Вам также может понравиться
- AssigmentsДокумент12 страницAssigmentsShakuntala Khamesra100% (1)
- Introduction To Rewriting and Functional ProgrammingДокумент355 страницIntroduction To Rewriting and Functional ProgrammingcluxОценок пока нет
- A-level Maths Revision: Cheeky Revision ShortcutsОт EverandA-level Maths Revision: Cheeky Revision ShortcutsРейтинг: 3.5 из 5 звезд3.5/5 (8)
- XAct ParisДокумент114 страницXAct ParismadhavanrajagopalОценок пока нет
- Numerical Analysis and Computing: OutlineДокумент6 страницNumerical Analysis and Computing: OutlineAshoka VanjareОценок пока нет
- 10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon UniversityДокумент6 страниц10-701/15-781, Machine Learning: Homework 1: Aarti Singh Carnegie Mellon Universitytarun guptaОценок пока нет
- Convex Optimization For Machine LearningДокумент110 страницConvex Optimization For Machine LearningratnadeepbimtacОценок пока нет
- Multivariate Distributions: Why Random Vectors?Документ14 страницMultivariate Distributions: Why Random Vectors?Michael GarciaОценок пока нет
- Course 8 Chapter 5 - Approximation of Functions - InterpolationДокумент3 страницыCourse 8 Chapter 5 - Approximation of Functions - InterpolationIustin CristianОценок пока нет
- Economics N110, Game Theory in The Social Sciences: UC Berkeley, Summer 2012Документ23 страницыEconomics N110, Game Theory in The Social Sciences: UC Berkeley, Summer 2012sevtenОценок пока нет
- Declectures Non Linear EquationsДокумент23 страницыDeclectures Non Linear EquationsAdeniji OlusegunОценок пока нет
- Probabilities For Machine Learning: Roland MemisevicДокумент19 страницProbabilities For Machine Learning: Roland MemisevicDenno SteinОценок пока нет
- The Polynomials: 0 1 2 2 N N 0 1 2 N NДокумент29 страницThe Polynomials: 0 1 2 2 N N 0 1 2 N NKaran100% (1)
- L3 Linear RegressionДокумент23 страницыL3 Linear RegressionHieu Tien TrinhОценок пока нет
- dm1 - Problem Set - 4 - 2023 AutumnДокумент3 страницыdm1 - Problem Set - 4 - 2023 Autumncooldana44Оценок пока нет
- Physics 509: Numerical Methods For Bayesian Analyses: Scott Oser Lecture #15 November 4, 2008Документ32 страницыPhysics 509: Numerical Methods For Bayesian Analyses: Scott Oser Lecture #15 November 4, 2008OmegaUserОценок пока нет
- SGM With Random FeaturesДокумент25 страницSGM With Random Featuresidan kahanОценок пока нет
- Master Qfin at Wu Vienna Lecture Optimization: R Udiger FreyДокумент28 страницMaster Qfin at Wu Vienna Lecture Optimization: R Udiger FreyBruno GasperovОценок пока нет
- 1.limits and ContinuityДокумент29 страниц1.limits and ContinuitySyahirbanun Isa100% (1)
- Op Tim Ization ProblemДокумент103 страницыOp Tim Ization ProblemEmin Bekir AltunbaşОценок пока нет
- 03-The Fundamentals - Algorithms - IntegersДокумент54 страницы03-The Fundamentals - Algorithms - Integerstungnt26999Оценок пока нет
- Practice MidtermДокумент8 страницPractice MidtermOlabiyi RidwanОценок пока нет
- Precalculus I: Quadratic FunctionsДокумент28 страницPrecalculus I: Quadratic FunctionsSONITAОценок пока нет
- Solving Polynomial SystemsДокумент164 страницыSolving Polynomial SystemsChristophe LauwerysОценок пока нет
- Namma Kalvi - 12th - Business - Maths - Application - Answers - Volume - 2 - 215831Документ16 страницNamma Kalvi - 12th - Business - Maths - Application - Answers - Volume - 2 - 215831satish ThamizharОценок пока нет
- M 1 U 2 Quadratic FunctionsДокумент71 страницаM 1 U 2 Quadratic Functionsapi-263670707Оценок пока нет
- Lecture # 3 Derivative of Polynomials and Exponential Functions Dr. Ghada AbdelhadyДокумент32 страницыLecture # 3 Derivative of Polynomials and Exponential Functions Dr. Ghada AbdelhadyEsraa AhmadОценок пока нет
- 31 1 Poly ApproxДокумент18 страниц31 1 Poly ApproxPatrick SibandaОценок пока нет
- FuzzyДокумент38 страницFuzzytidjani86Оценок пока нет
- Probability For Ai2Документ8 страницProbability For Ai2alphamale173Оценок пока нет
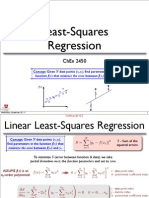
- Least-Squares Regression: Chen 2450Документ12 страницLeast-Squares Regression: Chen 2450mfelzienОценок пока нет
- Introduction Statistics Imperial College LondonДокумент474 страницыIntroduction Statistics Imperial College Londoncmtinv50% (2)
- Q3 Mathematics Peer Tutoring: Students' Advisory BoardДокумент93 страницыQ3 Mathematics Peer Tutoring: Students' Advisory BoardKiminiОценок пока нет
- CrapДокумент8 страницCrapvincentliu11Оценок пока нет
- Solving Algebraic Inequalities: January 1999Документ15 страницSolving Algebraic Inequalities: January 1999lk;kdОценок пока нет
- Lecture5 Fuzzy LogicДокумент86 страницLecture5 Fuzzy LogicAnshul PatodiОценок пока нет
- S1) Basic Probability ReviewДокумент71 страницаS1) Basic Probability ReviewMAYANK HARSANIОценок пока нет
- Chapter 7Документ24 страницыChapter 7Muhammad KamranОценок пока нет
- Introduction To Fuzzy Set TheoryДокумент67 страницIntroduction To Fuzzy Set TheoryLini IckappanОценок пока нет
- Final Revision On Math For TOC Exam DifferentiationДокумент64 страницыFinal Revision On Math For TOC Exam Differentiationmohab harfoushОценок пока нет
- Unconstrained and Constrained Optimization Algorithms by Soman K.PДокумент166 страницUnconstrained and Constrained Optimization Algorithms by Soman K.PprasanthrajsОценок пока нет
- Lectures 1Документ98 страницLectures 1Shy RonnieОценок пока нет
- Simplex Method For Solving Linear Programming Problems With Fuzzy NumbersДокумент5 страницSimplex Method For Solving Linear Programming Problems With Fuzzy NumbersRosalin MalarОценок пока нет
- Calculation and Modelling of Radar Performance 4 Fourier TransformsДокумент25 страницCalculation and Modelling of Radar Performance 4 Fourier TransformsmmhoriiОценок пока нет
- Basic Probability ReviewДокумент77 страницBasic Probability Reviewcoolapple123Оценок пока нет
- Algebra 2 Chapter 8Документ31 страницаAlgebra 2 Chapter 8Nguyễn TrâmОценок пока нет
- Lab 00 IntroMATLAB2 PDFДокумент11 страницLab 00 IntroMATLAB2 PDF'Jph Flores BmxОценок пока нет
- An Introduction To Variational Calculus in Machine LearningДокумент7 страницAn Introduction To Variational Calculus in Machine LearningAlexandersierraОценок пока нет
- Revision - Elements or Probability: Notation For EventsДокумент20 страницRevision - Elements or Probability: Notation For EventsAnthony Saracasmo GerdesОценок пока нет
- CH 5 HandoutДокумент55 страницCH 5 HandoutgabyssinieОценок пока нет
- MCMC BriefДокумент69 страницMCMC Briefjakub_gramolОценок пока нет
- Arafe Mayanga XI - MeadДокумент16 страницArafe Mayanga XI - Meadrafi mayangaОценок пока нет
- Probability and Stats NotesДокумент14 страницProbability and Stats NotesMichael GarciaОценок пока нет
- An Instability Result To A Certain Vector Differential Equation of The Sixth OrderДокумент4 страницыAn Instability Result To A Certain Vector Differential Equation of The Sixth OrderChernet TugeОценок пока нет
- Applied Econometrics: Department of Economics Stern School of BusinessДокумент27 страницApplied Econometrics: Department of Economics Stern School of BusinesschatfieldlohrОценок пока нет
- Functions Sequences, Sums, Countability: Zeph GrunschlagДокумент61 страницаFunctions Sequences, Sums, Countability: Zeph GrunschlagChandra Sekhar DОценок пока нет
- Convex Optimization Overview (CNT'D) : 1 RecapДокумент15 страницConvex Optimization Overview (CNT'D) : 1 RecapGeorge SakrОценок пока нет
- 3.1 Graphs of Polynomial FunctionsДокумент17 страниц3.1 Graphs of Polynomial FunctionsKristel Ann AgcaoiliОценок пока нет
- Chapter 1-Work Study Mikell GrooverДокумент28 страницChapter 1-Work Study Mikell GrooverHéctor F BonillaОценок пока нет
- Takt Time Vs Cycle TimeДокумент6 страницTakt Time Vs Cycle TimeHéctor F BonillaОценок пока нет
- Mapping The Value StreamДокумент8 страницMapping The Value StreamMahipal Singh RatnuОценок пока нет
- Lean Manufacturing CaseДокумент1 страницаLean Manufacturing CaseHéctor F BonillaОценок пока нет
- Value Stream MappingДокумент68 страницValue Stream MappingGautam VsОценок пока нет
- Value Stream MappingДокумент68 страницValue Stream MappingGautam VsОценок пока нет
- Takt Time Vs Cycle TimeДокумент6 страницTakt Time Vs Cycle TimeHéctor F BonillaОценок пока нет
- Articulo Y Chao 1985 Nuclear Science and EngineeringДокумент7 страницArticulo Y Chao 1985 Nuclear Science and EngineeringHéctor F BonillaОценок пока нет
- Comments On The Savitzky Golay Convolution Method For Least Squares Fit Smoothing and Differentiation of Digital DataДокумент4 страницыComments On The Savitzky Golay Convolution Method For Least Squares Fit Smoothing and Differentiation of Digital DataHéctor F BonillaОценок пока нет
- Takt Time Calculation: Exercise SolutionДокумент1 страницаTakt Time Calculation: Exercise SolutionHéctor F BonillaОценок пока нет
- 1999 01 1635SAEImportanceofTaktTimeinMSDДокумент9 страниц1999 01 1635SAEImportanceofTaktTimeinMSDHéctor F BonillaОценок пока нет
- Work Study IntroductionДокумент36 страницWork Study IntroductionHéctor F BonillaОценок пока нет
- 1999 01 1635SAEImportanceofTaktTimeinMSDДокумент9 страниц1999 01 1635SAEImportanceofTaktTimeinMSDHéctor F BonillaОценок пока нет
- Looking at This Value Stream Map, Do Your Own Considerations. Then, Draw "Yamazumi Chart" and Evaluate StaffingДокумент1 страницаLooking at This Value Stream Map, Do Your Own Considerations. Then, Draw "Yamazumi Chart" and Evaluate StaffingHéctor F BonillaОценок пока нет
- Chapter 1-Work Study Mikell GrooverДокумент28 страницChapter 1-Work Study Mikell GrooverHéctor F BonillaОценок пока нет
- Journal of Operations Management Volume 9 Issue 2 1990 (Doi 10.1016/0272-6963 (90) 90098-x) Barbara B. Flynn Sadao Sakakibara Roger G. Schroeder Kimberly - Empirical Research Methods in OperatДокумент35 страницJournal of Operations Management Volume 9 Issue 2 1990 (Doi 10.1016/0272-6963 (90) 90098-x) Barbara B. Flynn Sadao Sakakibara Roger G. Schroeder Kimberly - Empirical Research Methods in OperatHéctor F BonillaОценок пока нет
- International Journal of Production Economics Volume 150 Issue 2014 (Doi 10.1016/j.ijpe.2013.11.016) Sodhi, ManMohan S. Tang, Christopher S. - Guiding The Next Generation of Doctoral Students in oДокумент9 страницInternational Journal of Production Economics Volume 150 Issue 2014 (Doi 10.1016/j.ijpe.2013.11.016) Sodhi, ManMohan S. Tang, Christopher S. - Guiding The Next Generation of Doctoral Students in oHéctor F BonillaОценок пока нет
- Poly NetsДокумент23 страницыPoly NetsHéctor F BonillaОценок пока нет
- Structural Equation ModelingДокумент16 страницStructural Equation ModelingWaqas Yunus ChaudhryОценок пока нет
- BrochureДокумент21 страницаBrochureHimraj BachooОценок пока нет
- Eviews 7.0 ManualДокумент108 страницEviews 7.0 ManualNuur AhmedОценок пока нет
- L9 Strong DualityДокумент71 страницаL9 Strong DualityHéctor F BonillaОценок пока нет
- Persson 03 SmoothingДокумент15 страницPersson 03 SmoothingHéctor F BonillaОценок пока нет
- RK ImplicitoДокумент31 страницаRK ImplicitoHéctor F BonillaОценок пока нет
- SVDДокумент75 страницSVDHéctor F BonillaОценок пока нет
- Journal of Physics A Mathematical and General 2002 Vol. 35 (14) p3245Документ20 страницJournal of Physics A Mathematical and General 2002 Vol. 35 (14) p3245Héctor F BonillaОценок пока нет
- Hayes ThesisДокумент60 страницHayes ThesisHéctor F BonillaОценок пока нет
- Lecture Notes 2 1 Probability InequalitiesДокумент9 страницLecture Notes 2 1 Probability InequalitiesHéctor F BonillaОценок пока нет
- Solucionario Econometría Jeffrey M. WooldridgeДокумент4 страницыSolucionario Econometría Jeffrey M. WooldridgeHéctor F Bonilla3% (30)
- Instrumento Estandarizado de Identificación de Beneficiarios para Programas SocialesДокумент42 страницыInstrumento Estandarizado de Identificación de Beneficiarios para Programas SocialesRicardo CordovaОценок пока нет
- Direct Manipulation BlendshapesДокумент9 страницDirect Manipulation BlendshapesfanimateОценок пока нет
- Least Squares Data Fitting With ApplicationsДокумент175 страницLeast Squares Data Fitting With Applicationswolgast09durden1m20% (1)
- Least Square FitДокумент16 страницLeast Square FitMuhammad Awais100% (1)
- Matlab 3Документ42 страницыMatlab 3Husam AL-QadasiОценок пока нет
- Ps 1Документ5 страницPs 1Rahul AgarwalОценок пока нет
- Assignment Matrix DecompositionДокумент9 страницAssignment Matrix DecompositionNoyeem MahbubОценок пока нет
- Methods of Time SeriesДокумент12 страницMethods of Time SeriesSntn UaОценок пока нет
- FdidentДокумент232 страницыFdidentJpkovalchukОценок пока нет
- Geostatistics Formula SheetДокумент2 страницыGeostatistics Formula SheetcmollinedoaОценок пока нет
- Mathematica Laboratories For Mathematical StatisticsДокумент26 страницMathematica Laboratories For Mathematical Statisticshammoudeh13Оценок пока нет
- Chap 7Документ35 страницChap 7Nizar TayemОценок пока нет
- Multiple and Partial Correlation: R 1 R R RДокумент3 страницыMultiple and Partial Correlation: R 1 R R RHItesh KhuranaОценок пока нет
- Latest PG-Process Control 2008-09Документ32 страницыLatest PG-Process Control 2008-09MAX PAYNEОценок пока нет
- 2.fitting of Curves and ParabolaДокумент9 страниц2.fitting of Curves and ParabolaShubham100% (2)
- Numerical Method For Engineers-Chapter 20Документ46 страницNumerical Method For Engineers-Chapter 20Mrbudakbaek100% (1)
- Determination of Three Dimensional Velocity Anomalies Under A Seismic Array Using First P Arrival Times From Local Earthquakes (Aki 1976)Документ19 страницDetermination of Three Dimensional Velocity Anomalies Under A Seismic Array Using First P Arrival Times From Local Earthquakes (Aki 1976)María Angélica Garcia GiraldoОценок пока нет
- Fluid Structure InteractionДокумент276 страницFluid Structure InteractionJohn KingОценок пока нет
- Assignment 1Документ4 страницыAssignment 101689373477Оценок пока нет
- Application of Ordinary Least Square Method in NonlinearДокумент4 страницыApplication of Ordinary Least Square Method in NonlinearEnyОценок пока нет
- Error EdmДокумент22 страницыError EdmFaizan FathizanОценок пока нет
- Opencv C++ OnlyДокумент400 страницOpencv C++ Onlyd-fbuser-119595565Оценок пока нет
- Matlab Optimization Toolbox: Most Materials Are Obtained From Matlab WebsiteДокумент12 страницMatlab Optimization Toolbox: Most Materials Are Obtained From Matlab WebsiteAbhijit HavalОценок пока нет
- Curve FittingДокумент37 страницCurve FittingToddharris100% (4)
- Multi-Way Analysis in The Food IndustryДокумент311 страницMulti-Way Analysis in The Food Industryekalhor6410100% (1)
- Fundamentals of Statistical Signal Processing - Estimation Theory-KayДокумент303 страницыFundamentals of Statistical Signal Processing - Estimation Theory-KayferdiОценок пока нет
- Error AnalysisДокумент16 страницError AnalysisRocco CampagnaОценок пока нет
- System IdentificationДокумент646 страницSystem IdentificationMohamed Mamdouh100% (2)
- Introduction To Matlab Tutorial 11Документ37 страницIntroduction To Matlab Tutorial 11James Edward TrollopeОценок пока нет
- Least Squares Full ResumeДокумент15 страницLeast Squares Full ResumeseñalesuisОценок пока нет