Вам также может понравиться
- Working For Money, Not For Building Your DreamsДокумент5 страницWorking For Money, Not For Building Your DreamsrajeevforyouОценок пока нет
- Saving AccountДокумент1 страницаSaving AccountrajeevforyouОценок пока нет
- Marketing PlanДокумент5 страницMarketing PlanrajeevforyouОценок пока нет
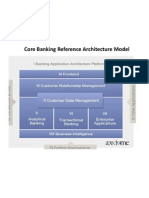
- Core Banking Reference Architecture ModelДокумент4 страницыCore Banking Reference Architecture ModelrajeevforyouОценок пока нет
- Case SreedharaДокумент3 страницыCase SreedhararajeevforyouОценок пока нет
- Vlcc-Swot: Strengths WeaknessДокумент3 страницыVlcc-Swot: Strengths Weaknessrajeevforyou100% (1)
- Case SreedharaДокумент3 страницыCase SreedhararajeevforyouОценок пока нет
- Design The Marketing Channel For Exports of Power Equipment by BHELДокумент1 страницаDesign The Marketing Channel For Exports of Power Equipment by BHELrajeevforyouОценок пока нет
- Case Study:: Tata Motors LTD InДокумент30 страницCase Study:: Tata Motors LTD InrajeevforyouОценок пока нет
- Dyadic Leadership: Ashish Bagla-1020807 Donald Brian-1020809 Jacob Vergese-1020811Документ24 страницыDyadic Leadership: Ashish Bagla-1020807 Donald Brian-1020809 Jacob Vergese-1020811rajeevforyouОценок пока нет
- Banpur Biomass GasifierДокумент6 страницBanpur Biomass GasifierrajeevforyouОценок пока нет
- Heavy Engineering Corporation Presented by RajeevДокумент13 страницHeavy Engineering Corporation Presented by RajeevrajeevforyouОценок пока нет
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- DS (CSC-214) LAB Mannual For StudentsДокумент58 страницDS (CSC-214) LAB Mannual For StudentsVinitha AmaranОценок пока нет
- DS - Practical - 1Документ16 страницDS - Practical - 1Soha KULKARNIОценок пока нет
- BbcwinДокумент1 016 страницBbcwinbakoulisОценок пока нет
- Numerical Methods Lab ReportДокумент12 страницNumerical Methods Lab ReportSANTOSH DAHALОценок пока нет
- Guidelines For Preparing The GSoC 2021 Application ProposalДокумент5 страницGuidelines For Preparing The GSoC 2021 Application ProposalNabeel MerchantОценок пока нет
- XOOPS: Module Structure FunctionДокумент7 страницXOOPS: Module Structure Functionxoops100% (3)
- (LASER) BITS WILP Data Structures and Algorithms Design Assignment 2017Документ32 страницы(LASER) BITS WILP Data Structures and Algorithms Design Assignment 2017John WickОценок пока нет
- Achraf's ResumeДокумент1 страницаAchraf's ResumeKhiter MedОценок пока нет
- Kerala University Semester Four Syllabus For Computer ScienceДокумент9 страницKerala University Semester Four Syllabus For Computer ScienceAbhijith MarathakamОценок пока нет
- Assignment of Software (Naveen Sajwan) BCAДокумент11 страницAssignment of Software (Naveen Sajwan) BCATechnical BaBaОценок пока нет
- Python Examples: 1 Control FlowДокумент8 страницPython Examples: 1 Control FlowSu Su AungОценок пока нет
- 12 CS - SQPДокумент5 страниц12 CS - SQPkumaran mudОценок пока нет
- LogДокумент10 страницLogRenz Yvan EstradaОценок пока нет
- Corenlp: Stanford Corenlp - Natural Language SoftwareДокумент4 страницыCorenlp: Stanford Corenlp - Natural Language SoftwareTushar SethiОценок пока нет
- Oops Cse Lab ManualДокумент27 страницOops Cse Lab ManualRajОценок пока нет
- Properties of Levenshtein, N-Gram, Cosine and Jaccard Distance Coefficients - in Sentence MatchingДокумент1 страницаProperties of Levenshtein, N-Gram, Cosine and Jaccard Distance Coefficients - in Sentence MatchingAngelRibeiro10Оценок пока нет
- 2002 New Heuristics For One-Dimensional Bin-PackingДокумент19 страниц2002 New Heuristics For One-Dimensional Bin-Packingaegr82Оценок пока нет
- A Storage Class Defines The ScopeДокумент6 страницA Storage Class Defines The ScopejyothibellaryvОценок пока нет
- Learning Javascript Data Structures and AlgorithmsДокумент307 страницLearning Javascript Data Structures and AlgorithmsLemuel Uhuru100% (4)
- Rainmeter-4.5.13.exe SummaryДокумент1 страницаRainmeter-4.5.13.exe SummarytestОценок пока нет
- Data Analytics Beginners Guide - Shared by WorldLine TechnologyДокумент22 страницыData Analytics Beginners Guide - Shared by WorldLine Technologykhanh vu ngoc100% (1)
- Student Information: To Write A PL/SQL Programmer To Student InformationДокумент5 страницStudent Information: To Write A PL/SQL Programmer To Student InformationatozdhiyanesОценок пока нет
- Verilog m4 PDFДокумент6 страницVerilog m4 PDFPRERANA SHETОценок пока нет
- Pandas GuideДокумент65 страницPandas GuideOvidio DuarteОценок пока нет
- Unix DumpsДокумент21 страницаUnix DumpsGopakumar GopinathanОценок пока нет
- Buffer HierДокумент1 страницаBuffer HierPushkal KS VaidyaОценок пока нет
- CS 401: Applied Scientific Computing With MATLABДокумент21 страницаCS 401: Applied Scientific Computing With MATLABmanishtopsecretsОценок пока нет
- 01 - Basic - TechnologyFct PDFДокумент728 страниц01 - Basic - TechnologyFct PDFislamooovОценок пока нет
- Information: Fluency With TechnologyДокумент19 страницInformation: Fluency With TechnologyManpreet SinghОценок пока нет
- JF 4 1 Solution PDFДокумент2 страницыJF 4 1 Solution PDFIndri Rahmayuni100% (1)