Вам также может понравиться
- Data Acquisition MethodsДокумент19 страницData Acquisition MethodsMohamed aboalyОценок пока нет
- Lect6 DFD TutorialДокумент4 страницыLect6 DFD TutorialArunabha SenguptaОценок пока нет
- Phase Three Project ReportДокумент2 страницыPhase Three Project ReportBob PatelОценок пока нет
- Mu-Fashion: Multi-Resolution Data Fusion Using Agent-Bearing Sensors in Hierarchically-Organized NetworksДокумент33 страницыMu-Fashion: Multi-Resolution Data Fusion Using Agent-Bearing Sensors in Hierarchically-Organized NetworkshaddanОценок пока нет
- IntroductionOpenSees PDFДокумент27 страницIntroductionOpenSees PDFali381Оценок пока нет
- Lecture 4: Term Weighting and The Vector Space Model: Information Retrieval Computer Science Tripos Part IIДокумент62 страницыLecture 4: Term Weighting and The Vector Space Model: Information Retrieval Computer Science Tripos Part IIBemenet BiniyamОценок пока нет
- PostgresChina2018 刘东明 PostgreSQL并行查询Документ36 страницPostgresChina2018 刘东明 PostgreSQL并行查询Thoa NhuОценок пока нет
- IR Models: - Why IR Models? - Boolean IR Model - Vector Space IR Model - Probabilistic IR ModelДокумент46 страницIR Models: - Why IR Models? - Boolean IR Model - Vector Space IR Model - Probabilistic IR Modelkerya ibrahimОценок пока нет
- DS Data Structures OverviewДокумент127 страницDS Data Structures Overviewkarri maheswarОценок пока нет
- 9 Hadoop PDFДокумент59 страниц9 Hadoop PDFAmine HamdouchiОценок пока нет
- Lab Manual 3112Документ11 страницLab Manual 3112Tahamid Hasan.Оценок пока нет
- Discovery of Similarity Computations of Search Engines: King-Lup Liu Weiyi Meng Clement YuДокумент8 страницDiscovery of Similarity Computations of Search Engines: King-Lup Liu Weiyi Meng Clement YupostscriptОценок пока нет
- CBIR Papers For PHDДокумент7 страницCBIR Papers For PHDkalpesh_chandakОценок пока нет
- Query Processing + Optimization: Outline: Operator Evaluation StrategiesДокумент53 страницыQuery Processing + Optimization: Outline: Operator Evaluation StrategiesAnupam DubeyОценок пока нет
- Databricks: Building and Operating A Big Data Service Based On Apache SparkДокумент32 страницыDatabricks: Building and Operating A Big Data Service Based On Apache SparkSaravanan1234567Оценок пока нет
- Software Random Number Generation Based On Race ConditionsДокумент7 страницSoftware Random Number Generation Based On Race ConditionsCHRISTIAN ANDRES ESPINOZAОценок пока нет
- 2052 PLMEurope 24.10.17-17-30 BALASUNDARAM-KANTHI INTELIZIGN ENGINEERING SERV Active Workspace For External Data Aggregation and SearchДокумент18 страниц2052 PLMEurope 24.10.17-17-30 BALASUNDARAM-KANTHI INTELIZIGN ENGINEERING SERV Active Workspace For External Data Aggregation and SearchAbhilash RavindranОценок пока нет
- Introduction To Datawarehousing: Duration: 45 Minutes (Approx.) Abhishek RanjanДокумент32 страницыIntroduction To Datawarehousing: Duration: 45 Minutes (Approx.) Abhishek RanjanbabjeereddyОценок пока нет
- Jesus A. Gonzalez Supervisor: Dr. Lawrence B. Holder Committee: Dr. Diane J. Cook Dr. Lynn PetersonДокумент35 страницJesus A. Gonzalez Supervisor: Dr. Lawrence B. Holder Committee: Dr. Diane J. Cook Dr. Lynn Petersonmeloz85Оценок пока нет
- DS20 ALL OverviewДокумент88 страницDS20 ALL OverviewMouhcine MohammedОценок пока нет
- Cross-Language Information Retrieval (CLIR) : Ananthakrishnan RДокумент32 страницыCross-Language Information Retrieval (CLIR) : Ananthakrishnan RBapuji ValabojuОценок пока нет
- Recall, PrecisionДокумент7 страницRecall, PrecisionSugi HartonoОценок пока нет
- WurstДокумент31 страницаWurstJohn SlorОценок пока нет
- IR Ch23 Text RepresentationДокумент36 страницIR Ch23 Text RepresentationBushra MamoudОценок пока нет
- Syngistix Results Library DescriptionДокумент35 страницSyngistix Results Library DescriptionMOHAMMAD AMIRUL ASSYRAF MOHAMMAD NOORОценок пока нет
- Optimizing Multi-Dimensional Data-Index Algorithms For Mic ArchitecturesДокумент7 страницOptimizing Multi-Dimensional Data-Index Algorithms For Mic ArchitecturesInternational Journal of Innovative Science and Research TechnologyОценок пока нет
- S : On Synthesis of Program Analyzers: Ouffl EДокумент7 страницS : On Synthesis of Program Analyzers: Ouffl ETsumeAwaseОценок пока нет
- Lecture 1 Parallel DatabasesДокумент30 страницLecture 1 Parallel DatabasesKumkumo Kussia KossaОценок пока нет
- Analysis of Multiple Experiments Tigr Multiple Experiment Viewer (Mev)Документ130 страницAnalysis of Multiple Experiments Tigr Multiple Experiment Viewer (Mev)Sajna RajthalaОценок пока нет
- Performance Comparison of Different Sort PDFДокумент3 страницыPerformance Comparison of Different Sort PDFmax craxОценок пока нет
- oreillyfodooltweek11675274112220Документ45 страницoreillyfodooltweek11675274112220sanedo.ownerОценок пока нет
- Parallel and Distributed IR Techniques for Large-Scale Document CollectionsДокумент24 страницыParallel and Distributed IR Techniques for Large-Scale Document CollectionsSuvetha SenguttuvanОценок пока нет
- Getting Started With IPДокумент15 страницGetting Started With IPLexa ZcОценок пока нет
- IRS Unit-3Документ32 страницыIRS Unit-3Nagendra MarisettiОценок пока нет
- Lec7 PDFДокумент16 страницLec7 PDFRabia ChaudharyОценок пока нет
- The Future of Real-Time in Spark: Reynold Xin @rxinДокумент30 страницThe Future of Real-Time in Spark: Reynold Xin @rxinzameerОценок пока нет
- Tensor FPGAДокумент24 страницыTensor FPGAdreadrebirth2342Оценок пока нет
- Parallel Programming Session 1Документ27 страницParallel Programming Session 1cilango1Оценок пока нет
- RIoTBench SummaryДокумент26 страницRIoTBench SummarybushraNazirОценок пока нет
- Dimension Projection Matrix/Tree: Interactive Subspace Visual Exploration and Analysis of High Dimensional DataДокумент9 страницDimension Projection Matrix/Tree: Interactive Subspace Visual Exploration and Analysis of High Dimensional DataAni AniОценок пока нет
- Joke Recommendation Systems Using SVD and Text SimilarityДокумент6 страницJoke Recommendation Systems Using SVD and Text SimilarityGustavo LuizonОценок пока нет
- Low-Latency Multi-Threaded Ensemble Learning For Dynamic Big Data StreamsДокумент10 страницLow-Latency Multi-Threaded Ensemble Learning For Dynamic Big Data StreamsashinantonyОценок пока нет
- Cactus Project & Collaborative WorkingДокумент11 страницCactus Project & Collaborative WorkingAnkit SinghОценок пока нет
- Distributed Indexing and SearchingДокумент28 страницDistributed Indexing and SearchingBlack KnightОценок пока нет
- Module 4 Data ManipulationДокумент19 страницModule 4 Data ManipulationRachell Ann UsonОценок пока нет
- OAC 105.4 Selected New Features: Draft V2Документ23 страницыOAC 105.4 Selected New Features: Draft V2nandakarsanОценок пока нет
- CS3361 - Data Science LaboratoryДокумент31 страницаCS3361 - Data Science Laboratoryparanjothi karthikОценок пока нет
- dm9 DDBДокумент52 страницыdm9 DDBbangkit sitohangОценок пока нет
- BCS TopicДокумент66 страницBCS TopicShahidUmarОценок пока нет
- Multi-Agent System For Documents Retrieval and Evaluation Using Fuzzy Inference SystemsДокумент7 страницMulti-Agent System For Documents Retrieval and Evaluation Using Fuzzy Inference SystemsIAES IJAIОценок пока нет
- Abstraction and Modular Reasoning For The Verification of SoftwareДокумент44 страницыAbstraction and Modular Reasoning For The Verification of SoftwareLamiss HamdОценок пока нет
- IR Basics Lec28 Oct 3 2011Документ26 страницIR Basics Lec28 Oct 3 2011Mathesh ParamasivamОценок пока нет
- Azure Data Factory Data Flows: A Code-Free Approach to Data Transformation at ScaleДокумент30 страницAzure Data Factory Data Flows: A Code-Free Approach to Data Transformation at ScaleBabu Shaikh100% (1)
- Monitoring Docker Containers With Splunk PDFДокумент33 страницыMonitoring Docker Containers With Splunk PDFbobwillmoreОценок пока нет
- RAG Slide ENGДокумент41 страницаRAG Slide ENGWellcareОценок пока нет
- Training Objectives & Architectures: Bert, GPT, T5, Bart & Xlnet: Comprehensively ComparedДокумент36 страницTraining Objectives & Architectures: Bert, GPT, T5, Bart & Xlnet: Comprehensively ComparedFILALI HOUCEMEDDINEОценок пока нет
- TCS DynatraceTrainingДокумент127 страницTCS DynatraceTrainingSreenivasulu Reddy Sanam100% (2)
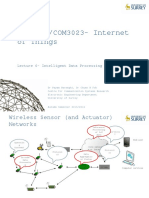
- EEEM048/COM3023-Internet of Things: Lecture 6 - Intelligent Data ProcessingДокумент40 страницEEEM048/COM3023-Internet of Things: Lecture 6 - Intelligent Data ProcessingPV sushmithaОценок пока нет
- Modern Information Retrieval: A Brief Overview: by Amit SinghalДокумент14 страницModern Information Retrieval: A Brief Overview: by Amit Singhalapi-20013624Оценок пока нет
- Relevance Ranking and Relevance Feedback: Carl StaelinДокумент34 страницыRelevance Ranking and Relevance Feedback: Carl Staelinapi-20013624Оценок пока нет
- CSCI 7000 Modern Information Retrieval Jim MartinДокумент36 страницCSCI 7000 Modern Information Retrieval Jim Martinapi-20013624Оценок пока нет
- CSCI 7000 Modern Information Retrieval: Lecture 1: IntroductionДокумент16 страницCSCI 7000 Modern Information Retrieval: Lecture 1: Introductionapi-20013624Оценок пока нет
- Modern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-NetoДокумент40 страницModern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-Netoapi-20013624Оценок пока нет
- Modern Information Retrieval: A Brief OverviewДокумент9 страницModern Information Retrieval: A Brief Overviewapi-20013624Оценок пока нет
- cs419-519 Slides Part 2Документ6 страницcs419-519 Slides Part 2api-20013624Оценок пока нет
- Conceptual Structures in Modern Information Retrieval: Claudio CarpinetoДокумент28 страницConceptual Structures in Modern Information Retrieval: Claudio Carpinetoapi-20013624Оценок пока нет
- Prayer of SubmissionДокумент3 страницыPrayer of SubmissionLindaLindyОценок пока нет
- A P1qneer 1n Neuroscience: Rita Levi-MontalciniДокумент43 страницыA P1qneer 1n Neuroscience: Rita Levi-MontalciniAntОценок пока нет
- Inner Ear Balance ProblemsДокумент6 страницInner Ear Balance ProblemsaleiyoОценок пока нет
- Sexual ExtacyДокумент18 страницSexual ExtacyChal JhonnyОценок пока нет
- 4 5994641624901094407Документ20 страниц4 5994641624901094407Success100% (1)
- A Better Kiln CoatingДокумент2 страницыA Better Kiln Coatingamir100% (4)
- F2970.1558734-1 Trampoline CourtДокумент22 страницыF2970.1558734-1 Trampoline CourtKannan LakshmananОценок пока нет
- ZetaPlus EXT SP Series CДокумент5 страницZetaPlus EXT SP Series Cgeorgadam1983Оценок пока нет
- OE & HS Subjects 2018-19Документ94 страницыOE & HS Subjects 2018-19bharath hsОценок пока нет
- Handout Week10.1Документ7 страницHandout Week10.1Antoniette Niña YusonОценок пока нет
- Burning Arduino Bootloader With AVR USBASP PDFДокумент6 страницBurning Arduino Bootloader With AVR USBASP PDFxem3Оценок пока нет
- Embodied experience at the core of Performance StudiesДокумент10 страницEmbodied experience at the core of Performance StudiesVictor Bobadilla ParraОценок пока нет
- Ford Taurus Service Manual - Disassembly and Assembly - Automatic Transaxle-Transmission - 6F35 - Automatic Transmission - PowertrainДокумент62 страницыFord Taurus Service Manual - Disassembly and Assembly - Automatic Transaxle-Transmission - 6F35 - Automatic Transmission - Powertraininfocarsservice.deОценок пока нет
- Jyothy Fabricare Services Ltd. - Word)Документ64 страницыJyothy Fabricare Services Ltd. - Word)sree02nair88100% (1)
- Key concepts in biology examДокумент19 страницKey concepts in biology examAditya RaiОценок пока нет
- Equilibrium of Supply and DemandДокумент4 страницыEquilibrium of Supply and DemandJuina Mhay Baldillo ChunacoОценок пока нет
- The Biologic Width: - A Concept in Periodontics and Restorative DentistryДокумент8 страницThe Biologic Width: - A Concept in Periodontics and Restorative DentistryDrKrishna DasОценок пока нет
- SPXДокумент6 страницSPXapi-3700460Оценок пока нет
- Handout 4-6 StratДокумент6 страницHandout 4-6 StratTrixie JordanОценок пока нет
- Lesson Plan For DemoДокумент7 страницLesson Plan For DemoShiela Tecson GamayonОценок пока нет
- Revit Mep Vs Autocad MepДокумент4 страницыRevit Mep Vs Autocad MepAbdelhameed Tarig AlemairyОценок пока нет
- Axial and Appendicular Muscles GuideДокумент10 страницAxial and Appendicular Muscles GuideYasmeen AlnajjarОценок пока нет
- Tectonics, Vol. 8, NO. 5, PAGES 1015-1036, October 1989Документ22 страницыTectonics, Vol. 8, NO. 5, PAGES 1015-1036, October 1989atoinsepeОценок пока нет
- KoL Mekflu - 9Документ104 страницыKoL Mekflu - 9Maha D NugrohoОценок пока нет
- Parameter Pengelasan SMAW: No Bahan Diameter Ampere Polaritas Penetrasi Rekomendasi Posisi PengguanaanДокумент2 страницыParameter Pengelasan SMAW: No Bahan Diameter Ampere Polaritas Penetrasi Rekomendasi Posisi PengguanaanKhamdi AfandiОценок пока нет
- Sujet Dissertation Sciences PolitiquesДокумент7 страницSujet Dissertation Sciences PolitiquesDoMyPaperSingapore100% (1)
- Clare Redman Statement of IntentДокумент4 страницыClare Redman Statement of Intentapi-309923259Оценок пока нет
- BC C Punmia BeamДокумент14 страницBC C Punmia BeamvikrantgoudaОценок пока нет
- Introduction to Philippine LiteratureДокумент61 страницаIntroduction to Philippine LiteraturealvindadacayОценок пока нет
- Alcatel 350 User Guide FeaturesДокумент4 страницыAlcatel 350 User Guide FeaturesFilipe CardosoОценок пока нет