент9 страницARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaApam BenjaminОценок пока нет
- Personal Information: Curriculum VitaeДокумент6 страницPersonal Information: Curriculum VitaeApam BenjaminОценок пока нет
- Trial Questions (PLM)Документ3 страницыTrial Questions (PLM)Apam BenjaminОценок пока нет
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaДокумент7 страницRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminОценок пока нет
- Asri Stata 2013-FlyerДокумент1 страницаAsri Stata 2013-FlyerAkolgo PaulinaОценок пока нет
- Creating STATA DatasetsДокумент4 страницыCreating STATA DatasetsApam BenjaminОценок пока нет
- Banque AtlanticbanДокумент1 страницаBanque AtlanticbanApam BenjaminОценок пока нет
- How To Write A Paper For A Scientific JournalДокумент10 страницHow To Write A Paper For A Scientific JournalApam BenjaminОценок пока нет
- l.4. Research QuestionsДокумент1 страницаl.4. Research QuestionsApam BenjaminОценок пока нет
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteДокумент1 страницаMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminОценок пока нет
- Project ReportsДокумент31 страницаProject ReportsBilal AliОценок пока нет
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (120)
- Capital Adequacy Ratio As Performance Indicator of Banking Sector in India-An Analytical Study of Selected BanksДокумент7 страницCapital Adequacy Ratio As Performance Indicator of Banking Sector in India-An Analytical Study of Selected Banksanon_614457836Оценок пока нет
- BPMN3143 Silibus STUDENTS A222Документ5 страницBPMN3143 Silibus STUDENTS A222Veronika PutrianiОценок пока нет
- The SummaryДокумент6 страницThe SummaryAlleinad BarracasОценок пока нет
- R in Action, Second EditionДокумент2 страницыR in Action, Second EditionDreamtech Press0% (1)
- Pamintuan, Laurenz 0127Документ20 страницPamintuan, Laurenz 0127Renz PamintuanОценок пока нет
- Statistics Translated A Step by Step Guide To Analyzing and Interpreting Data 2nd EditionДокумент459 страницStatistics Translated A Step by Step Guide To Analyzing and Interpreting Data 2nd EditionLegatus_Praetorian100% (1)
- Effect of NAAДокумент5 страницEffect of NAADlieya ZaliaОценок пока нет
- Factors Affecting Students' Decision To Drop Out of School: Hermogenes C. Orion, JRДокумент16 страницFactors Affecting Students' Decision To Drop Out of School: Hermogenes C. Orion, JRJerico riveraОценок пока нет
- Competitive AnalysisДокумент67 страницCompetitive AnalysisHariKishanОценок пока нет
- Using Priming Methods in Second Language ResearchДокумент239 страницUsing Priming Methods in Second Language Researchisaacmum0314Оценок пока нет
- Using Designed Experiments (DOE) To Minimize Moisture Loss - MinitabДокумент11 страницUsing Designed Experiments (DOE) To Minimize Moisture Loss - MinitabMurali AnirudhОценок пока нет
- 0Документ14 страниц0Edton EcleoОценок пока нет
- Thesis StatementДокумент58 страницThesis StatementSam Lorenz ReulaОценок пока нет
- Inspiring Future Entrepreneurs: The Effect of Experiential Learning On The Entrepreneurial Intention at Higher EducationДокумент12 страницInspiring Future Entrepreneurs: The Effect of Experiential Learning On The Entrepreneurial Intention at Higher EducationIJELS Research JournalОценок пока нет
- Annual Biomass Production of Selected Acridid SpeciesДокумент18 страницAnnual Biomass Production of Selected Acridid SpeciesSubhas RoyОценок пока нет
- SBE - 11e Ch13b DOE and Analysis of Variance DOE ANOVAДокумент24 страницыSBE - 11e Ch13b DOE and Analysis of Variance DOE ANOVAjohn brownОценок пока нет
- 100 Data Science in R Interview Questions and Answers For 2016Документ56 страниц100 Data Science in R Interview Questions and Answers For 2016Tata Sairamesh100% (2)
- Variance FtestДокумент17 страницVariance FtestKartik MehtaОценок пока нет
- Stata Cheat SheetsДокумент6 страницStata Cheat SheetsameliasoeharmanОценок пока нет
- Statistical ToolsДокумент95 страницStatistical ToolsMercy NunezОценок пока нет
- Bear Handout Hypothesis TestingДокумент12 страницBear Handout Hypothesis TestingVictor IslasОценок пока нет
- Tugas Uji Asumsi KlasikДокумент6 страницTugas Uji Asumsi KlasikCandra GunawanОценок пока нет
- ArticleДокумент6 страницArticleinas zahraОценок пока нет
- Mechanical Testing and Microstructure Characterization of Glass Fiber Reinforced Isophthalic Polyester CompositesДокумент10 страницMechanical Testing and Microstructure Characterization of Glass Fiber Reinforced Isophthalic Polyester Compositespinkan25Оценок пока нет
- 09 - Anderson, Jennings, Lowe & Reckers - The Mitigation of Hindsight Bias in Judges' Evaluation of Auditor DecisionsДокумент21 страница09 - Anderson, Jennings, Lowe & Reckers - The Mitigation of Hindsight Bias in Judges' Evaluation of Auditor DecisionsTorikul MunjasiОценок пока нет
- PantovicДокумент20 страницPantovicNabitalo SusanОценок пока нет
- NPT 2Документ11 страницNPT 2Vilayat AliОценок пока нет
- E2857-11 Analytical Validation Method PDFДокумент5 страницE2857-11 Analytical Validation Method PDFswapon kumar shillОценок пока нет
- SolutionsДокумент178 страницSolutionsAdnan Ali Raza50% (4)
- A84 Reyes KalkanДокумент20 страницA84 Reyes Kalkanmansoor_yakhchalian2Оценок пока нет