Вам также может понравиться
- International Journal of Database Management SystemsДокумент2 страницыInternational Journal of Database Management SystemsMaurice LeeОценок пока нет
- International Journal of Database Management SystemsДокумент2 страницыInternational Journal of Database Management SystemsMaurice LeeОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- 8th International Conference On Data Mining & Knowledge Management (DaKM 2023)Документ2 страницы8th International Conference On Data Mining & Knowledge Management (DaKM 2023)Maurice LeeОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- Call For Articles - International Journal of Computer Science & Information Technology (IJCSIT)Документ2 страницыCall For Articles - International Journal of Computer Science & Information Technology (IJCSIT)Anonymous Gl4IRRjzNОценок пока нет
- Scaling Distributed Database Joins by Decoupling Computation and CommunicationДокумент18 страницScaling Distributed Database Joins by Decoupling Computation and CommunicationMaurice LeeОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- A Review of The Use of R Pprogramming For Data Science Research in BotswanaДокумент16 страницA Review of The Use of R Pprogramming For Data Science Research in BotswanaMaurice LeeОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- International Journal of Database Management Systems (IJDMS)Документ2 страницыInternational Journal of Database Management Systems (IJDMS)ijaitjournalОценок пока нет
- Active Learning Entropy Sampling Based Clustering Optimization Method For Electricity DataДокумент12 страницActive Learning Entropy Sampling Based Clustering Optimization Method For Electricity DataMaurice LeeОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5784)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Noon and Tanween RulesДокумент56 страницNoon and Tanween RulesReadRead100% (2)
- Psychological Assessment Chapter 4 - of Tests and Testing PDFДокумент7 страницPsychological Assessment Chapter 4 - of Tests and Testing PDFSam CruzОценок пока нет
- RMXPRT Manual PDFДокумент481 страницаRMXPRT Manual PDFsch12332163% (16)
- Commonwealth scholarships to strengthen global health systemsДокумент4 страницыCommonwealth scholarships to strengthen global health systemsanonymous machineОценок пока нет
- Interpretative Translation Theory EvaluationДокумент13 страницInterpretative Translation Theory EvaluationAnastasia MangoОценок пока нет
- Specific Gravity by Pycnometer MethodДокумент4 страницыSpecific Gravity by Pycnometer Methodأحمد جاسم محمدОценок пока нет
- ALL INDIA NURSING TEST REVIEWДокумент102 страницыALL INDIA NURSING TEST REVIEWDr-Sanjay SinghaniaОценок пока нет
- Determinants of Cash HoldingsДокумент26 страницDeterminants of Cash Holdingspoushal100% (1)
- Advanced Management Accounting: ConceptsДокумент47 страницAdvanced Management Accounting: ConceptsGEDDIGI BHASKARREDDYОценок пока нет
- DeKalb Pay Raise Summary July 6 2022Документ8 страницDeKalb Pay Raise Summary July 6 2022Janet and JamesОценок пока нет
- Literary Analysis Essay - Student PacketДокумент11 страницLiterary Analysis Essay - Student Packetapi-2614523120% (1)
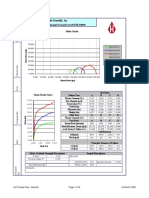
- Humboldt Scientific, Inc.: Normal Stress (Psi)Документ9 страницHumboldt Scientific, Inc.: Normal Stress (Psi)Dilson Loaiza CruzОценок пока нет
- PI PaperДокумент22 страницыPI PaperCarlota Nicolas VillaromanОценок пока нет
- Michigan History-Lesson 3Документ4 страницыMichigan History-Lesson 3api-270156002Оценок пока нет
- Planning Values of Housing Projects in Gaza StripДокумент38 страницPlanning Values of Housing Projects in Gaza Stripali alnufirОценок пока нет
- Analogs of Quantum Hall Effect Edge States in Photonic CrystalsДокумент23 страницыAnalogs of Quantum Hall Effect Edge States in Photonic CrystalsSangat BaikОценок пока нет
- WFISD Agenda Special SessionДокумент1 страницаWFISD Agenda Special SessionDenise NelsonОценок пока нет
- Types of Errors and Coding TechniquesДокумент11 страницTypes of Errors and Coding TechniquesTiffany KagsОценок пока нет
- 7 Ways To Shortlist The Right StocksДокумент10 страниц7 Ways To Shortlist The Right Stockskrana26Оценок пока нет
- Personal Narrative EssayДокумент3 страницыPersonal Narrative Essayapi-510316103Оценок пока нет
- 2018 CML Updates and Case Presentations: Washington University in ST Louis Medical SchoolДокумент113 страниц2018 CML Updates and Case Presentations: Washington University in ST Louis Medical SchoolIris GzlzОценок пока нет
- Module For Hyperbolic GeometryДокумент41 страницаModule For Hyperbolic GeometryShela RamosОценок пока нет
- Sap HCM loclalization-EGДокумент124 страницыSap HCM loclalization-EGrania abdelghanyОценок пока нет
- Quantum Mechanics and PeriodicityДокумент51 страницаQuantum Mechanics and Periodicitynxumalopat2Оценок пока нет
- Customer Satisfaction and Firm Performance: Insights From Over A Quarter Century of Empirical ResearchДокумент22 страницыCustomer Satisfaction and Firm Performance: Insights From Over A Quarter Century of Empirical ResearchMohamedAliBenAmorОценок пока нет
- (1964) AC 763 Help: House of Lords Chandler and OthersДокумент22 страницы(1964) AC 763 Help: House of Lords Chandler and OthersShehzad HaiderОценок пока нет
- Chromatography Viva Questions & Answers GuideДокумент4 страницыChromatography Viva Questions & Answers GuidedhruvОценок пока нет
- GSP Action PlanДокумент2 страницыGSP Action PlanTen Victa-Milano100% (3)
- Seán Ó HEochaidhДокумент3 страницыSeán Ó HEochaidhJoakamaster 16Оценок пока нет
- Akhila-Rasamrta-Murtih Prasrmara-Ruci-Ruddha-Taraka-PalihДокумент44 страницыAkhila-Rasamrta-Murtih Prasrmara-Ruci-Ruddha-Taraka-PalihSauri ChaitanyaОценок пока нет