Вам также может понравиться
- Mathematics Education in Japan Before and After the Meiji RestorationДокумент9 страницMathematics Education in Japan Before and After the Meiji Restorationcharan__Оценок пока нет
- Costs For Architecture StudentsДокумент1 страницаCosts For Architecture StudentstoffunОценок пока нет
- FDI Policy of Japan and Screening MechanismДокумент22 страницыFDI Policy of Japan and Screening Mechanismcharan__Оценок пока нет
- WTC BookДокумент40 страницWTC BookCrăciun RalucaОценок пока нет
- Moment Curvature Relationships and DuctiДокумент72 страницыMoment Curvature Relationships and Ducticharan__Оценок пока нет
- UPDATED Architecture Admissions Assessment Specification 2016Документ3 страницыUPDATED Architecture Admissions Assessment Specification 2016charan__Оценок пока нет
- Matplotlib LicenseДокумент1 страницаMatplotlib Licensecharan__Оценок пока нет
- NewДокумент26 страницNewcharan__Оценок пока нет
- Construction Materials Hw2 q1 - 1Документ10 страницConstruction Materials Hw2 q1 - 1charan__Оценок пока нет
- Design ExercisesДокумент20 страницDesign Exercisescharan__Оценок пока нет
- Hydraulic EngineeringДокумент8 страницHydraulic Engineeringcharan__Оценок пока нет
- Gradiance Online Accelerated Learning 2Документ3 страницыGradiance Online Accelerated Learning 2charan__Оценок пока нет
- (Architecture Ebook) Architectural Thought - The Design Process and The Expectant EyeДокумент191 страница(Architecture Ebook) Architectural Thought - The Design Process and The Expectant EyeMike Sathorar100% (3)
- Gradiance Online Accelerated Learning 3Документ3 страницыGradiance Online Accelerated Learning 3charan__Оценок пока нет
- The Shape of DesignДокумент121 страницаThe Shape of DesignwillburdetteОценок пока нет
- Environmental Chemistry: Anthropogenic: Resulting From The Influence of Human Beings On NatureДокумент7 страницEnvironmental Chemistry: Anthropogenic: Resulting From The Influence of Human Beings On Naturecharan__Оценок пока нет
- Introduction To HTML 5Документ110 страницIntroduction To HTML 5api-25966377100% (3)
- CONCRETE (2nd Edition)Документ657 страницCONCRETE (2nd Edition)charan__100% (5)
- JavascriptДокумент27 страницJavascriptLuis Esteban RodríguezОценок пока нет
- The Shape of DesignДокумент121 страницаThe Shape of DesignwillburdetteОценок пока нет
- INTRODUCTORY PROBABILITY AND STATISTICAL APPLICATIONS (2nd Edition)Документ195 страницINTRODUCTORY PROBABILITY AND STATISTICAL APPLICATIONS (2nd Edition)charan__100% (7)
- Logo and Brand Identity Guidelines Template PDFДокумент8 страницLogo and Brand Identity Guidelines Template PDFÁngel HerdoraОценок пока нет
- Uxpin The Guide To WireframingДокумент118 страницUxpin The Guide To WireframingmsipcОценок пока нет
- Styling & Animating SVGsДокумент61 страницаStyling & Animating SVGscharan__100% (1)
- html5 css3 CheatsheetДокумент3 страницыhtml5 css3 Cheatsheetcharan__Оценок пока нет
- Git From Bottom UpДокумент31 страницаGit From Bottom UpMúsica Experimental A MallorcaОценок пока нет
- Concrete Technology, NEVILLE 2nd Edition Book PDFДокумент460 страницConcrete Technology, NEVILLE 2nd Edition Book PDFramya_an241183% (12)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
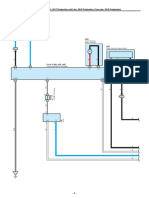
- EPS (TMT Made From Oct. 2017 Production Until Jan. 2018 Production, From Jan. 2018 Production)Документ8 страницEPS (TMT Made From Oct. 2017 Production Until Jan. 2018 Production, From Jan. 2018 Production)Angel Rodríguez100% (1)
- Sonata™: Dual Pulse OutputДокумент2 страницыSonata™: Dual Pulse OutputPra YugoОценок пока нет
- Lesson 1 PropositionДокумент5 страницLesson 1 Propositionrazel gicaleОценок пока нет
- Prooccore Traınıng5Документ13 страницProoccore Traınıng5ErkinОценок пока нет
- MAN KUKA A08 Glue Intec en PDFДокумент49 страницMAN KUKA A08 Glue Intec en PDFIan PfeiferОценок пока нет
- Imanager NetEco 1000S V100R003C00 Residential Quick GuideДокумент2 страницыImanager NetEco 1000S V100R003C00 Residential Quick GuideNoh AdrianОценок пока нет
- Introduction To Electronic System Design (DAT093) Lab 0: Tool and Task KickstarterДокумент8 страницIntroduction To Electronic System Design (DAT093) Lab 0: Tool and Task KickstarterDanil SidorovОценок пока нет
- DMBI SimplifiedДокумент28 страницDMBI SimplifiedRecaroОценок пока нет
- 180 VOLVO Codigos de Erros L60F L70F PDFДокумент180 страниц180 VOLVO Codigos de Erros L60F L70F PDFManuel casanova86% (7)
- Reasoning with Alphabet QuestionsДокумент6 страницReasoning with Alphabet QuestionsRitik KumarОценок пока нет
- Eprocurement: Andreas Meier & Luis TeránДокумент34 страницыEprocurement: Andreas Meier & Luis TeránAditya SharmaОценок пока нет
- GUT EIM Compro - 0114 - A4 - 2014-02-06Документ19 страницGUT EIM Compro - 0114 - A4 - 2014-02-06Bronoz GrypenОценок пока нет
- 2907-000Документ49 страниц2907-000swd14janОценок пока нет
- Rajamuhammadiskandar Cretev Revised Timesheet Oct 2023 2Документ1 страницаRajamuhammadiskandar Cretev Revised Timesheet Oct 2023 2Raja Muhammad IskandarОценок пока нет
- Nikola Tesla BiographyДокумент6 страницNikola Tesla BiographyDavid CristianОценок пока нет
- Curriculam Vitae: Ecoleaf Energies PVT - LTDДокумент4 страницыCurriculam Vitae: Ecoleaf Energies PVT - LTDJay Kumar BhattОценок пока нет
- Group Project GuidelinesДокумент3 страницыGroup Project GuidelinesAmer IkhwanОценок пока нет
- Jb371 7.0 Student GuideДокумент244 страницыJb371 7.0 Student GuideMarcelo LimaОценок пока нет
- Hydraulic TrainingДокумент132 страницыHydraulic TrainingJose Luis Rodriguez100% (3)
- Module 2 - Series DC MotorДокумент8 страницModule 2 - Series DC MotorMARY JOY MAGAWAYОценок пока нет
- MDU UIET 5TH SEM EE SyllabusДокумент59 страницMDU UIET 5TH SEM EE SyllabusKshitij TyagiОценок пока нет
- Lubrication & BearingsДокумент91 страницаLubrication & BearingsRohan SinghОценок пока нет
- X Ray Flat Panel Detector - MEDICALДокумент14 страницX Ray Flat Panel Detector - MEDICALatnafu takeleОценок пока нет
- PWC Mail - Re - Sign Off For Pending RICEFW's - Barcode InterfaceДокумент2 страницыPWC Mail - Re - Sign Off For Pending RICEFW's - Barcode InterfaceSagar Garg (IN)Оценок пока нет
- Plumbing, Electrical, and Building Material ListДокумент1 страницаPlumbing, Electrical, and Building Material Listarri valenОценок пока нет
- Detailed CET ListДокумент11 страницDetailed CET ListBhagya H SОценок пока нет
- Marina Mall Work Permit (20369)Документ1 страницаMarina Mall Work Permit (20369)Shahid FarooqОценок пока нет
- Conveyor Chains For Demanding ApplicationsДокумент24 страницыConveyor Chains For Demanding Applicationsnum0067Оценок пока нет
- Cameron HutchingsДокумент3 страницыCameron HutchingsUtku BayramОценок пока нет
- KUIZ ICT - 50 questions on computer technologyДокумент2 страницыKUIZ ICT - 50 questions on computer technologyTanicshaОценок пока нет