Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Assignment 2 - BenchmarkingДокумент7 страницAssignment 2 - BenchmarkingJona D'john50% (2)
- Facilitation PDFДокумент40 страницFacilitation PDFMariver Llorente100% (1)
- The Entreprenurial Mind: Course DescriptionДокумент19 страницThe Entreprenurial Mind: Course DescriptionStephanie Andal100% (1)
- Cloud Center of ExcellenceДокумент28 страницCloud Center of ExcellenceIvo Haagen100% (3)
- GTAG 07 - IT Outsourcing 2nd Edition PDFДокумент34 страницыGTAG 07 - IT Outsourcing 2nd Edition PDFton r100% (1)
- Apple I Phone ReportДокумент21 страницаApple I Phone ReportRubab KhanОценок пока нет
- TechniumДокумент14 страницTechniumPeter ParkerОценок пока нет
- CRM in Retail Marketing: Big Bazar: Gedela Rakesh Varma Prof - Jaladi RaviДокумент12 страницCRM in Retail Marketing: Big Bazar: Gedela Rakesh Varma Prof - Jaladi RavipoojanarОценок пока нет
- Five Forces Industry AnalysisДокумент23 страницыFive Forces Industry AnalysisJohn Aldridge ChewОценок пока нет
- Adams Shoes GreeceДокумент435 страницAdams Shoes GreeceDataGroup Retailer AnalysisОценок пока нет
- Literature Review Talent ManagementДокумент6 страницLiterature Review Talent Managementafdttjcns100% (1)
- Creating Competitive AdvantageДокумент18 страницCreating Competitive AdvantageAli RAZAОценок пока нет
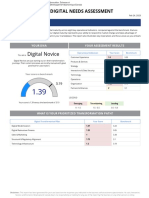
- CDAP Digital Needs AssessmentДокумент6 страницCDAP Digital Needs AssessmentErika MontezaОценок пока нет
- CV Sunil KalanagaSrinivasДокумент7 страницCV Sunil KalanagaSrinivasSrinivasa GarlapatiОценок пока нет
- Music2go Players ManualДокумент65 страницMusic2go Players ManualKiran ShettyОценок пока нет
- Business Case TemplateДокумент10 страницBusiness Case TemplateAbebe TilahunОценок пока нет
- Credit Policy of A Commercial Bank in Conditions oДокумент11 страницCredit Policy of A Commercial Bank in Conditions oMohamed AbdelhamidОценок пока нет
- Learning Organization of ExcoДокумент28 страницLearning Organization of ExcobahmanyarОценок пока нет
- School PlanningДокумент103 страницыSchool PlanningAjay LalooОценок пока нет
- AllentownДокумент5 страницAllentownAnkur Rao BisenОценок пока нет
- Modelo NegociosДокумент374 страницыModelo NegociosEunice DuarteОценок пока нет
- Course Entrance Survey Jj616 Maintenance ManagementДокумент5 страницCourse Entrance Survey Jj616 Maintenance ManagementAkiff JayariОценок пока нет
- Corporate Strategy Assignment 2Документ10 страницCorporate Strategy Assignment 2SRIОценок пока нет
- AmwayДокумент55 страницAmwayAnkitAggarwal100% (3)
- 5 C's of Marketing Definition - Marketing Dictionary - MBA Skool-Study - LearnДокумент2 страницы5 C's of Marketing Definition - Marketing Dictionary - MBA Skool-Study - LearnabhiroopboseОценок пока нет
- Assignment BM014 3.5 3 DMKGДокумент7 страницAssignment BM014 3.5 3 DMKGDavid CarolОценок пока нет
- RC 2013 En-21061Документ220 страницRC 2013 En-21061Sadiq SaminОценок пока нет
- MTI Project Presentation NOTION INKДокумент14 страницMTI Project Presentation NOTION INKmahtaabkОценок пока нет
- Industrial MarketingДокумент165 страницIndustrial MarketingCarlo Niño Gedoria100% (1)
- Case Studies (Must Read)Документ44 страницыCase Studies (Must Read)Vishnu RajasekharОценок пока нет