Вам также может понравиться
- Clustering and Classification in Support of Climatology To Mine Weather Data - A ReviewДокумент5 страницClustering and Classification in Support of Climatology To Mine Weather Data - A ReviewIntegrated Intelligent ResearchОценок пока нет
- Energies: Air Temperature Forecasting Using Machine Learning Techniques: A ReviewДокумент28 страницEnergies: Air Temperature Forecasting Using Machine Learning Techniques: A ReviewRakib RashidОценок пока нет
- Data Mining Technique To Analyse The Metrological DataДокумент5 страницData Mining Technique To Analyse The Metrological Datapitchrks19841Оценок пока нет
- KNN Technique For Analysis and Prediction of Temperature and Humidity DataДокумент7 страницKNN Technique For Analysis and Prediction of Temperature and Humidity DataJaineet ShahОценок пока нет
- Data Mining Techniques For Weather Prediction A ReviewДокумент6 страницData Mining Techniques For Weather Prediction A ReviewEditor IJRITCCОценок пока нет
- Clustering and Classification in Support of Climatology To Mine Weather Data - A ReviewДокумент4 страницыClustering and Classification in Support of Climatology To Mine Weather Data - A ReviewiirОценок пока нет
- Climate Change Prediction Using ARIMA ModelДокумент7 страницClimate Change Prediction Using ARIMA ModelIJRASETPublicationsОценок пока нет
- Rainfall Predictions Using Data Visualization TechniquesДокумент7 страницRainfall Predictions Using Data Visualization TechniquesIJRASETPublications100% (1)
- Weather Forecasting Using Decision Tree RegressionДокумент7 страницWeather Forecasting Using Decision Tree RegressionSoumya BishnuОценок пока нет
- Prediction and Classification of Weather Using Machine LearningДокумент8 страницPrediction and Classification of Weather Using Machine LearningIJRASETPublications100% (1)
- Literature 04Документ5 страницLiterature 04sameerkhaan96891Оценок пока нет
- Machine Learning Methods To Weather Forecasting To Predict Apparent TemperatureДокумент11 страницMachine Learning Methods To Weather Forecasting To Predict Apparent TemperatureIJRASETPublications100% (1)
- WeatherforecastingДокумент10 страницWeatherforecastingLoser To Winner100% (1)
- Rainfall Prediction System 2Документ6 страницRainfall Prediction System 2Salim AnsariОценок пока нет
- HHHHHHДокумент10 страницHHHHHHAnjali patelОценок пока нет
- Prediction Rainfall With Regression AnalysisДокумент12 страницPrediction Rainfall With Regression AnalysisIJRASETPublications100% (1)
- Weather ForecastingДокумент10 страницWeather ForecastingSisindri AkhilОценок пока нет
- Weather ForecastingДокумент10 страницWeather Forecastingaman daniОценок пока нет
- WeatherforecastingДокумент10 страницWeatherforecastingGaurav GhandatОценок пока нет
- A Survey On Weather Forecasting To Predict Rainfall Using Big DataДокумент8 страницA Survey On Weather Forecasting To Predict Rainfall Using Big DataSuraj SubramanianОценок пока нет
- Comparing Predictive Power in Climate Data: Clustering MattersДокумент17 страницComparing Predictive Power in Climate Data: Clustering Mattersdiana hertantiОценок пока нет
- Machine Learning Methods To Weather Forecasting To Predict Apparent Temperature A ReviewДокумент6 страницMachine Learning Methods To Weather Forecasting To Predict Apparent Temperature A ReviewIJRASETPublications100% (1)
- 244 PDFДокумент5 страниц244 PDFRaul Guillen CruzОценок пока нет
- Weatherforecasting PDFДокумент10 страницWeatherforecasting PDF20BCS1105 PoornimaОценок пока нет
- Shubham Litreature ReviewДокумент1 страницаShubham Litreature ReviewshubhaMОценок пока нет
- K-Means Clustering and Artificial Neural Network in Weather ForecastingДокумент5 страницK-Means Clustering and Artificial Neural Network in Weather ForecastingInternational Journal of Innovative Science and Research TechnologyОценок пока нет
- Computer Aided Technique For Energy EstimationДокумент4 страницыComputer Aided Technique For Energy EstimationAnonymous lPvvgiQjRОценок пока нет
- Environmental Temperature Prediction Using A Data Analysis and Neural Networks Methodological ApproachДокумент6 страницEnvironmental Temperature Prediction Using A Data Analysis and Neural Networks Methodological ApproachEvaluaciones UTNОценок пока нет
- 44 ArticleText 158 1 10 202202101Документ5 страниц44 ArticleText 158 1 10 202202101Srisha UdupaОценок пока нет
- Fin Irjmets1681823851Документ4 страницыFin Irjmets1681823851rrp.jhdpОценок пока нет
- A Study On Rainfall Prediction Techniques: December 2021Документ16 страницA Study On Rainfall Prediction Techniques: December 2021Suraj JadhavОценок пока нет
- Other DataДокумент11 страницOther Datawrushabh sirsatОценок пока нет
- Dynamic Modeling Technique For Weather Prediction: Jyotismita GoswamiДокумент8 страницDynamic Modeling Technique For Weather Prediction: Jyotismita GoswamiAsif ThokerОценок пока нет
- AReviewon Weather Forecastingusing Machine Learningand Deep Learning TechniquesДокумент6 страницAReviewon Weather Forecastingusing Machine Learningand Deep Learning TechniquesDouaa Moussaoui100% (1)
- Sample Paper IJRPRДокумент5 страницSample Paper IJRPRV D CharanОценок пока нет
- Weather Prediction Using Machine Learning TechniquessДокумент53 страницыWeather Prediction Using Machine Learning Techniquessbakiz89Оценок пока нет
- (IJCST-V10I2P14) :prof. A. D. Wankhade, Bhagyashri Jaiswal, Divya Gupta, Mahima Gadodiya, Sanket RautДокумент4 страницы(IJCST-V10I2P14) :prof. A. D. Wankhade, Bhagyashri Jaiswal, Divya Gupta, Mahima Gadodiya, Sanket RautEighthSenseGroupОценок пока нет
- Weather Prediction SystemДокумент17 страницWeather Prediction SystemSatyanarayan GuptaОценок пока нет
- Weather Forecast Prediction: A Data Mining Application: AbstractДокумент6 страницWeather Forecast Prediction: A Data Mining Application: AbstractsangaviОценок пока нет
- 10 1109@icesc48915 2020 9155571Документ4 страницы10 1109@icesc48915 2020 9155571Sushmitha ThulasimaniОценок пока нет
- Applsci 10 08237 v2Документ12 страницApplsci 10 08237 v2Ayesha ShahbazОценок пока нет
- Indo 122-S017Документ7 страницIndo 122-S017Stasiun Meteorologi Depati Amir PangkalpinangОценок пока нет
- Weather Forecasting - A Time Series Analysis Using RДокумент11 страницWeather Forecasting - A Time Series Analysis Using RRabiaОценок пока нет
- Edited DrJSKPaper2Документ9 страницEdited DrJSKPaper2Ahmed AmamouОценок пока нет
- Monitoring of Environmental Parameters by Using Cloud ComputingДокумент5 страницMonitoring of Environmental Parameters by Using Cloud ComputingnishaОценок пока нет
- Implementation of Data Mining Techniques For Meteorological Data AnalysisДокумент5 страницImplementation of Data Mining Techniques For Meteorological Data AnalysisArianto TariganОценок пока нет
- Machine Learning and Artificial Intelligence Models Development in Rainfall-Induced Landslide PredictionДокумент9 страницMachine Learning and Artificial Intelligence Models Development in Rainfall-Induced Landslide PredictionIAES IJAIОценок пока нет
- Literature 03Документ29 страницLiterature 03sameerkhaan96891Оценок пока нет
- 3Документ2 страницы3RahulОценок пока нет
- Big Data Analytics in Weather ForecastingДокумент29 страницBig Data Analytics in Weather ForecastingSangeeta YadavОценок пока нет
- Weather Forecast Prediction An Integrated ApproachДокумент6 страницWeather Forecast Prediction An Integrated ApproachNikita NawleОценок пока нет
- A Review On Weather Forecasting Techniques: IjarcceДокумент4 страницыA Review On Weather Forecasting Techniques: IjarcceAditya Singh RathiОценок пока нет
- AI ProjectДокумент30 страницAI ProjectTEJAS PRAKASH (RA2111003011356)Оценок пока нет
- CSE-873d MergedДокумент9 страницCSE-873d Mergedshivabasav s kОценок пока нет
- Measurement: Wen-Tsai Sung, Sung-Jung HsiaoДокумент16 страницMeasurement: Wen-Tsai Sung, Sung-Jung Hsiaoseyyed jamal mirjaliliОценок пока нет
- 10 1016@j Enbuild 2019 05 021Документ12 страниц10 1016@j Enbuild 2019 05 021اريج عليОценок пока нет
- Big Data and Climate Change: Hossein Hassani, Xu Huang and Emmanuel SilvaДокумент17 страницBig Data and Climate Change: Hossein Hassani, Xu Huang and Emmanuel SilvaBL OeiОценок пока нет
- Data Mining in The Prediction of Impacts of Ambient Air Quality Data Analysis in Urban and Industrial AreaДокумент5 страницData Mining in The Prediction of Impacts of Ambient Air Quality Data Analysis in Urban and Industrial AreaEditor IJRITCCОценок пока нет
- Ch03 Block Ciphers NemoДокумент50 страницCh03 Block Ciphers Nemopitchrks19841Оценок пока нет
- BEC Prelim - OverallДокумент9 страницBEC Prelim - Overallpitchrks19841Оценок пока нет
- Adhiparasakthi Engineering College: In-Plant Training Details ListДокумент5 страницAdhiparasakthi Engineering College: In-Plant Training Details Listpitchrks19841Оценок пока нет
- SSLC Maths 5 Model Question Papers English MediumДокумент21 страницаSSLC Maths 5 Model Question Papers English MediumscientistabbasОценок пока нет
- Application For Faculty PositionДокумент5 страницApplication For Faculty Positionpitchrks19841Оценок пока нет
- Performance Appraisal: Pe Rce NT Ag e of Ma RK SДокумент8 страницPerformance Appraisal: Pe Rce NT Ag e of Ma RK Spitchrks19841Оценок пока нет
- Performance Appraisal: Name of The Staff Percentage of MarksДокумент6 страницPerformance Appraisal: Name of The Staff Percentage of Markspitchrks19841Оценок пока нет
- Tree TwoДокумент1 страницаTree Twopitchrks19841Оценок пока нет
- Class/Sem: Ii A'/Iii: Omsakthi Adhiparasakthi Engineering College-Melmaruvathur Department of Information TechnologyДокумент12 страницClass/Sem: Ii A'/Iii: Omsakthi Adhiparasakthi Engineering College-Melmaruvathur Department of Information Technologypitchrks19841Оценок пока нет
- Part-A Answer All Question (7 2 14)Документ3 страницыPart-A Answer All Question (7 2 14)pitchrks19841Оценок пока нет
- Sliptest 2Документ2 страницыSliptest 2pitchrks19841Оценок пока нет
- Sivan Unit III TQMДокумент25 страницSivan Unit III TQMpitchrks19841Оценок пока нет
- Sivanunit I TQMДокумент12 страницSivanunit I TQMpitchrks19841Оценок пока нет
- Nike Inventory PDFДокумент12 страницNike Inventory PDFAzeem AhmadОценок пока нет
- Roberto MaglioneДокумент8 страницRoberto MaglioneC.K.Оценок пока нет
- Temperature Heat Transfer: AbsorptionДокумент4 страницыTemperature Heat Transfer: AbsorptionFredalyn Joy VelaqueОценок пока нет
- KD 3.3 Future Tense LMДокумент3 страницыKD 3.3 Future Tense LMAldeo ArifinОценок пока нет
- PRO-II Thermodynamic Model SelectionДокумент79 страницPRO-II Thermodynamic Model Selectionchemsac2100% (1)
- OPMДокумент25 страницOPMBenjamin Adelwini BugriОценок пока нет
- Production Book Template 2Документ28 страницProduction Book Template 2So AZ Cop WatchОценок пока нет
- Chap 6 Hydrograph 1415-IДокумент122 страницыChap 6 Hydrograph 1415-IkakmanОценок пока нет
- ALC Vocabulary Review Unit 5 Teacher'S Copy: Transcript Answer Key Alcvr Practice TestДокумент10 страницALC Vocabulary Review Unit 5 Teacher'S Copy: Transcript Answer Key Alcvr Practice TestKRATOS JEDDAH100% (1)
- Binary Logistic Regression and Its ApplicationДокумент8 страницBinary Logistic Regression and Its ApplicationFaisal IshtiaqОценок пока нет
- Regression AnalysisДокумент280 страницRegression AnalysisA.Benhari100% (1)
- Energy Demand Analysis and ForecastingДокумент36 страницEnergy Demand Analysis and ForecastingRam Krishna Singh100% (1)
- ECO Voyage Quick GuideДокумент19 страницECO Voyage Quick GuideTeoStanciu100% (2)
- Perfect StormДокумент21 страницаPerfect Stormsonatagp100% (1)
- HeatДокумент7 страницHeatkevinjorgeramosОценок пока нет
- 2.3 Design of Hydrometeorological Data NetworksДокумент13 страниц2.3 Design of Hydrometeorological Data NetworksravishnkОценок пока нет
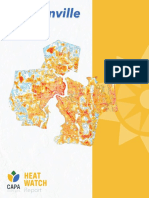
- Summary Report Heat Watch Jacksonville 080422Документ20 страницSummary Report Heat Watch Jacksonville 080422ActionNewsJaxОценок пока нет
- Crude Oil Viscosity Correlations - A Novel Approach For Upper Assam BasinДокумент6 страницCrude Oil Viscosity Correlations - A Novel Approach For Upper Assam BasinAbhishek BihaniОценок пока нет
- IEEE Xplore - Assimilating Remote Sensing-Based ET Into SWAP Model For Improved Estimation of Hydrological PredictionsДокумент1 страницаIEEE Xplore - Assimilating Remote Sensing-Based ET Into SWAP Model For Improved Estimation of Hydrological Predictionsbkamble1Оценок пока нет
- Science5 Q4 Week3 1Документ25 страницScience5 Q4 Week3 1cherinemichaellamОценок пока нет
- GR7 Hw3mansciДокумент4 страницыGR7 Hw3mansciRIANE PADIERNOSОценок пока нет
- TimeseriesprojectДокумент33 страницыTimeseriesprojectapi-497291597Оценок пока нет
- Forecasting PDFДокумент61 страницаForecasting PDFRina TugadeОценок пока нет
- Afi11 2f 16v3 Aetcsup1Документ5 страницAfi11 2f 16v3 Aetcsup1diablik7Оценок пока нет
- KrishnaBathula 1Документ6 страницKrishnaBathula 1Basit OnaopepoОценок пока нет
- NRL Spectra - Fall 2011Документ36 страницNRL Spectra - Fall 2011U.S. Naval Research LaboratoryОценок пока нет
- Word Formation ExercisesДокумент7 страницWord Formation ExercisesRamona Georgiana100% (2)
- A Mathematical Model For Equilibrium Solubility of Hydrogen Sulfide and Carbon Dioxide in Aqueous Alkanolamine SolutionsДокумент8 страницA Mathematical Model For Equilibrium Solubility of Hydrogen Sulfide and Carbon Dioxide in Aqueous Alkanolamine Solutionsiitgn007100% (1)
- R Rec P.618 10 200910 I!!pdf eДокумент26 страницR Rec P.618 10 200910 I!!pdf erard111Оценок пока нет
- Status of Drought Monitoring and Preparedness in The PhilippinesДокумент28 страницStatus of Drought Monitoring and Preparedness in The PhilippinesRyan Jay BihaganОценок пока нет