Академический Документы
Профессиональный Документы
Культура Документы
Curso SQL Server SSMS
Загружено:
Rene DC0 оценок0% нашли этот документ полезным (0 голосов)
173 просмотров178 страницОригинальное название
Curso de SQL Server.docx
Авторское право
© © All Rights Reserved
Доступные форматы
DOCX, PDF, TXT или читайте онлайн в Scribd
Поделиться этим документом
Поделиться или встроить документ
Этот документ был вам полезен?
Это неприемлемый материал?
Пожаловаться на этот документАвторское право:
© All Rights Reserved
Доступные форматы
Скачайте в формате DOCX, PDF, TXT или читайте онлайн в Scribd
0 оценок0% нашли этот документ полезным (0 голосов)
173 просмотров178 страницCurso SQL Server SSMS
Загружено:
Rene DCАвторское право:
© All Rights Reserved
Доступные форматы
Скачайте в формате DOCX, PDF, TXT или читайте онлайн в Scribd
Вы находитесь на странице: 1из 178
1
Curso de SQL Server. ndice del curso
n d i c e d e t a l l a d o
Unidad 1. El entorno grfico
SSMS
1.1. Introduccin
1.2. Instalar SQL Server 2005
1.3. Entrada al SQL Server
Management Studio
Introduccin a las bases de datos
Ediciones de SQL Server 2005
1.4. Estructura interna de una base
de datos
1.5. Crear una base de datos en
SSMS
1.6. Adjuntar una base de datos
1.7. Conectar y Desconectar la base
de datos
1.8. Crear una nueva tabla
1.9. Tipos de datos
1.10. Valores nulos
1.11. Columna con contador
1.12. Clave primaria
1.13. Aadir o eliminar columnas
1.14. Modificar la definicin de una
tabla
1.15. Insertar datos en la tabla
1.16. Modificar datos
1.17. Eliminar filas
1.18. Relacionar tablas
1.19. Abrir una nueva consulta
1.20. Escribir y ejecutar cdigo
TRANSACT-SQL
1.21. La base de datos
predeterminada
1.22. El editor de texto
1.23. Configurar un esquema de
colores personalizado
1.24. Las Vistas
1.25. El panel de diagrama
1.26. El panel de criterios
1.27. El panel SQL
Unidad 2. Introduccin al SQL.
Transact-SQL
2.1. Conceptos bsicos de SQL
2.2. Introduccin al TRANSACT-
SQL
2.3. Caractersticas generales del
lenguaje Transact-SQL
2.4. Reglas de formato de los
identificadores
2.5. Tipos de datos
2.6. Las constantes
Unidad 5. Consultas de
resumen
5.1. Introduccin
5.2. Las funciones de agregado
5.3. La funcin COUNT
5.4. La funcin COUNT_BIG
5.5. La funcin MAX
5.6. La funcin MIN
5.7. La funcin SUM
5.8. La funcin AVG
5.9. La funcin VAR
5.10. La funcin VARP
5.11. La funcin STDEV
5.12. La funcin STDEVP
5.13. La funcin GROUPING
5.14. Agrupamiento de filas
(clusula GROUP BY).
5.15. Seleccin sobre grupos de
filas, la clusula HAVING
Unidad 6. Las subconsultas
6.1. Introduccin
6.2. Subconsultas de resultado
nico
6.3. Subconsultas de lista de valores
6.4. El operador IN con subconsulta
6.5. La comparacin modificada
(ANY, ALL)
6.6. Subconsultas con cualquier
nmero de columnas (EXISTS)
Unidad 7. Actualizacin de
datos
7.1. Introduccin
7.2. Insertar creando una nueva
tabla
7.3. Insertar en una tabla
existente INSERT INTO
7.4. Insertar una fila de valores
7.5. Insercin de varias filas
7.6. Insertar una fila de valores por
defecto
7.7. Modificar datos almacenados -
UPDATE
7.8. Eliminar filas - DELETE
7.9. Borrado masivo - TRUNCATE
Unidad 8. El DDL, Lenguaje de
2
Tipos de datos
Definir constantes segn el tipo de
dato
2.7. Las expresiones
2.8. Funciones
2.9. Las variables
2.10. Otros elementos del lenguaje
Unidad 3. Consultas simples
3.1. Introduccin
3.2. Origen de datos FROM
3.3. La lista de seleccin
3.4. Columnas del origen de datos
3.5. Alias de columna
3.6. Funciones
Funciones en Transact-SQL
3.7. Columnas calculadas
3.8. Utilizacin del asterisco *
3.9. Las palabras clave $IDENTITY
y $ROWGUID
3.10. Ordenacin de las filas del
resultado ORDER BY
3.11. Eliminar filas duplicadas
DISTINCT/ALL
3.12. La clusula TOP
3.13. Seleccin de filas WHERE
3.14. Predicados
Los predicados CONTAINS y
FREETEXT
3.15. Condiciones de bsqueda
compuestas
Unidad 4. Consultas multitabla
4.1. Introduccin
4.2. La unin de tablas UNION
4.3. La diferencia EXCEPT
4.4. La interseccin INTERSECT
4.5. La composicin de tablas
4.6. El producto cartesiano CROSS
JOIN
4.7. La composicin interna INNER
JOIN
4.8. La Composicin externa LEFT,
RIGHT y FULL OUTER JOIN
4.9. Combinar varias operaciones
Definicin de Datos
8.1. Introduccin
8.2. Definir una base de datos
CREATE DATABASE
Intercalaciones COLLATE
8.3. Eliminar una base de datos
DROP DATABASE
8.4. Modificar las propiedades de
una BD ALTER DATABASE
8.5. Crear una tabla CREATE
TABLE
Tipos de datos: precisin, escala,
longitud y prioridad
8.6. Eliminar una tabla DROP
TABLE
8.7. Modificar la definicin de una
tabla ALTER TABLE
8.8. Crear una vista CREATE VIEW
8.9. Eliminar una vista DROP VIEW
8.10. Definicin de ndice
8.11. Tipos de ndices
8.12. Ventajas e inconvenientes de
los ndices
8.13. Definir un ndice CREATE
INDEX
8.14. Eliminar un ndice DROP
INDEX
Unidad 9. Programacin en
TRANSACT SQL
9.1. Introduccin
9.2. Procedimientos almacenados
STORE PROCEDURE
9.3. Eliminar procedimientos
almacenados
9.4. Crear y ejecutar un
procedimiento
9.5. Instrucciones de control de flujo
9.6. IF ELSE
9.7. WHILE BREAK- CONTINUE
9.8. WAITFOR
9.9. GOTO
9.10. TRY... CATCH
9.11. Desencadenadores o
TRIGGERS
9.12. CREATE TRIGGER
9.13. DISABLE TRIGGER
9.14. ENABLE TRIGGER
9.15. DROP TRIGGER
3
Unidad 1. El entorno grfico SSMS (I)
1.1. Introduccin
SQL Server 2005 es un sistema gestor de bases de datos relacionales de Microsoft
Corporation orientado a sistemas medianos y grandes aunque tambin puede rodar en
ordenadores personales. SQL Server Management Studio (SSMS) es la herramienta de
SQL Server que permite definir y gestionar todas las bases de datos almacenadas en el
servidor SQL Server 2005.
En este tema veremos cmo utilizar el SQL Server Management Studio para manejar
las bases de datos del servidor y organizaremos el texto en los siguientes puntos:
Instalar SQL Server 2005.
Entrada al SQL Server Management Studio
Las bases de datos: Estructura interna, crear, adjuntar, conectar y desconectar.
Las tablas: crear tablas, definirlas, modificar su contenido, etc.
Relacionar tablas
Las Consultas
Las Vistas
Si no sabes lo que es una base de datos relacional o no tienes conocimientos previos
acerca de las bases de datos, puedes leer una introduccin a las bases de datos en el
siguiente bsico
1.2. Instalar SQL Server 2005
Existen diferentes versiones (ediciones) del producto, por lo que es un producto muy
verstil, que puede cumplir con las exigencias de cualquier empresa, puede ser utilizado
para gestionar bases de datos en un PC en modo local a gestionar todo el sistema de
informacin de grandes empresas pasando por sistemas que requieran menos potencia y
por sistemas mviles.
Actualmente se utiliza ms en entornos Cliente/servidor con equipos medianos y
grandes.
Para realizar este curso te recomendamos instalar la versin gratuita: Express. Puedes
descargarla desde la pgina web de Microsoft, desde el enlace para iniciar descarga. Si
quieres ver las diferentes ediciones y sus caractersticas principales visita el siguiente
avanzado
Si la instalacin se realiza a partir del archivo descargado de Internet, la descarga se
empaqueta como un nico ejecutable mediante una tecnologa de instalacin de Microsoft
llamada SFXCab. Al hacer doble clic en el .exe se inicia automticamente el proceso de
instalacin.
Tan slo deberemos seguir el asistente. Los puntos ms importantes a tener en cuenta
son:
Habilitar el SQL Server Management Studio en la instalacin (si no lo est por
defecto) cuando nos pregunte qu componentes deseamos instalar.
4
Indicar que se trata de una Instancia predeterminada.
Lo ideal es que en este punto instales el programa, para ir probando lo que vayas
aprendiendo de aqu en adelante. Puedes realizar el siguiente Ejercicio Instalacin de
SQL Server 2005. El videotutorial prctico de instalacin tambin te ayudar.
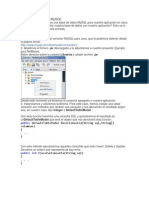
1.3. Entrada al SQL Server Management Studio
Aunque trabajemos en modo local, la entrada a la herramienta es la misma. Para
empezar entramos a travs del acceso directo o a travs de Inicio, Programas,
Microsoft SQL Server 2005, SQL Server Management Studio.
Lo primero que deberemos hacer es establecer la conexin con el servidor:
Seleccionamos el nombre del servidor y pulsamos el botn Conectar. Se abrir la
ventana inicial del SQL Server Management Studio (en adelante SSMS):
5
En la parte izquierda tenemos abierto el panel Explorador de Objetos en el que
aparece debajo del nombre del servidor con el que estamos conectados una serie de
carpetas y objetos que forman parte del servidor.
En el panel de la derecha se muestra la zona de trabajo, que vara segn lo que
tengamos seleccionado en el Explorador de objetos, en este caso vemos el contenido
de la carpeta que representa el servidor ord01.
En la parte superior tenemos el men de opciones y la barra de herramientas Estndar.
Con las siguientes opciones:
1. Nueva consulta
6. Consulta de SQL Server
Mobile
11. Resumen
2. Consulta de motor de Base
de datos
7. Abrir archivo
12. Explorador de
Objetos
3. Consulta MDX de Analysis
Services
8. Guardar
13. Explorador de
Plantillas
4. Consulta DMX de Analysis
Services
9. Guardar todo
14. Ventana de
Propiedades
5. Consulta MXLA de Analysis
Services
10. Servidores registrados
En caso de que utilices la versin Express, es posible que no dispongas de algunos de
stos botones.
Unidad 1. El entorno grfico SSMS (II)
1.4. Estructura interna de una base de datos
Antes de empezar tenemos que tener claro cmo se organiza la informacin en una
base de datos SQL Server 2005.
Las bases de datos de SQL Server 2005 utilizan tres tipos de archivos:
Archivos de datos principales
En una base de datos SQLServer los datos se pueden repartir en varios archivos
para mejorar el rendimiento de la base de datos.
El archivo de datos principal es el punto de partida de la base de datos y apunta a
los otros archivos de datos de la base de datos. Cada base de datos tiene
obligatoriamente un archivo de datos principal. La extensin recomendada para los
nombres de archivos de datos principales es .mdf.
6
Archivos de datos secundarios
Los archivos de datos secundarios son todos los archivos de datos menos el archivo
de datos principal. Puede que algunas bases de datos no tengan archivos de datos
secundarios, mientras que otras pueden tener varios archivos de datos secundarios.
La extensin de nombre de archivo recomendada para los archivos de datos
secundarios es .ndf.
Adems los archivos de datos se pueden agrupar en grupos de archivos. Para cada
base de datos pueden especificarse hasta 32.767 archivos y 32.767 grupos de
archivos.
Archivos de registro
Los archivos de registro (archivos de log) almacenan toda la informacin de registro
que se utiliza para recuperar la base de datos, el tambin denominado registro de
transacciones. Como mnimo, tiene que haber un archivo de registro por cada base
de datos, aunque puede haber varios. La extensin recomendada para los nombres
de archivos de registro es .ldf.
SQL Server 2005 no exige las extensiones de nombre de archivo .mdf, .ndf y .ldf, pero
estas extensiones ayudan a identificar las distintas clases de archivos y su uso.
Cada base de datos tiene al menos 2 archivos (un archivo de datos principal y un
archivo de registro) y opcionalmente un grupo de archivos.
Los archivos de datos y de registro de SQL Server se pueden colocar en sistemas de
archivos FAT o NTFS. Se recomienda utilizar NTFS por los aspectos de seguridad que
ofrece. No se pueden colocar grupos de archivos de datos de lectura y escritura, y
archivos de registro, en un sistema de archivos NTFS comprimido. Slo las bases de
datos de slo lectura y los grupos de archivos secundarios de slo lectura se pueden
colocar en un sistema de archivos NTFS comprimido.
1.5. Crear una base de datos en SSMS
En el Explorador de objetos, si desplegamos la carpeta Bases de datos nos
aparecen Bases de datos del sistema y las bases de datos de usuario despus de la
carpeta Instantneas...
Despus de la instalacin, en la carpeta Bases de datos del sistema se habr creado
una especial denominada master se utiliza como base de datos de usuario por defecto.
Las dems bases de datos forman tambin parte del diccionario de datos y las utiliza el
sistema para llevar a cabo su gestin.
7
Las bases de datos de los usuarios se deben crear preferentemente fuera de la carpeta
Bases de datos del sistema.
Unidad 1. El entorno grfico SSMS (III)
Para crear una nueva base de datos de usuario nos posicionamos sobre la carpeta
Bases de datos y con el botn derecho del ratn desplegamos el men contextual del
que elegimos la opcin Nueva base de datos
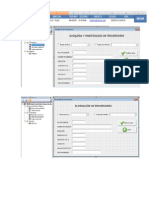
Se abre a continuacin el cuadro de dilogo donde definiremos la base de datos que
queremos crear:
8
Lo mnimo a introducir ser el campo Nombre de la base de datos, ste es el nombre
de la base de datos lgica, la base de datos a la que nos referiremos dentro del SSMS, a
nivel conceptual (en la imagen Mibase).
Esta base de datos est asociada a dos archivos fsicos, en la parte inferior aparecen
esos archivos. Para facilitarnos la tarea, al teclear el nombre de la bd lgica, se rellenan
automticamente los nombres de los archivos fsicos, el de datos con el mismo nombre y
el del archivo de registro con el mismo nombre seguido de _log. Estos nombres son los
nombres que se asumen por defecto pero los podemos cambiar, posicionando el cursor
en el nombre y cambindolo.
Para cada archivo fsico podemos definir una serie de parmetros como el tipo de
archivo (si es de datos o de transacciones Registro) y su ocupacin inicial (Tamao
inicial).
Si no indicamos ninguna ubicacin podemos ver que los guarda en la carpeta del SQL
Server/MSSQL.n/MSSQL/DATA.
n representa un nmero que puede variar de una instalacin a otra.
9
Estos son los archivos mnimos en los que se almacenar la base de datos, pero como
ya vimos anteriormente se puede almacenar en ms archivos, los tenemos que definir
todos en esta ventana a continuacin de los dos obligatorios.
Para aadir ms archivos fsicos disponemos del botn Agregar.
Al pulsar el botn Agregar se crea una nueva fila en la tabla de archivos fsicos donde
deberemos escribir el nombre del archivo, su tipo (desplegando la lista podemos elegir
entre de datos o de registro) y dems parmetros.
Al agregar un nuevo archivo se activa el botn Quitar, siempre que estemos
posicionados encima de un archivo secundario para poder as eliminarlo si lo queremos.
10
No podemos eliminar ni el de datos primario, ni el de registro inicial.
Unidad 1. El entorno grfico SSMS (IV)
Si nos fijamos en la zona de la izquierda, vemos que nos encontramos en la pestaa
General, podemos cambiar otros parmetros de la base de datos pulsando en Grupos de
archivos o en Opciones:
Al final pulsamos en Aceptar y se crear la base de datos.
11
Aparecer dentro de la carpeta Bases de datos. Si no se ve pulsa en el icono
Actualizar .
Desde el Explorador de Windows podemos ver que en la carpeta indicada se han
creado los archivos fsicos con los nombres que le hemos indicado.
Unidad 1. El entorno grfico SSMS (V)
1.6. Adjuntar una base de datos
En ocasiones no necesitaremos crear la base de datos desde cero, porque sta ya
estar creada. ste es el caso de los ejercicios del curso. Para realizarlos, debers
adjuntar una base de datos ya existente a tu servidor. Para ello, lo que tenemos que
hacer es pegar los archivos en la ubicacin que queramos, y luego indicar al SQL Server
que vamos a utilizar esta base de datos, de la siguiente manera:
En el Explorador de objetos, sobre la carpeta Bases de datos desplegar el men
contextual y elegir Adjuntar...
En la siguiente ventana elegimos la base de datos:
12
Pulsando en Agregar indicamos el archivo de datos primario en su ubicacin y
automticamente se adjuntar la base de datos lgica asociada a este archivo.
Finalmente pulsamos en Aceptar y aparece la base de datos en nuestro servidor.
13
La opcin Adjuntar slo se utiliza la primera vez, cuando todava no tenemos la base
de datos en el disco.
Realiza el siguiente Ejercicio Adjuntar base de datos. En l adjuntars las bases de
datos que vas a utilizar en los ejercicios que se plantearn ms adelante.
1.7. Conectar y Desconectar la base de datos
Una vez hemos creado la base de datos o la hemos adjuntado a nuestro servidor, nos
daremos cuenta de que no podremos manipular los archivos de la base desde fuera del
gestor SSMS, por ejemplo, desde el Explorador de Windows. Es decir, no podremos
copiar, cortar, mover o eliminar los archivos fuente mdf, ndf y ldf. Si lo intentamos se
mostrar un aviso de que la base de datos est en uso.
Esto es as porque SQL Server sigue en marcha, a pesar de que se cierre el gestor.
Ten en cuenta que el servidor de base de datos normalmente se crea para que sirva
informacin a diferentes programas, por eso sera absurdo que dejara de funcionar
cuando cerramos el programa gestor, que slo se utiliza para realizar modificaciones
sobre la base.
Para poder realizar acciones sobre la base de datos, sta debe estar desconectada.
Para ello, desde el SSMS, desplegamos el men contextual de la base de datos que nos
interese manipular y seleccionaremos la opcin Poner fuera de conexin:
Aparecer un smbolo a la izquierda de la base de datos indicndonos que la base de
datos est desconectada, a partir de este momento Windows nos dejar manipular los
archivos.
Para volver a conectar la base de datos y seguir trabajando con ella, accederemos al
mismo men contextual pero elegiremos la opcin Poner en conexin:
14
El caso ms inmediato en el que puedes necesitar conectar y desconectar la base de
datos es copiar a un pendrive los archivos de las bases que utilizars en los ejercicios
para poder trabajar en diferentes ordenadores con ellos. Para aprender cmo hacerlo,
visita el siguiente Ejercicio Trasladar una base de datos a otro equipo.
En caso de que tu versin de SQL Server no tenga las opciones Poner en conexin y
Poner fuera de conexin, debers utilizar la opcin Separar... y luego volver a
adjuntarla.
Unidad 1. El entorno grfico SSMS (VI)
1.8. Crear una nueva tabla
Para crear una nueva tabla primero nos tenemos que posicionar en la base de datos
donde queremos que se almacene la tabla, desplegar el men contextual y seleccionar la
opcin Nueva tabla.
En la ventana que se abre debemos definir las columnas de la tabla:
15
A cada columna se le asigna un nombre, un tipo de datos, y opcionalmente una serie de
propiedades, en este tema veremos las bsicas y las dems las veremos con ms detalle
cuando veamos la instruccin SQL CREATE TABLE.
De momento no tenemos definida ninguna columna, al teclear un nombre se crea una
primera entrada en esta tabla con la definicin de la primera columna. En la columna Tipo
de datos elegimos qu tipo de valores se podrn almacenar en la columna.
1.9. Tipos de datos
Podemos elegir entre todos los tipos que aparecen arriba.
Algunos tipos no necesitan ms, como por ejemplo el tipo entero (int), y otros se
pueden completar con una longitud, como los tipos alfanumricos:
En este ejemplo hemos definido una columna (Codigo) de tipo Entero corto (Smallint),
y una columna (Nombre) que almacenar hasta 20 caracteres alfanumricos (nchar(20)),
en este caso la longitud la indicamos en la pestaa Propiedades de columna en la
propiedad Longitud.
16
Las propiedades de la columna pueden variar dependiendo del tipo de datos de la
columna seleccionada, por ejemplo los campos enteros no tienen la propiedad longitud,
ya que el propio tipo define la longitud del campo, en cambio los campos de tipo
numeric o decimal no tiene la propiedad longitud pero s las propiedades escala y
precisin, los valores que permiten definir el tamao del campo.
Unidad 1. El entorno grfico SSMS (VII)
1.10. Valores nulos
Tambin podemos indicar si la columna permitir valores nulos o no, o bien cambiando
la propiedad Permitir valores nulos que aparece debajo de la propiedad Longitud, o
bien simplemente marcando o desmarcando la casilla de la columna Permitir valores
nulos que se encuentra al lado de la columna Tipo de datos. Si la casilla est marcada,
el usuario podr no rellenar el campo cuando inserte una fila de datos en la tabla.
1.11. Columna con contador
En la mayora de los sistemas gestores de bases de datos tenemos un tipo de datos de
tipo contador, autonumrico, autoincremental, etc. Este tipo hace que el propio sistema es
el encargado de rellenar el campo con un valor que va incrementando conforme se crean
ms filas de datos en la tabla.
Las columnas de este tipo se utilizan normalmente para numerar las filas de la tabla,
como no habrn dos filas con el mismo valor (el sistema se encarga de incrementar el
valor cada vez que se crea una nueva fila), estos campos se suelen utilizar como claves
primarias.
En SQL Server 2005 no existe el tipo de datos Contador pero se consigue el mismo
funcionamiento asignando a la columna un tipo de datos numrico y definiendo la columna
como columna de identidad.
En las propiedades de la columna marcamos S en la propiedad (Identidad) y a
continuacin podemos indicar en qu valor queremos que empiece el contador
17
(Inicializacin de identidad) y en cunto incrementar cada vez que se cree un nuevo
registro (Incremento de identidad).
Aunque este tipo de columnas se utiliza frecuentemente como clave primaria, SQL
Server no le asigna automticamente esta funcin, la tenemos que definir nosotros
mismos, pero s fuerza a que sea una columna sin valores nulos. No se puede definir ms
de una columna de identidad por tabla.
1.12. Clave primaria
Para definir una columna como clave primaria, posicionamos el puntero del ratn sobre
la columna, desplegamos el men contextual y seleccionamos la opcin Establecer Clave
principal:
Aparecer una llave a la izquierda del nombre, smbolo de las claves principales:
Para definir una clave primaria compuesta por varias columnas, seleccionamos las
columnas manteniendo pulsada la tecla Ctrl y luego seleccionamos la opcin.
Para quitar una clave principal, hacemos lo mismo pero en esta ocasin seleccionamos
la opcin Quitar clave principal.
Tambin podemos utilizar el icono de la barra de herramientas.
Unidad 1. El entorno grfico SSMS (VIII)
1.13. Aadir o eliminar columnas
Una vez definidas algunas columnas, si queremos aadir una nueva columna entre dos,
nos posicionamos en la segunda y seleccionamos la opcin Insertar columna del men
contextual.
18
La nueva columna se colocar delante:
Del mismo modo si queremos eliminar la definicin de una columna, nos posicionamos
en la columna a eliminar y seleccionamos la opcin Eliminar columna:
O simplemente hacemos clic en la zona a la izquierda del nombre y pulsamos la tecla
Supr.
Finalmente guardamos la tabla, nos pedir el nombre de la tabla:
La nueva tabla aparecer en la lista de tablas de la base de datos:
1.14. Modificar la definicin de una tabla
19
Para entrar a la ventana de definicin de la tabla utilizamos la opcin Modificar de su
men contextual (Tambin es posible que se llame Diseo):
Se abrir la ventana que ya conocemos para definir las columnas de la tabla.
Unidad 1. El entorno grfico SSMS (IX)
1.15. Insertar datos en la tabla
Ahora que tenemos la tabla creada podemos rellenarla con datos. Para eso debemos
abrir la tabla:
Se abrir una ventana parecida a esta:
La primera columna sirve para indicarnos el estado de una fila, por ejemplo el * nos
indica que es una nueva fila, esta fila realmente no est en la tabla, nos sirve de
contenedor para los nuevos datos que queremos insertar.
Para insertar una nueva fila de datos slo tenemos que rellenar los campos que
aparecen en esa fila (la del *), al cambiar de fila los datos se guardarn automticamente
en la tabla a no ser que alguno infrinja alguna regla de integridad, en ese caso SQL Server
nos devuelve un mensaje de error para que corrijamos el dato errneo, si no lo podemos
corregir entonces slo podemos deshacer los cambios.
1.16. Modificar datos
Para modificar un valor que ya est en una fila de la tabla slo tenemos que
posicionarnos en el campo y rectificar el valor. En cuanto modificamos un valor, la fila
aparece con un lpiz escribiendo (ver imagen), este lpiz nos indica que la fila se ha
modificado y tiene nuevos datos por guardar. Al salir de la fila sta se guardar
automticamente a no ser que el nuevo valor infrinja alguna regla de integridad. Si
queremos salir de la fila sin guardar los cambios, tenemos que cancelar la actualizacin
pulsando la tecla ESC.
20
1.17. Eliminar filas
Para eliminar una fila completa, la seleccionamos y pulsamos la tecla Supr o bien
desplegamos su men contextual y seleccionamos la opcin Eliminar.
En cualquiera de los dos casos nos aparece un mensaje de confirmacin.
1.18. Relacionar tablas
Como ya hemos visto, en una base de datos relacional, las relaciones entre las tablas
se implementan mediante la definicin de claves ajenas, que son campos que contienen
valores que sealan a un registro en otra tabla, en esta relacin as creada, la tabla
referenciada se considera principal y la que contiene la clave ajena es la subordinada.
Desde el entorno grfico del SSMS podemos definir claves ajenas entrando en el
diseo de la tabla y desplegando el men contextual del campo que va a ser clave ajena:
Seleccionamos la opcin Relaciones y se abre la ventana:
21
Al pulsar el botn que se encuentra en la fila Especificacin de tablas y columnas se
abre el dilogo donde definiremos la relacin:
Unidad 1. El entorno grfico SSMS (X)
En la parte derecha tenemos la tabla en la que estamos y el campo que va a actuar
como clave ajena, slo nos queda elegir en el desplegable de la izquierda la tabla a la que
hace referencia la clave y al seleccionar una tabla, a la izquierda del campo clave ajena
podremos elegir el campo de la otra tabla por el que se relacionarn las tablas. En nuestro
caso ser:
De esta forma hemos definido una relacin entre las tablas Facturas y Clientes. Para
ver las relaciones existentes entre las diferentes tablas tenemos los diagramas.
22
Primero debemos definir el diagrama, para ello seleccionamos la opcin
correspondiente:
Si no tenemos todava ningn diagrama creado, nos aparece un mensaje:
Elegimos S y se crea digamos el soporte donde se pintar el diagrama.
A continuacin nos aparece el nuevo diagrama ahora si elegimos crear un nuevo
diagrama nos preguntar las tablas a incluir en el diagrama:
Seleccionamos cada una y pulsamos Agregar, cuando hayamos agregado al diagrama
todas las que queremos pulsamos en Cerrar y aparecern en el diagrama las tablas con
las relaciones que tengan definidas en ese momento:
23
La llave indica la tabla principal (padre) y el smbolo infinito seala la tabla que contiene
la clave ajena.
En el examinador de objetos en la carpeta Diagramas de base de datos aparecen
todos los diagramas definidos hasta el momento:
Hemos aprendido hasta ahora lo bsico para poder crear una base de datos y rellenarla
con tablas relacionadas entre s y con datos, ahora veamos cmo recuperar esos datos.
Unidad 1. El entorno grfico SSMS (XI)
1.19. Abrir una nueva consulta
Vamos a ver ahora cmo crear consultas SQL y ejecutarlas desde el entorno del SSMS.
Para ello debemos abrir la zona de trabajo de tipo Query, abriendo una nueva consulta,
seleccionando previamente el servidor y pulsando el botn de la barra
de botones o si queremos realizar la consulta sobre un servidor con el cual todava no
hemos establecido conexin, seleccionando de la barra de mens la opcin Nuevo >
Consulta de motor de base de datos:
24
.
En este ltimo caso nos aparecer el cuadro de dilogo para establecer la conexin (el
mismo que vimos al principio del tema).
A continuacin se abrir una nueva pestaa donde podremos teclear las sentencias
SQL:
Adems aparece una nueva barra de botones que nos permitir ejecutar los comandos
ms tiles del modo query.
1.20. Escribir y ejecutar cdigo TRANSACT-SQL
Slo tenemos que teclear la sentencia a ejecutar, por ejemplo empezaremos por crear
la base de datos.
Utilizaremos la sentencia CREATE DATABASE mnima:
CREATE DATABASE ventas;
Al pulsar el botn Ejecutar se ejecuta la sentencia y aparece en la parte inferior el
resultado de la ejecucin, en la pestaa Mensajes:
25
Si ahora desplegamos la carpeta Bases de Datos del Explorador de Objetos,
observaremos la base de datos que hemos creado:
Si la ejecucin de la sentencia produce un error, el sistema nos devolver el mensaje
de error escrito en rojo en la pestaa Mensajes.
Podemos incluir en una misma consulta varias sentencias SQL, cuando pulsamos
Ejecutar se ejecutarn todas una detrs de otra. Si tenemos varias consultas y slo
queremos ejecutar una, la seleccionaremos antes de ejecutarla.
Unidad 1. El entorno grfico SSMS (XII)
1.21. La base de datos predeterminada
Cuando ejecutamos consultas desde el editor, nos tenemos que fijar sobre qu base de
datos se va a actuar.
26
Fijndonos en la pestaa de la consulta, en el nombre aparece el nombre del servidor
seguido de un punto y el nombre de la base de datos sobre la que se va a actuar y luego
un guin y el nombre de la consulta.
En la imagen anterior tenemos ord01.master SQLQuery1.sql, lo que nos indica que
la consulta se llama SQLQuery1.sql, y que se va a ejecutar sobre la base de datos
master que se encuentra en el servidor ord01.
Cuando creamos una nueva consulta, sta actuar sobre la base de datos activa en
ese momento. Por defecto la base de datos activa es la predeterminada (master). Si
queremos que la base de datos activa sea por ejemplo la base de datos ventas, hacemos
clic sobre su nombre en el Explorador de objetos, y sta pasar a ser la base de datos
activa. Si ahora creamos una nueva consulta, sta actuar sobre la base de datos ventas.
Si queremos crear una consulta que siempre acte sobre una determinada base de
datos y no nos queremos preocupar de qu base de datos tenemos activa podemos
aadir al principio de la consulta la instruccin USE nombreBaseDatos; esto har que
todas las instrucciones que aparezcan despus, se ejecuten sobre la base de datos
indicada.
Por ejemplo:
USE ventas;
SELECT * FROM pedidos;
Obtiene todos los datos de la tabla pedidos que se encuentra en la base de datos
ventas.
Si no utilizamos USE y almacenamos la consulta, al abrirla otra vez, coger como base de
datos la predeterminada (no la activa) y se volver a ejecutar sobre la base de datos
master.
Normalmente utilizaremos como base de datos la nuestra y no la base de datos master,
por lo que nos ser til cambiar el nombre de la base de datos por defecto, esto lo
podemos hacer cambiando la base de datos por defecto en el id de sesin.
Para ello, cuando vamos a conectar con el servidor:
Pulsamos en el botn Opciones >>
27
En la pestaa Propiedades de conexin, en el cuadro Conectar con base de datos:
Seleccionamos <Examinar servidor > para elegir la base de datos.
La elegimos y aceptamos. A partir de ese momento la base de datos elegida ser la
que SQL Server coja por defecto en todas las sesiones de ese usuario.
Unidad 1. El entorno grfico SSMS (XIII)
1.22. El editor de texto
28
Para facilitarnos la redaccin y correccin de las sentencias, el editor de SQL presenta
las palabras de distintos colores segn su categora y podemos utilizar el panel
Explorador de Objetos para arrastrar desde l los objetos sobre la zona de trabajo y as
asegurarnos de que los nombres de los objetos (por ejemplo nombre de tabla, de
columna, etc.) sean los correctos.
Como hemos dicho el texto que se escribe en este editor de cdigo se colorea por
categora. Los colores son los mismos que se utilizan en todo el entorno SQL Server. En
esta tabla aparecen los colores ms comunes.
Color Categora
Rojo Cadena de caracteres
Verde oscuro Comentario
Negro sobre fondo plateado Comando SQLCMD
Fucsia Funcin del sistema
Verde Tabla del sistema
Azul Palabra clave
Verde azulado Nmeros de lnea o parmetro de plantilla
Rojo oscuro Procedimiento almacenado de SQL Server
Gris oscuro Operadores
1.23. Configurar un esquema de colores personalizado
En el men Herramientas > Opciones, desplegando la opcin Entorno, Fuentes y
colores, se puede ver la lista completa de colores y sus categoras, as como configurar
un esquema de colores personalizado:
29
En la lista Mostrar valores para, seleccionamos el entorno que se ver afectado.
El botn Usar predeterminados nos permite volver a la configuracin predeterminada.
Ahora slo nos queda aprender a redactar sentencias SQL, cosa que se ver en otro
momento, mientras tanto podemos utilizar el Generador de Consulta que incluye SSMS y
que veremos a continuacin en el apartado sobre vistas.
1.24. Las Vistas
Las consultas que hemos visto hasta ahora son trozos de cdigo SQL que podemos
guardar en un archivo de texto y abrir y ejecutar cuando queramos, pero si queremos que
nuestra consulta de recuperacin de datos se guarde en la propia base de datos y se
comporte como una tabla (algo parecido a una consulta almacenada de Access), la
tenemos que definir como una vista. Esta vista tiene la ventaja entre otras de poder ser
utilizada como si fuese una tabla en otras consultas. Realmente al ejecutarla obtenemos
una tabla lgica almacenada en memoria y lo que se guarda en la base de datos es su
definicin, la instruccin SQL que permite recuperar los datos.
30
Para definir una vista en el Explorador de Objetos desplegamos la base de datos
donde la guardaremos y elegimos la opcin Nueva vista del men contextual de la
carpeta Vistas, se pondr en funcionamiento el generador de consultas pidindonos las
tablas en las que se basar la vista. Pulsamos sobre la tabla a aadir al diseo de la vista
y pulsamos el botn Agregar, podemos aadir as cuntas tablas queramos.
Despus de Cerrar, vemos a la derecha del Explorador de Objetos la pestaa con la
definicin de la vista que puede incluir varios paneles:
31
La aparicin de estos paneles es configurable, en la barra de herramientas Diseador
de vistas los iconos remarcados en azul son los correspondientes a cada panel:
32
Unidad 1. El entorno grfico SSMS (XIV)
Nosotros, a lo largo del curso, crearemos las vistas desde el panel SQL que veremos
ms adelante.
1.25. El panel de diagrama
Es el primero que aparece, incluye una representacin grfica de las tablas con sus
campos y de la forma en que se juntan en la vista. En este caso, como las tablas tienen
relaciones definidas (claves ajenas), esta relacin ha aparecido automticamente al aadir
la segunda tabla. Pero se puede cambiar el tipo de relacin eligiendo la opcin
correspondiente en el men contextual que aparece con el clic derecho sobre la relacin:
Desde el panel diagrama podemos aadir cmodamente campos de las tablas a la
consulta marcando la casilla correspondiente. En la imagen anterior la nica casilla
seleccionada es la del * en la tabla Libros por lo que se visualizarn todas las columnas de
la tabla Libros y ninguna de la tabla Prstamos.
Conforme vamos marcando casillas de las tablas del panel diagrama, los cambios se
ven reflejados en los dems paneles excepto en el panel de resultados que se actualiza
ejecutando la consulta.
1.26. El panel de criterios
Es una rejilla en la que podemos definir las columnas del resultado de la consulta (las
columnas de la vista).
En cada fila de la rejilla se define una columna del resultado o una columna que se
utiliza para obtener el resultado.
En Columna tenemos el nombre de la columna de la se obtienen los datos o la
expresin cuando se trata de una columna calculada.
En Alias escribimos el nombre que tendr la columna en la vista, tambin
corresponde con el encabezado de la columna en la rejilla de resultado. Si se deja el
campo en blanco, por defecto se asume el mismo nombre que hay en Columna.
En Tabla tenemos el nombre de la tabla del origen de la consulta a la que pertenece
la Columna, por ejemplo la primera columna del resultado se saca de la columna
33
Codigo de la tabla LIBROS y se llamar CodLibro. La cuarta columna de la vista
coger sus datos de la columna Usuario de la tabla Prestamos y se llamar Usuario
(Alias se ha dejado en blanco por lo que asume el nombre que hay en Columna.
En la columna Resultados indicamos si queremos que la columna se visualice o no,
las columnas con la casilla marcada se visualizan.
Las columnas Criterio de ordenacin y Tipo de orden permiten ordenar las filas del
resultado segn una o ms columnas. Se ordena por las columnas que tienen algo
en Tipo de orden y cuando se ordena por varias columnas Criterio de ordenacin
indica que primero se ordena por la columna que lleva el n 1 y despus por la
columna que lleva el n 2 y as sucesivamente. En el ejemplo las filas del resultado
se ordenarn primero por cdigo de libro y despus por cdigo de prstamo, todas
las filas dentro del mismo libro se ordenarn por cdigo de prstamo.
Si queremos aadir unos criterios de seleccin tenemos las columnas Filtro y O
En cada celda indicamos una condicin que debe cumplir la columna correspondiente y
se puede combinar varias condiciones mediante O (OR) e Y (AND) segn coloquemos las
condiciones en la misma columna o en columnas diferentes. En el ejemplo anterior
tenemos la condicin compuesta: ((usuario=1) AND (Dias>5)) OR (Usuario=2).
Podemos variar el orden de aparicin de las columnas arrastrando la fila
correspondiente de la rejilla hasta el lugar deseado.
Tambin podemos Elimnar filas de la rejilla para eliminar columnas del resultado, lo
conseguimos seleccionando la fila haciendo clic sobre su extremo izquierda y cuando
aparece toda la fila remarcada pulsamos Supr o desde el men contextual de la fila.
Podemos definir consultas ms complejas como por ejemplo consultas de resumen,
pulsando sobre el botn Agrupar por de la barra de herramientas, se aade a la rejilla
una nueva columna Agrupar por con las siguientes opciones:
34
Unidad 1. El entorno grfico SSMS (XV)
1.27. El panel SQL
En l vemos la instruccin SQL generada, tambin podemos redactar directamente la
sentencia SQL en el panel y ver los cambios equivalentes en los distintos paneles. Para
ver estos cambios debemos de ejecutar o Comprobar la sintaxis para que se actualicen
los dems paneles.
Por defecto el generador aade a la consulta una clusula TOP (100) PERCENT que
indica que se visualizarn el 100% de las filas. Esta clusula no la hemos definido
nosotros sino que la aade automticamente el generador.
Una vez tenemos la vista definida la guardamos y podremos hacer con ella casi todo lo
que podemos hacer con una tabla. De hecho si nos fijamos en el Explorador de objetos,
en la carpeta Vistas:
Vemos que la estructura es muy similar a la estrutura de una tabla. Y que podemos
modificar su definicin y ejecutarla, igual que con las tablas:
Modificar para modificar la definicin de la vista
Abrir vista para ejecutarla y ver los datos como si fuese una tabla real.
35
Unidad 2. Introduccin al SQL. Transact-SQL (I)
2.1. Conceptos bsicos de SQL
SQL (Structured Query Language), Lenguaje Estructurado de Consulta es el lenguaje
utilizado para definir, controlar y acceder a los datos almacenados en una base de datos
relacional.
Como ejemplos de sistemas gestores de bases de datos que utilizan SQL podemos
citar DB2, SQL Server, Oracle, MySql, Sybase, PostgreSQL o Access.
El SQL es un lenguaje universal que se emplea en cualquier sistema gestor de bases
de datos relacional. Tiene un estndar definido, a partir del cual cada sistema gestor ha
desarrollado su versin propia.
En SQL Server la versin de SQL que se utiliza se llama TRANSACT-SQL.
EL SQL en principio es un lenguaje orientado nicamente a la definicin y al acceso a
los datos por lo que no se puede considerar como un lenguaje de programacin como tal
ya que no incluye funcionalidades como son estructuras condicionales, bucles, formateo
de la salida, etc. (aunque veremos que esto est evolucionando).
Se puede ejecutar directamente en modo interactivo, pero tambin se suele emplear
embebido en programas escritos en lenguajes de programacin convencionales. En estos
programas se mezclan las instrucciones del propio lenguaje (denominado anfitrin) con
llamadas a procedimientos de acceso a la base de datos que utilizan el SQL como
lenguaje de acceso. Como por ejemplo en Visual Basic, Java, C#, PHP .NET, etc.
Las instrucciones SQL se clasifican segn su propsito en tres grupos:
El DDL (Data Description Language) Lenguaje de Descripcin de Datos.
El DCL (Data Control Language) Lenguaje de Control de Datos.
El DML (Data Manipulation Language) Lenguaje de Manipulacin de Datos.
El DDL, es la parte del SQL dedicada a la definicin de la base de datos, consta de
sentencias para definir la estructura de la base de datos, permiten crear la base de datos,
crear, modificar o eliminar la estructura de las tablas, crear ndices, definir reglas de
validacin de datos, relaciones entre las tablas, etc. Permite definir gran parte del nivel
interno de la base de datos. Por este motivo estas sentencias sern utilizadas
normalmente por el administrador de la base de datos.
El DCL (Data Control Language) se compone de instrucciones que permiten:
Ejercer un control sobre los datos tal como la asignacin de privilegios de acceso a
los datos (GRANT/REVOKE).
La gestin de transacciones (COMMIT/ROLLBACK).
Una transaccin se puede definir como un conjunto de acciones que se tienen que
realizar todas o ninguna para preservar la integridad de la base de datos.
Por ejemplo supongamos que tenemos una base de datos para las reservas de avin.
Cuando un usuario pide reservar una plaza en un determinado vuelo, el sistema tiene que
comprobar que queden plazas libres, si quedan plazas reservar la que quiera el usuario
generando un nuevo billete y marcando la plaza como ocupada. Aqu tenemos un proceso
que consta de dos operaciones de actualizacin de la base de datos (crear una nueva fila
en la tabla de billetes y actualizar la plaza reservada en el vuelo, ponindola como
ocupada) estas dos operaciones se tienen que ejecutar o todas o ninguna, si despus de
crear el billete no se actualiza la plaza porque se cae el sistema, por ejemplo, la base de
36
datos quedara en un estado inconsistente ya que la plaza constara como libre cuando
realmente habra un billete emitido para esta plaza. En este caso el sistema tiene el
mecanismo de transacciones para evitar este error. Las operaciones se incluyen las dos
en una misma transaccin y as el sistema sabe que las tiene que ejecutar las dos, si por
lo que sea no se pueden ejecutar las dos, se encarga de deshacer los cambios que se
hubiesen producido para no ejecutar ninguna.
Las instrucciones que gestionan las autorizaciones sern utilizadas normalmente por el
administrador mientras que las otras, referentes a proceso de transacciones sern
utilizadas tambin por los programadores.
No todos los sistemas disponen de ellas.
El DML se compone de las instrucciones para el manejo de los datos, para insertar
nuevos datos, modificar datos existentes, para eliminar datos y la ms utilizada, para
recuperar datos de la base de datos. Veremos que una sola instruccin de recuperacin
de datos es tan potente que permite recuperar datos de varias tablas a la vez, realizar
clculos sobre estos datos y obtener resmenes.
El DML interacta con el nivel externo de la base de datos por lo que sus instrucciones
son muy parecidas, por no decir casi idnticas, de un sistema a otro, el usuario slo indica
lo que quiere recuperar no cmo se tiene que recuperar, no influye el cmo estn
almacenados los datos.
Es el lenguaje que utilizan los programadores y los usuarios de la base de datos.
A lo largo del curso se explicarn cada una de las formas de explotacin de la base de
datos. Dependiendo de tu perfil profesional (programador o administrador) o de tu inters
personal te resultar ms til un bloque u otro.
2.2. Introduccin al TRANSACT-SQL
Como hemos dicho, el sistema gestor de base de datos SQL-Server 2005 utiliza su
propia versin del lenguaje SQL, el TRANSACT-SQL.
TRANSACT-SQL es un lenguaje muy potente que nos permite definir casi cualquier
tarea que queramos efectuar sobre la base de datos. En este tema veremos que
TRANSACT-SQL va ms all de un lenguaje SQL cualquiera ya que incluye
caractersticas propias de cualquier lenguaje de programacin, caractersticas que nos
permiten definir la lgica necesaria para el tratamiento de la informacin:
Tipos de datos.
Definicin de variables.
Estructuras de control de flujo.
Gestin de excepciones.
Funciones predefinidas.
Sin embargo no permite:
Crear interfaces de usuario.
Crear aplicaciones ejecutables, sino elementos que en algn momento llegarn al
servidor de datos y sern ejecutados.
Debido a estas restricciones se emplea generalmente para crear procedimientos
almacenados, triggers y funciones de usuario.
37
Puede ser utilizado como cualquier SQL como lenguaje embebido en aplicaciones
desarrolladas en otros lenguajes de programacin como Visual Basic, C, Java, etc. Y por
supuesto los lenguajes incluidos en la plataforma .NET.
Tambin lo podremos ejecutar directamente de manera interactiva, por ejemplo desde
el editor de consultas de SSMS (SQL Server Management Studio) el entorno de gestin
que ya conocemos. Esta es la forma en que lo utilizaremos nosotros.
Unidad 2. Introduccin al SQL. Transact-SQL (II)
2.3. Caractersticas generales del lenguaje Transact-SQL
El lenguaje SQL se cre con la finalidad de ser un lenguaje muy potente y a la vez muy
fcil de utilizar, se ha conseguido en gran medida ya que con una sola frase (instruccin)
podemos recuperar datos complejos (por ejemplo datos que se encuentran en varias
tablas, combinndolos, calculando resmenes), y utilizando un lenguaje muy cercano al
lenguaje hablado (suponiendo que hablamos ingls, claro!).
Por ejemplo:
SELECT codigo, nombre FROM Clientes WHERE localidad=Valencia;
Esta instruccin nos permite SELECCIONAR el cdigo y nombre DE los Clientes CUYA
localidad sea Valencia.
La sencillez tambin radica en que lo que indicamos es lo que queremos obtener, no el
cmo lo tenemos que obtener, de eso se encargar el sistema automticamente.
Las sentencias SQL adems siguen todas el mismo patrn:
Empiezan por un verbo que indica la accin a realizar,
completado por el objeto sobre el cual queremos realizar la accin,
seguido de una serie de clusulas (unas obligatorias, otras opcionales) que
completan la frase, y proporcionan ms detalles acerca de lo que se quiere hacer.
Si sabemos algo de ingls nos ser ms fcil interpretar a la primera lo que quiere decir
la instruccin, y de lo contrario, como el nmero de palabras que se emplean es muy
reducido, enseguida nos las aprenderemos.
Por ejemplo en el DDL (acciones sobre la definicin de la base de datos), tenemos
3 verbos bsicos:
CREATE (Crear)
DROP (Eliminar)
ALTER (Modificar)
Completados por el tipo de objeto sobre el que actan y el objeto concreto:
CREATE DATABASE mibase .......;
Permite crear una base de datos llamada mibase, a continuacin escribiremos las
dems clusulas que completarn la accin, en este caso dnde se almacenar la base
de datos, cunto ocupar, etc...
CREATE TABLE mitabla (.....);
38
Permite crear una nueva tabla llamada mitabla, entre parntesis completaremos la
accin indicando la definicin de las columnas de la tabla.
CREATE INDEX miindex...;
Lo mismo para crear un ndice (a que lo habais adivinado?).
DROP DATABASE mibase;
Permite borrar, eliminar la base de datos mibase.
DROP TABLE mitabla;
Elimina la tabla mitabla.
ALTER TABLE mitabla.....;
Permite modificar la definicin de la tabla mitabla.
En el DML (acciones sobre los datos almacenados) utilizaremos los verbos:
INSERT (Crear, es decir, insertar una nueva fila de datos)
DELETE (Eliminar filas de datos)
UPDATE (Modificar filas de datos)
SELECT (Seleccionar, obtener)
Por ejemplo:
INSERT INTO mitabla ..... Inserta nuevas filas en mitabla
DELETE FROM mitabla Eliminar filas de mitabla
UPDATE mitabla ....... Actualiza filas de mitabla
Como ejemplo de clusula dentro de una instruccin tenemos:
SELECT codigo, nombre
FROM Clientes
WHERE localidad=Valencia;
En esta sentencia nos aparecen dos clusulas, la clusula FROM que nos permite
indicar de dnde hay que coger los datos y la clusula WHERE que permite indicar una
condicin de seleccin.
Otra caracterstica de una sentencia SQL es que acaba con un punto y coma (;)
originalmente ste era obligatorio y serva para indicar el fin de la instruccin, pero ahora
se puede omitir, aunque se recomienda su uso.
En una sentencia utilizaremos palabras reservadas (las fijas del lenguaje), y
nombres de objetos y variables (identificadores).
Las palabras reservadas no se pueden utilizar para otro propsito, por ejemplo una
tabla no se puede llamar FROM, y los nombres (los identificadores) siguen las reglas
detalladas en el punto siguiente.
39
Nombres cualificados. En ocasiones deberemos utilizar nombres cualificados, por
ejemplo cuando se escribe un nombre de tabla, SQL presupone que se est refiriendo a
una de las tablas de la base de datos activa, si queremos hacer referencia a una tabla de
otra base de datos utilizamos su nombre cualificado
nombrebasedatos.nombredeesquema.nombretabla, utilizamos el punto para separar el
nombre del objeto y el nombre de su contenedor.
O por ejemplo si en una consulta cuyo origen son dos tablas, queremos hacer
referencia a un campo y ese nombre de campo es un nombre de campo en las dos tablas,
pues utilizaremos su nombre cualificado nombretabla.nombrecampo.
El valor NULL.
Puesto que una base de datos es un modelo de una situacin del mundo real, ciertos
datos pueden inevitablemente faltar, ser desconocidos o no ser aplicables, esto se debe
de indicar de alguna manera especial para no confundirlo con un valor conocido pero que
sea cero por ejemplo, SQL tiene para tal efecto el valor NULL que indica precisamente la
ausencia de valor.
Por ejemplo: no es lo mismo que el alumno no tenga nota a que tenga la nota cero, esto
afectara tambin a todos los clculos que se pueden realizar sobre la columna nota.
Unidad 2. Introduccin al SQL. Transact-SQL (III)
2.4. Reglas de formato de los identificadores
Los identificadores son los nombres de los objetos de la base de datos. Cualquier
elemento de Microsoft SQL Server 2005 puede tener un identificador: servidores, bases
de datos, tablas, vistas, columnas, ndices, desencadenadores, procedimientos,
restricciones, reglas, etc.
Las reglas de formato de los identificadores normales dependen del nivel de
compatibilidad de la base de datos, que se estableca con el parmetro sp_dbcmptlevel
pero que ahora Microsoft aconseja no utilizar ya que desaparecer en versiones
posteriores en vez de eso se tiene que utilizar la clusula SET COMPATIBILITY_LEVEL
de la instruccin ALTER TABLE. Cuando el nivel de compatibilidad es 90, (el asignado por
defecto) se aplican las reglas siguientes para los nombres de los identificadores:
No puede ser una palabra reservada.
El nombre debe tener entre 1 y 128 caracteres, excepto para algunos tipos de
objetos en los que el nmero es ms limitado.
El nombre debe empezar por:
o Una letra, como aparece definida por el estndar Unicode 3.2. La
definicin Unicode de letras incluye los caracteres latinos de la "a" a la
"z" y de la "A" a la "Z".
o El carcter de subrayado ( _ ), arroba ( @ ) o nmero ( #).
Ciertos smbolos al principio de un identificador tienen un significado especial en
SQL Server. Un identificador que empieza con el signo de arroba indica un
parmetro o una variable local. Un identificador que empieza con el signo de nmero
indica una tabla o procedimiento temporal. Un identificador que empieza con un
signo de nmero doble (##) indica un objeto temporal global.
Algunas funciones de Transact-SQL tienen nombres que empiezan con un doble
signo de arroba (@@). Para evitar confusiones con estas funciones, se recomienda
no utilizar nombres que empiecen con @@.
40
No se permiten los caracteres especiales o los espacios incrustados.
Si queremos utilizar un nombre que no siga estas reglas, normalmente para poder
incluir espacios en blanco, lo tenemos que escribir encerrado entre corchetes [ ] (tambin
se pueden utilizar las comillas pero recomendamos utilizar los corchetes).
2.5. Tipos de datos
En SQL Server 2005, cada columna, expresin, variable y parmetro est asociado a
un tipo de datos.
Un tipo de datos, realmente define el conjunto de valores vlidos para los campos
definidos de ese tipo. Indica si el campo puede contener: datos numricos, de caracteres,
moneda, fecha y hora, etc.
SQL Server proporciona un conjunto de tipos de datos del sistema que define todos los
tipos de datos que pueden utilizarse. Tambin podemos definir nuestros propios tipos de
datos en Transact-SQL o Microsoft .NET Framework.
Los tipos de datos ms utilizados son:
Los numricos: int, decimal, money
Los de fecha y hora: datetime
Y las cadenas de caracteres: varchar
Si quieres conocer todos los tipos de datos disponibles en SQLServer 2005, visita el
siguiente avanzado .
2.6. Las constantes
Una constante es un valor especfico o un smbolo que representa un valor de dato
especfico. El formato de las constantes depende del tipo de datos del valor que
representan. En este apartado veremos las ms utilizadas.
Las constantes numricas se escriben mediante una cadena de nmeros, con la
consideracin de que el separador decimal es un punto, no una coma, y que si se
trata de un valor monetario deberemos incluir la moneda al inicio de la constante.
Por ejemplo: 85.90 y 85.90, el primero sera un valor decimal y el segundo un valor
money. De forma predeterminada, los valores sern positivos. Para indicar lo
contrario escribimos el signo - al principio.
Las constantes de fecha y hora van entre comillas simples y con un formato de
fecha y hora adecuado. Por ejemplo: '03/10/90'.
Y las constantes en cadenas de caracteres van entre comillas simples. Por
ejemplo: 'J uan Garca Lpez'.
Para indicar valores negativos y positivos aadimos el prefijo + o - segn sea el valor
positivo o negativo. Sin prefijo se entiende que el valor es positivo.
Si quieres ver cmo definir constantes para otros tipos de datos, visita el siguiente
avanzado (arriba).
Unidad 2. Introduccin al SQL. Transact-SQL (IV)
2.7. Las expresiones
41
Una expresin es una combinacin de smbolos y operadores que el motor de base de
datos de SQL Server evala para obtener un nico valor. Una expresin simple puede ser
una sola constante, variable, columna o funcin escalar. Los operadores se pueden usar
para combinar dos o ms expresiones simples y formar una expresin compleja.
Dos expresiones pueden combinarse mediante un operador si ambas tienen tipos de
datos admitidos por el operador y se cumple al menos una de estas condiciones:
Las expresiones tienen el mismo tipo de datos.
El tipo de datos de menor prioridad se puede convertir implcitamente al tipo de
datos de mayor prioridad.
La funcin CAST puede convertir explcitamente el tipo de datos con menor prioridad
al tipo de datos con mayor prioridad o a un tipo de datos intermedio que pueda
convertirse implcitamente al tipo de datos con la mayor prioridad.
Tipos de operadores:
- Operadores numricos:
suma +
resta -
multiplicacin *
divisin /
mdulo
(resto de una divisin)
%
- Operadores bit a bit: realizan manipulaciones de bits entre dos expresiones de
cualquiera de los tipos de datos de la categora del tipo de datos entero.
AND &
OR |
OR exclusivo ^
- Operadores de comparacin:
Igual a =
Mayor que >
Menor que <
Mayor o igual que >=
42
Menor o igual que <=
Distinto de <>
No es igual a !=
No menor que !<
No mayor que !>
- Operadores lgicos:
Aqu slo los nombraremos ya que en el tema de consultas simples los veremos en
detalle.
ALL IN
AND LIKE
ANY NOT
BETWEEN OR
EXISTS SOME
- Operadores de cadenas:
Concatenacin +
Resultados de la expresin
- Si se combinan dos expresiones mediante operadores de comparacin o lgicos, el
tipo de datos resultante es booleano y el valor es uno de los siguientes: TRUE, FALSE o
UNKNOWN.
- Cuando dos expresiones se combinan mediante operadores aritmticos, bit a bit o de
cadena, el operador determina el tipo de datos resultante.
Las expresiones complejas formadas por varios smbolos y operadores se evalan
como un resultado formado por un solo valor. El tipo de datos, intercalacin, precisin y
valor de la expresin resultante se determina al combinar las expresiones componentes
de dos en dos, hasta que se alcanza un resultado final. La prioridad de los operadores de
la expresin define la secuencia en que se combinan las expresiones.
Unidad 2. Introduccin al SQL. Transact-SQL (V)
2.8. Funciones
43
SQL Server 2005 proporciona numerosas funciones integradas y permite crear
funciones definidas por el usuario.
Existen diferentes tipos de funciones:
Funciones de conjuntos de filas: devuelven un objeto que se puede utilizar, en
instrucciones Transact-SQL, en lugar de una referencia a una tabla.
Funciones de agregado (tambin llamadas funciones de columna): Operan sobre
una coleccin de valores y devuelven un solo valor de resumen. Por ejemplo, la
funcin de suma sobre la columna importe para conocer el importe total:
SUM(importe)
Funciones de categora: Devuelven un valor de categora para cada fila de un
conjunto de filas, por ejemplo devuelve el nmero de la fila, el ranking de la fila en
una determinada ordenacin, etc.
Funciones escalares: Operan sobre un valor y despus devuelven otro valor. Son las
funciones que estamos acostumbrados a utilizar. Las funciones escalares se
clasifican segn el tipo de datos de sus operandos
Las variables
En Transact-SQL podemos definir variables, que sern de un tipo de datos
determinado, como tipos de datos podemos utilizar los propios de la base de datos SQL-
SERVER, pero tambin podemos utilizar tipos propios del lenguaje que no pueden ser
utilizados en DDL. El tipo Cursor y el tipo Table son dos de estos tipos.
Las variables se definen utilizando la instruccin DECLARE con el siguiente formato:
DECLARE @nbvariable tipo
El nombre de la variable debe empezar por el smbolo @, este smbolo hace que SQL
interprete el nombre como un nombre de variable y no un nombre de objeto de la base de
datos.
Por ejemplo: DECLARE @empleados INT
Con esto hemos definido la variable @empleados de tipo entero.
Para asignar un valor a una variable, la asignacin se realiza con la palabra SELECT y
el signo igual con el formato:
SELECT @nbvariable = valor
El valor puede ser cualquier valor constante, otro nombre de variable, una expresin
vlida o algo ms potente, parte de una sentencia SELECT de SQL.
Por ejemplo:
SELECT @empleados = 0;
SELECT @empleados = @otra * 100;
SELECT @EMPLEADOS = COUNT(numemp) FROM empleados;
El valor almacenado en la variable se puede visualizar mediante la orden PRINT. o
SELECT
PRINT @nbvariable o SELECT @nbvariable
44
El valor almacenado en la variable se visualizar en la pestaa de resultados. Tambin
se puede usar para escribir mensajes:
PRINT 'Este es el mensaje'
Otros elementos del lenguaje
Comentarios. Como en cualquier otro lenguaje de programacin, debemos utilizar
comentarios destinados a facilitar la legibilidad del cdigo. En SQL se insertan
comentarios con los signos:
/* */ Varias lneas
/* Esto es un comentario
en varias lneas */
-- Una nica lnea -- Esto es un comentario en una nica lnea.
USE. Cambia el contexto de la base de datos al de la base de datos especificada.
USE nbBaseDeDatos
Hace que la base de datos activa pase a ser la base de datos indicada en la instruccin,
las consultas que se ejecuten a continuacin se harn sobre tablas de esa base de datos
si no se indica lo contrario. Es una instruccin til para asegurarnos de que la consulta se
ejecuta sobre la base de datos correcta.
GO
GO no es una instruccin Transact-SQL, sino un comando reconocido por las utilidades
sqlcmd y osql, as como por el Editor de cdigo de SQL Server Management Studio.
Las utilidades de SQL Server interpretan GO como una seal de que deben enviar el lote
actual de instrucciones Transact-SQL a una instancia de SQL Server. El lote actual de
instrucciones est formado por todas las instrucciones especficadas desde el ltimo
comando GO o desde el comienzo de la sesin o script si se trata del primer comando
GO.
Por ejemplo si queremos crear una consulta para crear una base de datos y sus tablas,
despus del CREATE DATABASE; tenemos que poner GO antes del primer CREATE
TABLE para que el sistema efecte la primera operacin y la base de datos est creada
antes de ejecutar el primer CREATE TABLE.
BEGIN...END
Encierra un conjunto de instrucciones Transact-SQL de forma que estas instrucciones
formen un bloque de instrucciones.
Unidad 3. Consultas simples (I)
3.1. Introduccin
Vamos a empezar por la instruccin que ms se utiliza en SQL, la sentencia SELECT.
La sentencia SELECT es, con diferencia, la ms compleja y potente de las sentencias
SQL, con ella podemos recuperar datos de una o ms tablas, seleccionar ciertos registros
e incluso obtener resmenes de los datos almacenados en la base de datos. Es tan
compleja que la estudiaremos a lo largo de varias unidades didcticas incorporando poco
a poco nuevas funcionalidades.
45
El resultado de una SELECT es una tabla lgica que alberga las filas resultantes de la
ejecucin de la sentencia.
La sintaxis completa es la siguiente:
SELECT sentencia::=[WITH <expresion_tabla_comun> [,...n]]
<expresion_consulta>
[ORDER BY {expression_columna|posicion_columna [ASC|DESC]
}
[ ,...n ]]
[COMPUTE
{{AVG|COUNT|MAX|MIN|SUM} (expression)}[ ,...n ] [BY
expression[ ,...n ]]
]
[<FOR clausula_for>]
[OPTION (<query_hint>[ ,...n ])]
<expresion_consulta> ::=
{<especificacion_consulta> | ( < expresion_consulta > )
}
[ {UNION [ALL]|EXCEPT|INTERSECT}
<especificacion_consulta> | (<expresion_consulta>)
[...n ]
]
<especificacion_consulta> ::=
SELECT [ALL|DISTINCT]
[TOP expresion [PERCENT] [WITH TIES] ]
<lista_seleccion>
[INTO nueva_tabla]
[FROM { <origen> } [ ,...n ] ]
[WHERE <condicion_busqueda> ]
[GROUP BY [ ALL ] expresion_agrupacion [ ,...n ]
[WITH { CUBE | ROLLUP } ]
]
[HAVING < condicion_busqueda > ]
Debido a la complejidad de la sentencia (en la sintaxis anterior no se han detallado
algunos elementos), la iremos viendo poco a poco, empezaremos por ver consultas
bsicas para luego ir aadiendo ms clusulas.
Empezaremos por ver las consultas ms simples, basadas en una sola tabla y nos
limitaremos a la siguiente sintaxis:
SELECT [ALL|DISTINCT]
46
[TOP expresion [PERCENT] [WITH TIES]]
<lista_seleccion>
FROM <origen>
[WHERE <condicion_busqueda> ]
[ORDER BY {expression_columna|posicion_columna [ASC|DESC]} [
,...n ]]
3.2. Origen de datos FROM
De la sintaxis anterior, el elemento <origen> indica de dnde se va a extraer la
informacin y se indica en la clusula FROM, es la nica clusula obligatoria. En este
tema veremos un origen de datos basado en una sola tabla.
La sintaxis ser la siguiente:
<origen>::=
nb_tabla | nb_vista [[ AS ] alias_tabla ]
nb_tabla representa un nombre de tabla.
nb_vista un nombre de vista.
Tanto para las tablas como para las vistas, podemos hacer referencia a tablas que
estn en otras bases de datos (siempre que tengamos los permisos adecuados), en este
caso tenemos que cualificar el nombre de la tabla, indicando delante el nombre de la base
de datos (Lgica) y el nombre del esquema al que pertenece la tabla dentro de la base de
datos.
Por ejemplo: MiBase.dbo.MiTabla se refiere a la tabla MiTabla que se encuentra en
el esquema dbo de la base de datos MiBase.
Cuando no se definen esquemas, SQL-Server crea uno por defecto en cada base de
datos denominado dbo.
Opcionalmente podemos definir un nombre de alias.
Un nombre de alias (alias_tabla) es un nombre alternativo que se le da a la tabla
dentro de la consulta.
Si se define un nombre de alias, dentro de la consulta, ser el nombre a utilizar para
referirnos a la tabla, el nombre original de la tabla ya no tendr validez.
Se utilizan los nombres de alias para simplificar los nombres de tablas a veces largos y
tambin cuando queremos combinar una tabla consigo misma; ya volveremos sobre los
alias de tabla cuando veamos consultas multitabla.
La palabra AS no aade ninguna operatividad, est ms por esttica.
Podemos escribir:
SELECT ...
FROM tabla1 Sacamos los datos de la tabla tabla1
47
SELECT ...
FROM tabla1 t1 Sacamos los datos de la tabla tabla1 y le
asignamos un alias de tabla: t1
SELECT ...
FROM tabla1 AS t1 Es equivalente a la sentencia anterior.
Si la tabla o la vista estn en otra base de datos del mismo equipo que est ejecutando
la instancia de SQL Server, se utiliza el nombre cualificado con el formato
nbBaseDatos.nbEsquema.nbTabla.
Si la tabla o la vista estn fuera del servidor local en un servidor vinculado, se utiliza un
nombre de cuatro partes con el formato nbservidor.catalogo.nbEsquema.nbTabla.
Volveremos ms adelante sobre las conexiones remotas.
Unidad 3. Consultas simples (II)
3.3. La lista de seleccin
En la lista de seleccin <lista_seleccion>indicamos las columnas que se tienen que
visualizar en el resultado de la consulta.
<lista_seleccion> ::=
{ *
| {nombre_tabla|nombre_vista|alias_tabla}.*
| { [{nombre_tabla|nombre_vista|alias_tabla}.]
{nb_columna|$IDENTITY|$ROWGUID}
|<expresion>
}[[AS] alias_columna]
| alias_columna = <expresion>
} [ ,...n ]
Separamos la definicin de cada columna por una coma y las columnas del resultado
aparecern en el mismo orden que en la lista de seleccin.
Para cada columna del resultado su tipo de datos, tamao, precisin y escala son los
mismos que los de la expresin que da origen a esa columna.
Podemos definir las columnas del resultado de varias formas, mediante:
Una expresin simple:
o una referencia a una funcin.
o una variable local
o una constante
o una columna del origen de datos,
48
Una subconsulta escalar, que es otra instruccin SELECT que devuelve un nico
valor y se evala para cada fila del origen de datos (esto no lo veremos de
momento).
Una expresin compleja generada al usar operadores en una o ms expresiones
simples.
La palabra clave *.
La asignacin de variables con el formato @variable_local = expresin.
La palabra clave $IDENTITY.
La palabra clave $ROWGUID.
3.4. Columnas del origen de datos
Cuando queremos indicar en la lista de seleccin una columna del origen de datos, la
especificamos mediante su nombre simple o nombre cualificado. El nombre cualificado
consiste en el nombre de la columna precedido del nombre de la tabla donde se encuentra
la columna.
Si en el origen de datos hemos utilizado una vista o un nombre de alias, deberemos
utilizar ese nombre. Es obligatorio utilizar el nombre cualificado cuando el nombre de la
columna aparece en ms de una tabla del origen de datos.
Ejemplos de consulta simple.
Listar nombres, oficinas, y fechas de contrato de todos los empleados:
SELECT nombre, oficina, contrato
FROM empleados;
El resultado sera:
nombre oficina contrato
Antonio Viguer 12 1986-10-20
Alvaro Jaumes 21 1986-12-10
Juan Rovira 12 1987-03-01
Jos Gonzlez 12 1987-05-19
Vicente Pantalla 13 1988-02-12
Luis Antonio 11 1988-06-14
Jorge Gutirrez 22 1988-11-14
Ana Bustamante 21 1989-10-12
Mara Sunta 11 1999-10-12
49
Juan Victor NULL 1990-01-13
Listar una tarifa de productos:
SELECT idfab, idproducto, descripcion, productos.precio
FROM productos;
Hemos cualificado la columna precio aunque no es necesario en este caso.
El resultado sera:
Idfab idproducto descripcion precio
aci 41001 arandela 0,58
aci 41002 bisagra 0,80
aci 41003 art t3 1,12
aci 41004 art t4 1,23
aci 4100x junta 0,26
aci 4100y extractor 28,88
aci 4100z mont 26,25
bic 41003 manivela 6,52
bic 41089 rodamiento 2,25
Unidad 3. Consultas simples (III)
3.5. Alias de columna
Por defecto, en el encabezado de cada columna del resultado, aparece el nombre de la
columna origen, pero esto se puede cambiar definiendo un alias de columna, el alias de
columna es un nombre alternativo que se le da a esa columna.
El alias de columna se indica mediante la clusula AS. Se escribe el nuevo texto tal cual
sin comillas siguiendo las reglas de los identificadores.
Ejemplo:
SELECT numclie,nombre AS nombrecliente
FROM clientes;
50
El resultado ser :
Numclie nombrecliente
2101 Luis Garca Antn
2102 Alvaro Rodrguez
2103 Jaime Llorens
en vez de:
Numclie nombre
2101 Luis Garca Antn
2102 Alvaro Rodrguez
2103 Jaime Llorens
La palabra AS es opcional.
SELECT numclie,nombre nombrecliente
FROM clientes;
Sera equivalente a la consulta anterior
Si queremos incluir espacios en blanco en el nombre lo debemos encerrar entre
corchetes.
SELECT numclie,nombre AS [nombre cliente]
FROM clientes;
Nota importante: Este nombre de alias se podr utilizar en la lista de seleccin y en la
clusula ORDER BY pero no en la clusula WHERE.
3.6. Funciones
Existen funciones que podemos utilizar en la lista de seleccin, e incluso en otras
clusulas que veremos ms adelante, como el WHERE. Las principales funciones son las
siguientes:
Funciones de fecha:
Funcin Descripcin
Ver
+
GETDATE Devuelve la fecha actual.
51
GETUTCDATE Devuelve la hora UTC.
DATEPART Devuelve un entero que corresponde a la parte de la fecha solicitada.
DAY Devuelve el da de la fecha indicada.
MONTH Devuelve el mes de la fecha indicada.
YEAR Devuelve el ao de la fecha indicada.
DATENAME
Devuelve una cadena de caracteres que representa el valor de la unidad especificada
de una fecha especificada.
DATEADD
Devuelve un valor datetime nuevo que resulta de sumar un intervalo de tiempo a una
fecha especificada.>
DATEDIFF Devuelve el n de intervalos que hay entre dos fechas.
@@DATEFIRST Devuelve el primer da de la semana establecido con SET DATEFIRST.
SET
DATEFIRST
Establece el primer da de la semana en un nmero del 1 al 7.
Unidad 3. Consultas simples (IV)
Funciones de cadena:
Funcin Descripcin
Ver
+
ASCII
Devuelve el valor de cdigo ASCII del carcter situado ms a la izquierda de una expresin
de caracteres.
CHAR Devuelve el carcter ASCII del entero indicado.
NCHAR Devuelve el carcter Unicode del entero indicado.
UNICODE Devuelve el entero que se corresponde al carcter Unicode indicado.
LEN Devuelve el total de caracteres de una cadena, excluidos los espacios en blanco finales.
LTRIM Devuelve una cadena tras quitarle los espacios en blanco iniciales.
RTRIM Devuelve una cadena tras quitarle los espacios en blanco finales.
52
LEFT Devuelve los N ltimos caracteres de una cadena.
RIGHT Devuelve los N primeros caracteres de una cadena.
SUBSTRING Devuelve parte de una expresin.
LOWER Devuelve la cadena convertida a minsculas.
UPPER Devuelve la cadena convertida a maysculas.
REPLACE Reemplaza una determinada cadena.
STUFF
Elimina el nmero de caracteres especificado e inserta otro conjunto de caracteres en el
punto de inicio indicado.
QUOTENAME
Devuelve una cadena Unicode con los delimitadores agregados para convertirla en un
identificador delimitado vlido de Microsoft SQL Server 2005.
SPACE Devuelve una cadena de espacios repetidos.
STR Devuelve una cadena de caracteres a partir de datos numricos.
REPLICATE Repite una cadena N veces.
REVERSE Devuelve una cadena invertida.
CHARINDEX Devuelve la posicin inicial de la expresin especificada en una cadena de caracteres.
PATINDEX
Devuelve la posicin inicial de la primera repeticin de un patrn en la expresin
especificada, o ceros si el patrn no se encuentra, en todos los tipos de datos de texto y
caracteres.
Otras funciones:
Funcin Descripcin
Ver
+
ROUND Redondea un valor a la longitud y precisin indicadas.
CAST y CONVERT Convierten de un tipo de datos a otro de forma explcita.
CASE Evala una lista de condiciones.
ISNULL Reemplaza el valor NULL por otro especificado.
COALESCE Devuelve la primera expresin distinta de NULL entre sus argumentos.
53
Unidad 3. Consultas simples (V)
3.7. Columnas calculadas
Adems de las columnas que provienen directamente de la tabla origen, una consulta
SQL puede incluir columnas calculadas cuyos valores se evalan a partir de una
expresin.
La expresin puede contener cualquier operador vlido (+, -, *, /, &), cualquier funcin
vlida, nombres de columnas del origen de datos, nombres de parmetros o constantes y
para combinar varias operaciones se pueden utilizar los parntesis.
Ejemplos de columnas calculadas:
Listar la ciudad, regin y el supervit de cada oficina. Consideraremos el supervit
como el volumen de ventas que se encuentran por encima o por debajo del objetivo de la
oficina.
SELECT ciudad, region, (ventas-objetivo) AS superavit
FROM oficinas;
El resultado ser:
ciudad region superavit
Valencia este 11800,00
Alicante este -6500,00
Castellon este 1800,00
Badajoz oeste 11100,00
A Corua oeste -11400,00
Madrid centro NULL
Madrid centro -10000,00
Pamplona norte NULL
Valencia este -90000,00
De cada producto queremos saber el id de fabricante, id de producto, su descripcin y
el valor de sus existencias.
SELECT idfab,idproducto,descripcion,(existencias*precio) AS
valoracion
FROM productos;
54
El resultado sera:
Idfab idproducto descripcion valoracion
aci 41001 arandela 160,66
aci 41002 bisagra 133,60
aci 41003 art t3 231,84
aci 41004 art t4 170,97
aci 4100x junta 9,62
aci 4100y extractor 722,00
aci 4100z mont 735,00
bic 41003 manivela 19,56
bic 41089 rodamiento 175,50
Unidad 3. Consultas simples (VI)
Listar el nombre, mes y ao del contrato de cada vendedor.
SELECT nombre, MONTH(contrato) AS [Mes de contrato],
YEAR(contrato) AS [Ao de contrato]
FROM empleados;
El resultado ser:
Nombre Mes de contrato Ao de contrato
Antonio Viguer 10 1986
Alvaro Jaumes 12 1986
Juan Rovira 3 1987
Para practicar puedes realizar este Ejercicio Funciones en la lista de seleccin.
Listar las ventas en cada oficina con el formato: 22 tiene ventas de 186,042.00
SELECT oficina, 'tiene ventas de ' AS [ ], ventas
FROM oficinas;
55
El resultado sera:
oficina ventas
11 tiene ventas de 69300,00
12 tiene ventas de 73500,00
13 tiene ventas de 36800,00
21 tiene ventas de 83600,00
22 tiene ventas de 18600,00
23 tiene ventas de NULL
24 tiene ventas de 15000,00
26 tiene ventas de NULL
28 tiene ventas de 0,00
El incluir una constante como columna en la lista de seleccin puede parecer intil (se
repetir el mismo valor en todas las filas) pero veremos ms adelante que tiene utilidad en
ciertos casos.
Tambin podemos utilizar la sintaxis:
alias_columna = <expresion>
Ejemplo:
SELECT oficina, superavit = ventas-objetivo
Esto tiene el mismo efecto que
SELECT oficina, ventas-objetivo AS superavit
Unidad 3. Consultas simples (VII)
3.8. Utilizacin del asterisco *
Si queremos visualizar todas las columnas del origen de datos, en lugar de indicar
todas las columnas una a una se puede utilizar el carcter de sustitucin *.
Mostrar todos los datos de la tabla oficinas.
SELECT *
56
FROM oficinas;
Obtener todos los datos y el supervit de cada oficina.
SELECT *, (ventas-objetivo) AS superavit
FROM oficinas;
Tambin podemos cualificar el * con un nombre de tabla, de vista o un alias de tabla:
SELECT oficinas.*
FROM oficinas;
oficinas.* se interpreta como: todas las columnas de la tabla oficinas.
Esta forma se utiliza normalmente cuando el origen est basado en varias tablas y
queremos indicar todas las columnas no del origen completo sino de una tabla concreta.
Para practicar puedes realizar este Ejercicio La palabra clave *.
3.9. Las palabras clave $IDENTITY y $ROWGUID
La palabra clave $IDENTITY se interpreta como la columna de la tabla que tiene la
propiedad IDENTITY (la columna de identidad que vimos en un tema anterior).
Por ejemplo, si en la columna codigo de la tabla usuarios (BD Biblio) se ha definido la
propiedad IDENTITY.
SELECT $IDENTITY, nombre, apellidos
FROM usuarios;
Es equivalente a:
SELECT codigo, nombre, apellidos
FROM usuarios;
La palabra clave $ROWGUID se interpreta como la columna de la tabla que tiene la
propiedad ROWGUIDCOL y se puede utilizar de la misma forma que $IDENTITY.
Unidad 3. Consultas simples (VIII)
3.10. Ordenacin de las filas del resultado ORDER BY
Si queremos que las filas del resultado de la consulta aparezcan ordenadas, lo
podemos indicar mediante la clusula ORDER BY.
ORDER BY {expression_columna|posicion_columna [ASC|DESC]}[ ,...n ]
57
Podemos indicar una columna o varias separadas por una coma, la columna de
ordenacin se especifica mediante el nombre de columna en el origen de datos o su
posicin dentro de la lista de seleccin. Si utilizamos el nombre de columna, no hace falta
que la columna aparezca en la lista de seleccin. Si utilizamos la posicin es la posicin
de la columna dentro de la lista de seleccin empezando en 1.
Por defecto la filas se ordenarn en modo ascendente (ASC), de menor a mayor; si
queremos invertir ese orden aadimos detrs de la columna la palabra DESC.
Si la columna de ordenacin es alfanumrica, las filas se ordenarn por orden
alfabtico.
Si la columna de ordenacin es numrica, las filas se ordenarn de menor a mayor.
Si la columna de ordenacin es de tipo fecha, las filas se ordenarn de ms antigua a ms
reciente o futura.
Ejemplos:
Mostrar las ventas de cada oficina, ordenadas por orden alfabtico de regin y dentro
de cada regin por ciudad.
SELECT oficina, region, ciudad, ventas
FROM oficinas
ORDER BY region, ciudad;
Da como resultado:
Oficina region ciudad ventas
24 centro Aranjuez 15000,00
23 centro Madrid NULL
12 este Alicante 73500,00
13 este Castelln 36800,00
11 este Valencia 69300,00
28 este Valencia 0,00
26 norte Pamplona NULL
22 oeste A Corua 18600,00
21 oeste Badajoz 83600,00
Listar las oficinas de manera que las oficinas de mayores ventas aparezcan en primer
lugar.
SELECT ciudad, region, ventas
58
FROM oficinas
ORDER BY ventas DESC;
ciudad region ventas
Badajoz oeste 83600,00
Alicante este 73500,00
Valencia este 69300,00
Castellon este 36800,00
A Corua oeste 18600,00
Aranjuez centro 15000,00
Valencia este 0,00
Pamplona norte NULL
Madrid centro NULL
Listar las oficinas clasificadas en orden descendente de rendimiento de ventas, de
modo que las de mayor rendimiento aparezcan las primeras.
SELECT ciudad, region, ventas-objetivo
FROM oficinas
ORDER BY 3 DESC;
Lo mismo que el anterior pero agrupadas por regin.
SELECT region, ciudad, (ventas-objetivo) AS superavit
FROM oficinas
ORDER BY region, superavit DESC;
Resultado:
Region ciudad superavit
centro Aranjuez -10000,00
centro Madrid NULL
este Valencia 11800,00
59
este Castelln 1800,00
este Alicante -6500,00
este Valencia -90000,00
norte Pamplona NULL
oeste Badajoz 11100,00
oeste A Corua -11400,00
En este caso hemos utilizado el alias de columna para hacer referencia a la columna
calculada y tambin se puede observar que las filas aparecen ordenadas por regin
ascendente (no hemos incluido nada despus del nombre de la columna) y dentro de cada
regin por supervit y descendente.
Unidad 3. Consultas simples (IX)
3.11. Eliminar filas duplicadas DISTINCT/ALL
SQL no elimina las filas duplicadas en el resultado de la consulta, si nosotros no
queremos que se repitan las filas, tenemos la clusula DISTINCT.
Al incluir la clusula DISTINCT en la SELECT, se eliminar del resultado las repeticiones
de filas de resultado. Si por el contrario queremos que aparezcan todas las filas
seleccionadas podemos incluir la clusula ALL o nada, ya que ALL es el valor por defecto.
Listar los n de empleado de los directores de las oficinas.
SELECT dir
FROM oficinas;
dir
106
104
105
108
108
108
108
60
NULL
NULL
Si un mismo empleado dirige varias oficinas (por ejemplo el 108), su cdigo aparece
repetido en el resultado. Para evitarlo modificamos la consulta:
SELECT DISTINCT dir
FROM oficinas;
dir
NULL
104
105
106
108
Han desaparecido los valores duplicados.
Los que se eliminan son valores duplicados de filas del resultado, por ejemplo:
SELECT DISTINCT dir, region
FROM oficinas;
dir region
NULL este
NULL norte
104 este
105 este
106 este
108 centro
108 oeste
Ahora el 108 aparece dos veces porque las dos filas donde aparece no son iguales
(porque tienen distinta regin).
61
NOTA: La clusula DISTINCT hace que la consulta tarde algo ms en ejecutarse
debido al proceso adicional de buscar y eliminar las repeticiones, por lo que se aconseja
utilizarla nicamente cuando sea imprescindible.
Para practicar puedes realizar este Ejercicio Eliminar filas duplicadas.
Unidad 3. Consultas simples (X)
3.12. La clusula TOP
[TOP <expresin> [PERCENT] [WITH TIES]]
La clusula TOP indica que en el resultado no deben aparecer todas las filas
resultantes sino un cierto nmero de registros, las n primeras. Si la consulta incluye la
clusula ORDER BY, se realiza la ordenacin antes de extraer los n primeros registros.
La expresin representa ese nmero n y debe devolver un nmero entero sin signo.
Por ejemplo tenemos la siguiente tabla:
SELECT * FROM productos:
Si ordenamos por ventas:
SELECT * FROM productos
ORDER BY ventas;
Obtenemos el siguiente resultado:
Si aadimos la clusula TOP:
62
SELECT TOP 3 * FROM productos
ORDER BY ventas
Obtenemos los 3 primeros registros:
Si existen ms registros con las mismas ventas que el ltimo valor de la lista, stos no
saldrn en el resultado de la consulta.
En el ejemplo el registro con cod = 2 no sale en el resultado y tiene las mismas ventas
que cod = 3.
Si queremos que salgan aadimos la clusula WITH TIES. La clusula WITH TIES slo
se puede emplear si la SELECT incluye un ORDER BY, de lo contrario dar error.
Si aadimos la clusula WITH TIES:
SELECT TOP 3 WITH TIES *
FROM productos
ORDER BY ventas
Obtenemos:
Se incluyen en el resultado todos los registros que tienen ventas iguales al ltimo
registro.
Otro ejemplo:
SELECT TOP 10 oficina, ciudad, ventas FROM oficinas
ORDER BY ventas;
Devuelve las 10 peores oficinas en cuanto a ventas: ordenamos las oficinas por ventas
de menor a mayor y sacamos las 10 primeras.
Si incluimos la palabra PERCENT, entonces n no indica el nmero de registros a
recuperar sino el porcentaje de registros a recuperar del total de filas recuperadas
despus de ejecutar la clusula WHERE.
63
SELECT TOP 50 PERCENT * FROM productos ORDER BY ventas
Devuelve:
Si el porcentaje no da exacto, siempre redondea al alza.
Unidad 3. Consultas simples (XI)
3.13. Seleccin de filas WHERE
La clusula WHERE se emplea para especificar las filas que se desean recuperar del
origen de datos.
WHERE <condicion_bsqueda>
<condicion_bsqueda> ::=
{ [NOT]<predicado>
|(<condicion_bsqueda>)
}
[{AND|OR} [NOT] {<predicado>|(<condicion_bsqueda>)}]
[ ...n ]
En el resultado de la consulta slo aparecern las filas que cumplan que la condicin de
bsqueda sea TRUE, los valores NULL no se incluyen, por lo tanto, en las filas del
resultado. La condicin de bsqueda puede ser una condicin simple o una condicin
compuesta por varias condiciones (predicados) unidas por operadores AND y OR, no hay
lmite en cuanto al nmero de predicados que se pueden incluir. En las condiciones
compuestas se pueden utilizar parntesis para delimitar predicados y se aconseja su uso
cuando se incluyen operadores AND y OR en la misma condicin de bsqueda.
3.14. Predicados
En SQL tenemos 7 tipos de predicados, condiciones bsicas de bsqueda:
Comparacin estndar
Pertenencia a un intervalo (BETWEEN)
Pertenencia a un conjunto (IN)
Test de valor nulo (IS NULL).
Coincidencia con patrn (LIKE)
Si contiene (CONTAINS)
64
FREETEXT
Comparacin estndar.
Compara el valor de una expresin con el valor de otra. Para la comparacin se pueden
emplear = , <> , !=, < , <= , !<, > , >= ,!>
Sintaxis:
<expresion> {=|<>|!=|>|>=|!>|<|<=|!<} <expresion>
<expresion>Puede ser:
Un nombre de columna,
una constante,
una funcin (inclusive la funcin CASE),
una variable,
una subconsulta escalar o
cualquier combinacin de nombres de columna, constantes y funciones conectados
mediante uno o varios operadores o una subconsulta.
Ejemplo:
Listar los "buenos" vendedores (los que han rebasado su cuota).
SELECT numemp, nombre, ventas, cuota
FROM empleados
WHERE ventas > cuota
numemp nombre ventas cuota
101 Antonio Viguer 30500,00 30000,00
102 Alvaro Jaumes 47400,00 35000,00
103 Juan Rovira 28600,00 27500,00
105 Vicente Pantalla 36800,00 35000,00
106 Luis Antonio 29900,00 27500,00
108 Ana Bustamante 36100,00 35000,00
109 Mara Sunta 39200,00 3000,00
Las columnas que aparecen en el WHERE no tienen por qu aparecer en la lista de
seleccin, esta instruccin es igual de vlida:
65
SELECT numemp, nombre FROM empleados
WHERE ventas > cuota;
Hallar vendedores contratados antes de 1988.
SELECT numemp, nombre, contrato FROM empleados
WHERE contrato < '01/01/1988';
numemp nombre contrato
101 Antonio Viguer 1986-10-20
102 Alvaro Jaumes 1986-12-10
103 Juan Rovira 1987-03-01
104 Jos Gonzlez 1987-05-19
Tambin podemos utilizar funciones, sta es equivalente a la anterior:
SELECT numemp, nombre
FROM empleados
WHERE YEAR(contrato) < 1988;
La funcin YEAR(fecha) devuelve el ao de una fecha.
Hallar oficinas cuyas ventas estn por debajo del 80% de su objetivo:
SELECT oficina
FROM oficinas
WHERE ventas < (.8 * objetivo);
Hallar las oficinas dirigidas por el empleado 108:
SELECT oficina
FROM oficinas
WHERE dir = 108;
66
Unidad 3. Consultas simples (XII)
Pertenencia a un intervalo. BETWEEN
<expresion> [NOT] BETWEEN <expresion2> AND <expresion3>
Examina si el valor de la expresin de test est en el rango delimitado por los valores
resultantes de expresion1 y expresion2, estos valores no tienen por qu estar ordenados
en ANSI/ISO; expresion1 debe ser menor o igual a expresion2.
Hallar vendedores cuyas ventas estn entre 20.000 euros y 50.000.
SELECT numemp, nombre, ventas FROM empleados
WHERE ventas BETWEEN 20000 AND 100000;
numemp nombre ventas
101 Antonio Viguer 30500,00
102 Alvaro Jaumes 47400,00
103 Juan Rovira 28600,00
105 Vicente Pantalla 36800,00
106 Luis Antonio 29900,00
108 Ana Bustamante 36100,00
109 Mara Sunta 39200,00
La instruccin anterior es equivalente a:
SELECT numemp, nombre, ventas
FROM empleados
WHERE ventas >= 20000 AND ventas <=100000;
Parece que con BETWEEN se lee mejor.
Observa que no hemos utilizado separadores de millares (100.000), porque se habra
interpretado por una coma decimal.
Para practicar puedes realizar este Ejercicio Intervalos con BETWEEN.
Test de pertenencia a conjunto IN
<expresion> IN ( <exp_valor> [ ,...n ] )
67
Examina si el valor de la expresion es uno de los valores incluidos en la lista de valores
indicados entre parntesis. Se pueden expresar los valores mediante cualquier expresin,
la nica condicin es que todas las exp_valor devuelvan el mismo tipo de datos.
Ejemplo:
Obtener los empleados que trabajan en las oficinas 11, 20 o 22:
SELECT oficina, numemp, nombre
FROM empleados
WHERE oficina IN (11,20,22);
oficina numemp nombre
11 106 Luis Antonio
22 107 Jorge Gutirrez
11 109 Mara Sunta
Para practicar puedes realizar este Ejercicio Pertenencia a un conjunto con IN.
Test de valor nulo IS NULL
<expression> IS [NOT] NULL
Una condicin de bsqueda puede ser TRUE, FALSE o NULL/UNKNOW, este ltimo
caso se produce cuando algn campo que interviene en la condicin tiene valor NULL.
A veces es til comprobar explcitamente los valores NULL en una condicin de bsqueda
ya que estas filas puede que queramos darles un tratamiento especial, para ello tenemos
el predicado IS NULL.
Este test produce un valor TRUE o FALSE, por lo que se podr combinar con otras
condiciones. El valor NULL no es en s un valor por eso no lo podemos utilizar en una
igualdad.
SELECT numemp,nombre FROM empleados
WHERE oficina = NULL;
Esta instruccin no da error pero no obtiene lo que en principio parece que quiere
obtener. No obtenemos los empleados cuya oficina sea un valor nulo (es decir los
empleados que no tienen oficina), no obtenemos nada, en cambio los obtendremos
utilizando el test de valor nulo:
SELECT numemp,nombre, oficina FROM empleados
WHERE oficina IS NULL;
Resultado:
68
numemp nombre oficina
110 Juan Victor NULL
Juan Victor es el nico empleado que no tiene oficina asignada.
Listar los vendedores asignados a alguna oficina.
SELECT numemp, nombre, oficina FROM empleados
WHERE oficina IS NOT NULL;
numemp nombre oficina
101 Antonio Viguer 12
102 Alvaro Jaumes 21
103 Juan Rovira 12
104 Jos Gonzlez 12
105 Vicente Pantalla 13
106 Luis Antonio 11
107 Jorge Gutirrez 22
108 Ana Bustamante 21
109 Mara Sunta 11
Unidad 3. Consultas simples (XIII)
Test de correspondencia con patrn LIKE
Se utiliza cuando queremos comparar el valor de una columna con un patrn en el que
se utilice caracteres comodines.
<expression> [NOT] LIKE <patron> [ESCAPE 'car_escape']
Con expresin indicamos el valor a comparar (normalmente ser el nombre de una
columna) y patrn es la cadena que se busca. El patrn es de tipo texto y tiene que
escribirse entre comillas simples. Dentro del patrn podemos utilizar los siguientes
comodines:
% representa cualquier cadena de cero o ms caracteres.
69
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE An%;
numemp nombre
101 Antonio Viguer
108 Ana Bustamante
Obtiene todos los nombres que empiecen por An.
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE %z;
numemp nombre
104 Jos Gonzlez
107 Jos Gonzlez
Obtiene los nombres que acaban en z.
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE %on%;
numemp nombre
101 Antonio Viguer
104 Jos Gonzlez
106 Luis Antonio
Obtiene los nombres que contienen on.
_ representa cualquier carcter (slo uno).
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE '__a%';
70
numemp nombre
103 Juan Rovira
108 Ana Bustamante
110 Juan Victor
Obtiene los nombres cuya tercera letra sea una a (en el patrn tenemos dos caracteres
subrayado).
[ ] sirve para indicar un carcter cualquiera perteneciente al conjunto indicando.
El conjunto se indica enumerando los caracteres o indicando un intervalo.
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE '[a-d]%';
Obtiene los nombres que empiezan por cualquier letra de la a a la d.
Es equivalente a escribir:
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE '[abcd]%';
[^] significa cualquier carcter individual que no se encuentre en el conjunto.
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE '[^abcd]%';
Y
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE '[^a-d]%';
Obtienen los nombres que no empiecen por a, b, c ni d.
Es importante tener en cuenta que dentro del patrn el espacio en blanco es
considerado como un carcter ms, si colocamos dos espacios en el patrn, se buscarn
dos espacios en el campo.
Si queremos incluir en el patrn uno de los caracteres comodines y que no sea
interpretado como un comodn, sino como un carcter normal, lo tenemos que encerrar
entre corchetes o utilizar un carcter de escape.
71
[ESCAPE 'car_escape']
La clusula ESCAPE es opcional y permite definir un carcter de escape.
Un carcter de escape es un carcter que se coloca delante de un carcter comodn
para indicar que el comodn no debe interpretarse como tal, sino como un carcter normal.
Por ejemplo queremos buscar los nombres compuestos que incluyen un subrayado. En
este caso tenemos que poner el carcter _ como un carcter normal no como un comodn,
as que lo escribiremos as:
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE '%[_]%';
O bien,
SELECT numemp,nombre
FROM empleados
WHERE nombre LIKE '%!_%' ESCAPE '!';
Unidad 3. Consultas simples (XIV)
3.15. Condiciones de bsqueda compuestas
En una clusula WHERE podemos incluir una condicin de bsqueda simple (formada
por un solo predicado) o compuesta (formada por la combinacin de predicados unidos
por los operadores lgicos NOT, AND, OR).
Cuando la condicin incluye varios operadores lgicos, el orden de prioridad de estos
operadores es:
NOT (el ms alto),
seguido de AND y OR (estos dos al mismo nivel).
Como siempre, se pueden utilizar parntesis para alterar esta prioridad en una
condicin de bsqueda.
El orden de evaluacin de los operadores lgicos puede variar dependiendo de las
opciones elegidas por el optimizador de consultas.
Los operadores lgicos pueden devolver tres valores distintos: TRUE, FALSE, NULL
(UNKNOWN).
Tablas de verdad de los operadores:
AND Combina dos condiciones y se evala como TRUE cuando ambas condiciones
son TRUE.
AND TRUE FALSE NULL
72
TRUE TRUE FALSE NULL
FALSE FALSE FALSE FALSE
NULL NULL FALSE NULL
OR Combina dos condiciones y se evala como TRUE cuando alguna de las
condiciones es TRUE.
OR TRUE FALSE NULL
TRUE TRUE TRUE TRUE
FALSE TRUE FALSE NULL
NULL TRUE NULL NULL
NOT Niega la expresin booleana que especifica el predicado
NOT TRUE FALSE NULL
FALSE TRUE NULL
Hallar los vendedores que estn por debajo de su cuota y tienen ventas inferiores a
30.000.
SELECT nombre
FROM empleados
WHERE ventas < cuota AND ventas < 30000;
Hallar los vendedores que estn debajo de su cuota, pero cuyas ventas no sean
inferiores a 150.000.
SELECT nombre
FROM empleados
WHERE ventas < cuota AND ventas < 150000;
Hallar las oficinas no dirigidas por el empleado 108
SELECT oficina
FROM oficinas
WHERE NOT dir = 108;
O
73
SELECT oficina
FROM oficinas
WHERE dir <> 108;
Devuelven:
oficina
11
12
13
Las oficinas sin director no aparecen, para que aparezcan deben aadir otro predicado:
SELECT oficina, dir
FROM oficinas
WHERE NOT dir = 108 or dir is null;
oficina dir
11 106
12 104
13 105
26 NULL
28 NULL
Unidad 4. Consultas multitabla (I)
4.1. Introduccin
Hasta ahora hemos visto consultas que obtienen los datos de una sola tabla, en este
tema veremos cmo obtener datos de diferentes tablas.
En esta parte ampliaremos la clusula FROM y descubriremos nuevas palabras
reservadas (UNION, EXCEPT e INTERSECT) que corresponden a operaciones
relacionales.
Para obtener datos de varias tablas tenemos que combinar estas tablas mediante
alguna operacin basada en el lgebra relacional.
74
El lgebra relacional define una serie de operaciones cuyos operandos son tablas y
cuyo resultado es tambin una tabla.
Las operaciones de lgebra relacional implementadas en Transact-Sql son:
La unin UNION
La diferencia EXCEPT
La interseccin INTERSECT
El producto cartesiano CROSS JOIN
La composicin interna INNER JOIN
La composicin externa LEFT JOIN, RIGHT JOIN Y FULL JOIN
En todo el tema cuando hablemos de tablas nos referiremos tanto a las tablas que
fsicamente estn almacenadas en la base de datos como a las tablas temporales y a las
resultantes de una consulta o vista.
4.2. La unin de tablas UNION
La unin de tablas consiste en coger dos tablas y obtener una tabla con las filas de las
dos tablas, en el resultado aparecern las filas de una tabla y, a continuacin, las filas de
la otra tabla.
Para poder realizar la operacin, las dos tablas tienen que tener el mismo esquema
(mismo nmero de columnas y tipos compatibles) y la tabla resultante hereda los
encabezados de la primera tabla.
La sintaxis es la siguiente:
{< consulta >|(< consulta >)}
UNION [ALL]
{< consulta >|(< consulta >)}
[{UNION [ALL] {< consulta >|(< consulta >)}}[ ...n ] ]
[ORDER BY {expression_columna|posicion_columna [ASC|DESC]}
[ ,...n ]]
< consulta > representa la especificacin de la consulta que nos devolver la tabla a
combinar.
Puede ser cualquier especificacin de consulta con la limitacin de que no admite la
clusula ORDER BY, los alias de campo se pueden definir pero slo tienen efecto cuando
se indican en la primera consulta ya que el resultado toma los nombres de columna de
esta.
Ejemplo: Suponemos que tenemos una tabla Valencia con las nuevas oficinas de
Valencia y otra tabla Madrid con las nuevas oficinas de Madrid y queremos obtener una
tabla con las nuevas oficinas de las dos ciudades:
SELECT oficina as OFI, ciudad FROM Valencia
UNION ALL
SELECT oficina, ciudad FROM Madrid;
75
El resultado sera:
OFI ciudad
11 Valencia
28 Valencia
23 Madrid
El resultado coge los nombres de columna de la primera consulta y aparecen primero
las filas de la primera consulta y despus las de la segunda.
Si queremos que el resultado aparezca ordenado podemos incluir la clusula ORDER
BY, pero despus de la ltima especificacin de consulta, y expresion_columna ser
cualquier columna vlida de la primera consulta.
SELECT oficina as OFI, ciudad FROM Valencia
UNION
SELECT oficina, ciudad FROM Madrid
ORDER BY ofi;
OFI ciudad
11 Valencia
23 Madrid
28 Valencia
Ahora las filas aparecen ordenadas por el nmero de oficina y hemos utilizado el
nombre de columna de la primera consulta.
Cuando aparezcan en el resultado varias filas iguales, el sistema por defecto elimina las
repeticiones.
Si se especifica ALL, el sistema devuelve todas las filas resultante de la unin incluidas las
repetidas
El empleo de ALL tambin hace que la consulta se ejecute ms rpidamente ya que el
sistema no tiene que eliminar las repeticiones.
Se pueden combinar varias tablas con el operador UNION. Por ejemplo supongamos
que tenemos otra tabla Pamplona con las oficinas nuevas de Pamplona:
SELECT oficina, ciudad FROM Valencia
UNION
SELECT oficina, ciudad FROM Madrid
UNION
SELECT oficina, ciudad FROM Pamplona;
76
Combinamos las tres tablas.
Otro ejemplo:
Obtener todos los productos cuyo precio exceda de 20 o que se haya vendido ms de
300 euros del producto en algn pedido.
SELECT idfab, idproducto
FROM productos
WHERE precio > 20
UNION
SELECT fab, producto
FROM pedidos
WHERE importe > 300;
Unidad 4. Consultas multitabla (II)
4.3. La diferencia EXCEPT
Aparecen en la tabla resultante las filas de la primera consulta que no aparecen en la
segunda.
Las condiciones son las mismas que las de la unin.
{<consulta>|(<consulta>)}
EXCEPT
{<consulta>|(<consulta>)}
[{EXCEPT {<consulta>|(<consulta>)}}[ ...n ] ]
[ORDER BY {expression_columna|posicion_columna [ASC|DESC]}
[ ,...n ]]
Por ejemplo tenemos las tablas T1 y T2.
T1 T2
Cod
1
2
4
5
6
Codigo
2
3
4
5
77
SELECT cod FROM T1
EXCEPT
SELECT codigo FROM T2;
Devuelve:
Cod
1
6
Ejemplo:
Listar los productos que no aparezcan en ningn pedido.
SELECT idfab, idproducto
FROM productos
EXCEPT
SELECT DISTINCT fab, producto
FROM pedidos;
Para practicar puedes realizar este Ejercicio La diferencia EXCEPT.
4.4. La interseccin INTERSECT
Tiene una sintaxis parecida a las anteriores pero en el resultado de la interseccin
aparecen las filas que estn simultneamente en las dos consultas.
Las condiciones son las mismas que las de la unin.
{ <consulta>|(<consulta>)}
INTERSECT
{<especificacion_consulta>|(<especificacion_consulta>)}
[{INTERSECT {<consulta>|(<consulta>)}} [ ...n ] ]
[ORDER BY {expression_columna|posicion_columna [ASC|DESC]}
[ ,...n ]]
Retomando el ejemplo anterior:
SELECT cod FROM T1
INTERSECT
SELECT cod FROM T2;
Devuelve:
78
Cod
2
4
5
Ejemplo: Obtener todos los productos que valen ms de 20 euros y que adems se
haya vendido en un pedido ms de 300 euros de ese producto.
SELECT idfab, idproducto
FROM productos
WHERE precio > 20
INTERSECT
SELECT fab, producto
FROM pedidos
WHERE importe > 300;
Unidad 4. Consultas multitabla (III)
4.5. La composicin de tablas
Hasta ahora hemos operado con tablas que tenan el mismo esquema, pero muchas
veces lo que necesitamos es obtener una tabla que tenga en una misma fila datos de
varias tablas, por ejemplo, obtener las facturas y que en la misma fila de factura aparezca
el nombre y direccin del cliente. Pues en lo que queda del tema estudiaremos este tipo
de consultas basadas en la composicin de tablas. La composicin de tablas consiste en
obtener a partir de dos tablas cualesquiera una nueva tabla fusionando las filas de una
con las filas de la otra, concatenando los esquemas de ambas tablas. Consiste en formar
parejas de filas.
La sentencia SELECT permite realizar esta composicin, incluyendo dos o ms tablas
en la clusula FROM.
Es hora de ampliar la clusula FROM que vimos en el tema anterior.
Empezaremos por estudiar la operacin a partir de la cual estn definidas las dems
operaciones de composicin de tabla, el producto cartesiano.
4.6. El producto cartesiano CROSS JOIN
El producto cartesiano obtiene todas las posibles concatenaciones de filas de la primera
tabla con filas de la segunda tabla.
Se indica escribiendo en la clusula FROM los nombres de las tablas separados por una
coma o utilizando el operador CROSS JOIN.
FROM {<tabla_origen>} [ ,...n ]
79
|<tabla_origen> CROSS JOIN <tabla_origen>
Tabla_origen puede ser un nombre de tabla o de vista o una tabla derivada (resultado
de una SELECT), en este ltimo caso la SELECT tiene que aparecer entre parntesis y la
tabla derivada debe llevar asociado obligatoriamente un alias de tabla. Tambin puede ser
una composicin de tablas.
Se pueden utilizar hasta 256 orgenes de tabla en una instruccin, aunque el lmite vara
en funcin de la memoria disponible y de la complejidad del resto de las expresiones de la
consulta. Tambin se puede especificar una variable table como un origen de tabla.
Ejemplo:
SELECT *
FROM empleados, oficinas;
Si ejecutamos esta consulta veremos que las filas del resultado estn formadas por las
columnas de empleados y las columnas de oficinas. En las filas aparece cada empleado
combinado con la primera oficina, luego los mismos empleados combinados con la
segunda oficina y as hasta combinar todos los empleados con todas las oficinas.
Si ejecutamos:
SELECT *
FROM empleados CROSS JOIN oficinas;
Obtenemos lo mismo.
Este tipo de operacin no es la que se utiliza ms a menudo, lo ms frecuente sera
combinar cada empleado con los datos de SU oficina. Lo podramos obtener aadiendo a
la consulta un WHERE para filtrar los registros correctos:
SELECT *
FROM empleados, oficinas
WHERE empleados.oficina=oficinas.oficina;
Aqu nos ha aparecido la necesidad de cualificar los campos ya que el nombre oficina
es un campo de empleados y de oficinas por lo que si no lo cualificamos, el sistema nos
da error.
Hemos utilizado en la lista de seleccin *, esto nos recupera todas las columnas de las
dos tablas.
SELECT empleados.*,ciudad, region
FROM empleados, oficinas
WHERE empleados.oficina=oficinas.oficina;
Recupera todas las columnas de empleados y las columnas ciudad y regin de oficinas.
Tambin podemos combinar una tabla consigo misma, pero en este caso hay que
definir un alias de tabla, en al menos una, sino el sistema da error ya que no puede
nombrar los campos.
80
SELECT *
FROM oficinas, oficinas as ofi2;
No insistiremos ms sobre el producto cartesiano porque no es la operacin ms
utilizada, ya que normalmente cuando queramos componer dos tablas lo haremos con una
condicin de seleccin basada en campos de combinacin y para este caso es ms
eficiente el JOIN que veremos a continuacin.
Unidad 4. Consultas multitabla (IV)
4.7. La composicin interna INNER JOIN
Una composicin interna es aquella en la que los valores de las columnas que se estn
combinando se comparan mediante un operador de comparacin.
Es otra forma, mejor, de expresar un producto cartesiano con una condicin.
Es la operacin que ms emplearemos ya que lo ms frecuente es querer juntar los
registros de una tabla relacionada con los registros correspondientes en la tabla de
referencia (aadir a cada factura los datos de su cliente, aadir a cada lnea de pedido los
datos de su producto, etc..,).
FROM
<tabla_origen> INNER JOIN <tabla_origen> ON <condicion_combi>
tabla_origen tiene el mismo significado que en el producto cartesiano.
condicion_combi es cualquier condicin que permite seleccionar las parejas de filas que
aparecen en el resultado. Normalmente ser una condicin de igualdad.
SELECT *
FROM empleados INNER JOIN oficinas
ON empleados.oficina=oficinas.oficina;
Obtiene los empleados combinados con los datos de su oficina.
SELECT *
FROM pedidos INNER JOIN productos
ON producto = idproducto AND fab = idfab;
Obtiene los pedidos combinados con los productos correspondientes.
Normalmente la condicin de combinacin ser una igualdad pero se puede utilizar
cualquier operador de comparacin (<>, >).
Es fcil ver la utilidad de esta instruccin y de hecho se utilizar muy a menudo, pero
hay algn caso que no resuelve. En las consultas anteriores, no aparecen las filas que no
tienen fila correspondiente en la otra tabla.
SELECT numemp,nombre,empleados.oficina, ciudad
81
FROM empleados INNER JOIN oficinas
ON empleados.oficina=oficinas.oficina;
numemp nombre oficina ciudad
101 Antonio Viguer 12 Alicante
102 Alvaro Jaumes 21 Badajoz
103 Juan Rovira 12 Alicante
104 Jos Gonzlez 12 Alicante
105 Vicente Pantalla 13 Castelln
106 Luis Antonio 11 Valencia
107 Jorge Gutirrez 22 A Corua
108 Ana Bustamante 21 Badajoz
109 Mara Sunta 11 Valencia
No aparecen los empleados que no tienen oficina, ni las oficinas que no tienen
empleados, porque para que salga la fila, debe de existir una fila de la otra tabla que
cumpla la condicin.
Para resolver este problema debemos utilizar otro tipo de composicin, la composicin
externa.
Para practicar puedes realizar este Ejercicio La composicin interna INNER JOIN.
Unidad 4. Consultas multitabla (V)
4.8. La Composicin externa LEFT, RIGHT y FULL OUTER JOIN
La composicin externa se escribe de manera similar al INNER JOIN indicando una
condicin de combinacin pero en el resultado se aaden filas que no cumplen la
condicin de combinacin.
Sintaxis
FROM
<tabla_origen> {LEFT|RIGHT|FULL} [OUTER] JOIN <tabla_origen>
ON <condicion_combi>
82
La palabra OUTER es opcional y no aade ninguna funcin.
Las palabras LEFT, RIGHT y FULL indican la tabla de la cual se van a aadir las filas sin
correspondencia.
SELECT numemp,nombre,empleados.oficina, ciudad
FROM empleados LEFT JOIN oficinas
ON empleados.oficina=oficinas.oficina;
numemp nombre oficina ciudad
101 Antonio Viguer 12 Alicante
102 Alvaro Jaumes 21 Badajoz
103 Juan Rovira 12 Alicante
104 Jos Gonzlez 12 Alicante
105 Vicente Pantalla 13 Castelln
106 Luis Antonio 11 Valencia
107 Jorge Gutirrez 22 A Corua
108 Ana Bustamante 21 Badajoz
109 Mara Sunta 11 Valencia
110 Juan Victor NULL NULL
Ahora s aparece el empleado 110 que no tiene oficina
Obtiene los empleados con su oficina y los empleados (tabla a la izquierda LEFT del
JOIN) que no tienen oficina aparecern tambin en el resultado con los campos de la tabla
oficinas rellenados a NULL.
SELECT numemp,nombre,empleados.oficina, ciudad, oficinas.oficina
FROM empleados RIGHT JOIN oficinas
ON empleados.oficina=oficinas.oficina;
numemp nombre oficina ciudad oficina
106 Luis Antonio 11 Valencia 11
109 Mara Sunta 11 Valencia 11
101 Antonio Viguer 12 Alicante 12
83
103 Juan Rovira 12 Alicante 12
104 Jos Gonzlez 12 Alicante 12
105 Vicente Pantalla 13 Castelln 13
102 Alvaro Jaumes 21 Badajoz 21
108 Ana Bustamante 21 Badajoz 21
107 Jorge Gutirrez 22 A Corua 22
NULL NULL NULL Madrid 23
NULL NULL NULL Aranjuez 24
NULL NULL NULL Pamplona 26
NULL NULL NULL Valencia 28
Las oficinas 23,24,26 y 28 no tienen empleados.
Obtiene los empleados con su oficina y las oficinas (tabla a la derecha RIGHT del JOIN)
que no tienen empleados aparecern tambin en el resultado con los campos de la tabla
empleados rellenados a NULL.
SELECT numemp,nombre,empleados.oficina, ciudad, oficinas.oficina
FROM empleados FULL JOIN oficinas
ON empleados.oficina=oficinas.oficina;
numemp nombre oficina ciudad oficina
101 Antonio Viguer 12 Alicante 12
102 Alvaro Jaumes 21 Badajoz 21
103 Juan Rovira 12 Alicante 12
104 Jos Gonzlez 12 Alicante 12
105 Vicente Pantalla 13 Castelln 13
106 Luis Antonio 11 Valencia 11
107 Jorge Gutirrez 22 A Corua 22
108 Ana Bustamante 21 Badajoz 21
84
109 Mara Sunta 11 Valencia 11
110 Juan Victor NULL NULL NULL
NULL NULL NULL Madrid 23
NULL NULL NULL Aranjuez 24
NULL NULL NULL Pamplona 26
NULL NULL NULL Valencia 28
Aparecen tanto los empleados sin oficina como las oficinas sin empleados.
SELECT numemp,nombre,empleados.oficina, ciudad, oficinas.oficina
FROM empleados FULL OUTER JOIN oficinas
ON empleados.oficina=oficinas.oficina;
Es equivalente, la palabra OUTER como hemos dicho no aade ninguna funcionalidad
y se utiliza si se quiere por cuestiones de estilo.
NOTA: Cuando necesitamos obtener filas con datos de dos tablas con una condicin de
combinacin utilizaremos un JOIN, os aconsejo empezar por escribir el JOIN con la
condicin que sea necesaria para combinar las filas, y luego plantearos si la composicin
debe de ser interna o externa. Para este segundo paso sta sera la norma a seguir:
Empezamos con INNER JOIN.
Si pueden haber filas de la primera tabla que no estn relacionadas con filas de la
segunda tabla y nos interesa que salgan en el resultado, entonces cambiamos a
LEFT JOIN.
Si pueden haber filas de la segunda tabla que no estn relacionadas con filas de la
primera tabla y nos interesa que salgan en el resultado, entonces cambiamos a
RIGHT JOIN.
Si necesitamos LEFT y RIGHT entonces utilizamos FULL JOIN.
Siguiendo el ejemplo anterior nos preguntaramos:
Pueden haber empleados que no tengan oficina y nos interesan?, si es que s,
necesitamos un LEFT JOIN.
Seguiramos preguntando:
Pueden haber oficinas que no tengan empleados y nos interesan?, si es que s,
necesitamos un RIGHT JOIN.
Si al final necesitamos LEFT y tambin RIGHT entonces utilizamos FULL JOIN.
85
Unidad 4. Consultas multitabla (VI)
4.9. Combinar varias operaciones
En las operaciones anteriores tabla_origen puede ser a su vez una composicin de
tablas, en este caso aunque slo sea obligatorio cuando queramos cambiar el orden de
ejecucin de las composiciones, es recomendable utilizar parntesis para delimitar las
composiciones.
Por ejemplo:
SELECT numemp, nombre, empleados.oficina, ciudad, oficinas.oficina,
pedidos.*
FROM (oficinas RIGHT JOIN empleados
ON empleados.oficina = oficinas.oficina)
INNER JOIN pedidos on rep=numemp;
O bien:
SELECT numemp, nombre, empleados.oficina, ciudad, oficinas.oficina,
pedidos.*
FROM oficinas RIGHT JOIN (empleados INNER JOIN pedidos on rep =
numemp)
ON empleados.oficina = oficinas.oficina);
Unidad 5. Consultas de resumen (I)
5.1. Introduccin
Una de las funcionalidades de la sentencia SELECT es el permitir obtener resmenes
de los datos contenidos en las columnas de las tablas.
Para poder llevarlo a cabo la sentencia SELECT consta de una serie de clusulas
especficas (GROUP BY, HAVING), y Transact-SQL tiene definidas unas funciones para
poder realizar estos clculos, las funciones de agregado (tambin llamadas funciones de
columna).
La diferencia entre una consulta de resumen y una consulta de las que hemos visto hasta
ahora es que en las consultas normales las filas del resultado se obtienen directamente de
las filas del origen de datos y cada dato que aparece en el resultado tiene su dato
correspondiente en el origen de la consulta mientras que las filas generadas por las
consultas de resumen no representan datos del origen sino un total calculado sobre estos
datos. Esta diferencia har que las consultas de resumen tengan algunas limitaciones que
veremos a lo largo del tema.
Un ejemplo sera:
86
A la izquierda tenemos una consulta simple que nos saca las oficinas con sus ventas
ordenadas por regin, y a la derecha una consulta de resumen que obtiene la suma de las
ventas de las oficinas de cada regin
5.2. Las funciones de agregado
Una funcin de agregado SQL acepta un grupo de datos (normalmente una columna de
datos) como argumento, y produce un nico dato que resume el grupo. Por ejemplo la
funcin AVG() acepta una columna de datos numricos y devuelve la media aritmtica
(average) de los valores contenidos en la columna.
El mero hecho de utilizar una funcin de agregado en una consulta, convierte sta en una
consulta de resumen.
Todas las funciones de agregado tienen una estructura muy parecida:
Funcin ([ALL|DISTINCT] expression)
El grupo de valores sobre el que acta la funcin lo determina el resultado de la
expresin que ser un nombre de columna o una expresin basada en una columna o
varias del origen de datos. En la expresin nunca puede aparecer una funcin de
agregado ni una subconsulta.
La palabra ALL indica que se tiene que tomar en cuenta todos los valores de la
columna. Es el valor por defecto.
La palabra DISTINCT hace que se consideren todas las repeticiones del mismo valor
como uno slo (considera valores distintos).
Todas las funciones de agregado se aplican a las filas del origen de datos una vez
ejecutada la clusula WHERE (si la hubiera).
Si exceptuamos la funcin COUNT, todas las funciones de agregado ignoran los
valores NULL.
87
Una funcin de agregado puede aparecer en la lista de seleccin en cualquier lugar en
el que puede aparecer un nombre de columna. Puede, por ejemplo, formar parte de una
expresin pero no se pueden anidar funciones de agregado.
Tampoco se pueden mezclar funciones de columna con nombres de columna ordinarios.
Hay excepciones a esta regla pero cuando definimos agrupaciones y subconsultas que
veremos ms adelante.
Unidad 5. Consultas de resumen (II)
5.3. La funcin COUNT
COUNT ({[ALL|DISTINCT] expresion | * } )
Expresion puede ser de cualquier tipo excepto text, image o ntext. No se permite
utilizar funciones de agregado ni subconsultas. El tipo de dato devuelto es int.
Si el nmero de valores devueltos por expresion es superior a 231-1, COUNT genera un
error, en ese caso hay que utilizar la funcin COUNT_BIG.
La funcin cuenta los valores distintos de NULL que hay en la columna. La palabra ALL
indica que se tienen que tomar todos los valores de la columna, mientras que DISTINCT
hace que se consideren todas las repeticiones del mismo valor como uno solo. Estos
parmetros son opcionales, por defecto se considera ALL.
Por ejemplo:
SELECT COUNT(region) FROM oficinas;
Devuelve 9 porque tenemos nueve valores no nulos en la columna region. A la hora de
interpretar un COUNT es conveniente no olvidar que cuenta valores no nulos, por ejemplo
si interpretramos la sentencia tal cual se lee, cuntas regiones tenemos en
oficinas sera errneo, realmente estamos obteniendo cuntas oficinas tienen una regin
asignada.
SELECT COUNT(DISTINCT region) FROM oficinas;
Devuelve 4 porque tenemos cuatro valores distintos, no nulos, en la columna regin, los
valores repetidos los considera slo una vez. Ahora s nos devuelve cuntas regiones
tenemos en oficinas.
Si utilizamos * en vez de expresin, devuelve el nmero de filas del origen que nos
quedan despus de ejecutar la clusula WHERE.
COUNT(*) no acepta parmetros y no se puede utilizar con DISTINCT. COUNT(*) no
requiere un parmetro expression porque, por definicin, no utiliza informacin sobre
ninguna columna especfica. En el recuento se incluyen las filas que contienen valores
NULL.
SELECT COUNT(*) FROM empleados WHERE oficina=12;
Obtiene el nmero de empleados asignados a la oficina 12.
88
Si tenemos un COUNT(columna) y columna no contiene valores nulos, se obtiene el
mismo resultado que COUNT(*) pero el COUNT(*) es ms rpido por lo que en este caso
hay que utilizarlo en vez de COUNT(columna).
Por ejemplo:
SELECT COUNT(*) FROM empleados WHERE oficina IS NOT NULL;
Es mejor que:
SELECT COUNT(oficina) FROM empleados WHERE oficina IS NOT NULL;
Las dos nos devuelven el nmero de empleados que tienen una oficina asignada pero
la primera es mejor porque se calcula ms rpidamente.
Para practicar puedes realizar este Ejercicio La funcin COUNT.
5.4. La funcin COUNT_BIG
Funciona igual que la funcin COUNT. La nica diferencia entre ambas funciones est
en los valores devueltos, COUNT_BIG siempre devuelve un valor de tipo bigint y por lo
tanto admite ms valores de entrada, no est limitado a 231-1 valores de entrada como
COUNT.
5.5. La funcin MAX
MAX ([ALL|DISTINCT] expression)
Devuelve el valor mximo de la expresin sin considerar los nulos.
MAX se puede usar con columnas numricas, de caracteres y de datetime, pero no con
columnas de bit. No se permiten funciones de agregado ni subconsultas.
Utilizar DISTINCT no tiene ningn sentido con MAX (el valor mximo ser el mismo si
consideramos las repeticiones o no) y slo se incluye para la compatibilidad con SQL-92.
Por ejemplo:
SELECT SUM(ventas) AS VentasTotales, MAX(objetivo) AS
MayorObjetivo
FROM oficinas;
Devuelve 9 porque tenemos nueve valores no nulos en la columna region. A la hora de
interpretar un COUNT es conveniente no olvidar que cuenta valores no nulos, por ejemplo
si interpretramos la sentencia tal cual se lee, cuntas regiones tenemos en
oficinas sera errneo, realmente estamos obteniendo cuntas oficinas tienen una regin
asignada.
Para practicar puedes realizar este Ejercicio La funcin MAX.
5.6. La funcin MIN
MIN ([ALL|DISTINCT] expression)
89
Devuelve el valor mnimo de la expresin sin considerar los nulos.
MIN se puede usar con columnas numricas, de caracteres y de datetime, pero no con
columnas de bit. No se permiten funciones de agregado ni subconsultas.
Utilizar DISTINCT no tiene ningn sentido con MIN (el valor mnimo ser el mismo si
consideramos las repeticiones o no) y slo se incluye para la compatibilidad con SQL-92.
Unidad 5. Consultas de resumen (III)
5.7. La funcin SUM
SUM ([ALL|DISTINCT] expresion )
Devuelve la suma de los valores devueltos por la expresin.
Slo puede utilizarse con columnas numricas.
El resultado ser del mismo tipo aunque puede tener una precisin mayor.
SELECT SUM(importe) FROM pedidos;
Obtiene el importe total vendido en todos los pedidos.
SELECT SUM(ventas) AS VentasTotales, MAX(objetivo) AS
MayorObjetivo
FROM oficinas;
Devuelve la suma de las ventas de todas las oficinas y de los objetivos de todas las
oficinas, el de mayor importe.
Para practicar puedes realizar este Ejercicio La funcin SUM.
5.8. La funcin AVG
AVG ([ALL|DISTINCT] expresion )
Devuelve el promedio de los valores de un grupo, para calcular el promedio se omiten
los valores nulos.
El grupo de valores lo determina el resultado de la expresin que ser un nombre de
columna o una expresin basada en una columna o varias del origen de datos.
La funcin se aplica tambin a campos numricos, y en este caso el tipo de dato del
resultado puede cambiar segn las necesidades del sistema para representar el valor del
resultado.
Para practicar puedes realizar este Ejercicio La funcin AVG.
5.9. La funcin VAR
VAR ([ALL|DISTINCT] expresion )
90
Devuelve la varianza estadstica de todos los valores de la expresin especificada.
VAR slo se puede utilizar con columnas numricas. Los valores NULL se pasan por alto.
5.10. La funcin VARP
VARP ([ALL|DISTINCT] expresion )
Devuelve la varianza estadstica de la poblacin para todos los valores de la expresin
especificada.
Slo se puede utilizar con columnas numricas. Los valores NULL se pasan por alto.
5.11. La funcin STDEV
STDEV ([ALL|DISTINCT] expresion )
Devuelve la desviacin tpica estadstica de todos los valores de la expresin
especificada.
Slo se puede utilizar con columnas numricas. Los valores NULL se pasan por alto.
5.12. La funcin STDEVP
STDEVP ([ALL|DISTINCT] expresion )
Devuelve la desviacin estadstica estndar para la poblacin de todos los valores de la
expresin especificada.
Slo se puede utilizar con columnas numricas. Los valores NULL se pasan por alto.
5.13. La funcin GROUPING
GROUPING (nb_columna)
Es una funcin de agregado que genera como salida una columna adicional con el valor
1 si la fila se agrega mediante el operador CUBE o ROLLUP, o el valor 0 cuando la fila no
es el resultado de CUBE o ROLLUP.
Nb_columna tiene que ser una de las columnas de agrupacin y la clusula GROUP BY
debe contener el operador CUBE o ROLLUP.
En el siguiente punto, cuando veamos las clusulas CUBE y ROLLUP quedar ms
claro.
Unidad 5. Consultas de resumen (IV)
5.14. Agrupamiento de filas (clusula GROUP BY).
Hasta ahora las consultas sumarias que hemos visto obtienen totales de todas las filas
del origen y producen una nica fila de resultado.
Muchas veces cuando calculamos resmenes nos interesan totales parciales, por
ejemplo saber de cada empleado cunto ha vendido, y cul ha sido su pedido mximo, de
cada cliente cundo fue la ltima vez que nos compr, etc.
91
En todos estos casos en vez de obtener una fila nica de resultados necesitamos una
fila por cada empleado, cliente, etc.
Podemos obtener estos subtotales con la clusula GROUP BY.
GROUP BY [ ALL ] expresion_agrupacion [ ,...n ]
[ WITH { CUBE | ROLLUP } ]
Una consulta con una clusula GROUP BY agrupa los datos de la tabla origen y
produce una nica fila resultado por cada grupo formado. Las columnas indicadas en el
GROUP BY se llaman columnas de agrupacin o agrupamiento .
Cuando queremos realizar una agrupacin mltiple, por varias columnas, stas se
indican en la clusula GROUP BY en el orden de mayor a menor agrupacin igual que con
la clusula ORDER BY.
expresion_agrupacion puede ser una columna o una expresin no agregada que haga
referencia a una columna devuelta por la clusula FROM. Un alias de columna que est
definido en la lista de seleccin no puede utilizarse para especificar una columna de
agrupamiento.
No se pueden utilizar columnas de tipo text, ntext e image en expresion_agrupacion.
En las clusulas GROUP BY que no contengan CUBE o ROLLUP, el nmero de
columnas de agrupacin est limitado por los tamaos de columna de GROUP BY, las
columnas de agregado y los valores de agregado que participan en la consulta. Este lmite
procede del lmite de 8.060 bytes de la tabla de trabajo intermedia que se necesita para
contener los resultados intermedios de la consulta. Se permite un mximo de 10
expresiones de agrupamiento cuando se especifica CUBE o ROLLUP.
Si en la columna de agrupacin existen valores nulos, se generar una fila de resumen
para este valor, en este caso se considera el valor nulo como otro valor cualquiera.
Ejemplo:
SELECT oficina, count(numemp) AS [Nmero de empleados]
FROM empleados
GROUP BY oficina;
Resultado:
oficina Nmero de empleados
NULL 2
11 2
12 3
13 1
21 2
92
22 1
Hay empleados sin oficinas (con oficina a nulo), estos forman un grupo con el valor
NULL en oficina, en este caso hay dos empleados as.
Podemos indicar varias columnas de agrupacin.
Ejemplo:
SELECT rep, clie, count(numpedido) AS [Nmero de pedidos],
MAX(importe) AS [Importe mximo]
FROM pedidos
WHERE YEAR(fechapedido) = 1997
GROUP BY rep, clie
ORDER BY rep, clie;
Resultado:
rep clie
Nmero
de pedidos
Importe
mximo
101 2113 1 225,00
102 2106 2 21,30
102 2120 1 37,50
103 2111 2 21,00
105 2103 4 275,00
105 2111 1 37,45
106 2101 1 14,58
107 2109 1 313,50
107 2124 2 24,30
108 2112 1 29,25
108 2114 1 71,00
108 2118 3 14,20
De cada representante obtenemos el nmero de pedidos y el importe mximo vendido a
cada cliente, de las ventas de 1997. La clusula ORDER BY se ha incluido para que las
filas aparezcan ordenadas y quede ms claro.
93
Unidad 5. Consultas de resumen (V)
Hemos dicho que los resmenes se calculan sobre todas las filas del origen despus de
haber ejecutado el WHERE, pues ALL permite obtener un resumen de las filas que no
cumplen el WHERE.
ALL Incluye todos los grupos y conjuntos de resultados, incluso aquellos en los que no
hay filas que cumplan la condicin de bsqueda especificada en la clusula WHERE.
Cuando se especifica ALL, se devuelven valores NULL para las columnas de resumen de
los grupos que no cumplen la condicin de bsqueda. No se puede especificar ALL con
los operadores CUBE y ROLLUP.
GROUP BY ALL no se admite en consultas que tienen acceso a tablas remotas si
tambin hay una clusula WHERE en la consulta.
Por ejemplo, vamos a modificar la consulta anterior:
SELECT rep, clie, count(numpedido) AS [Nmero de pedidos],
MAX(importe) AS [Importe mximo]
FROM pedidos
WHERE YEAR(fechapedido) = 1997
GROUP BY ALL rep, clie
ORDER BY rep, clie;
Resultado:
rep clie
Nmero
de pedidos
Importe
mximo
101 2102 0 NULL
101 2108 0 NULL
101 2113 1 225,00
102 2106 2 21,30
102 2120 1 37,50
103 2111 2 21,00
105 2103 4 275,00
105 2111 1 37,45
106 2101 1 14,58
106 2117 0 NULL
94
107 2109 1 313,50
107 2124 2 24,30
108 2112 1 29,25
108 2114 1 71,00
108 2118 3 14,20
Cul ha sido el efecto de aadir ALL? Se han aadido filas para las filas del origen que
no cumplen la condicin del WHERE pero sin que intervengan en el clculo de las
funciones de agregado.
Por ejemplo el representante 101 tiene pedidos con el cliente 2102 pero estos pedidos
no son del ao 1997, por eso aparece la primera fila (no estaba en el resultado de la otra
consulta) pero con 0 y NULL como resultados de las funciones de agregado.
ROLLUP especifica que, adems de las filas que normalmente proporciona GROUP
BY, se incluyen filas de resumen en el conjunto de resultados. Los grupos se resumen en
un orden jerrquico, desde el nivel inferior del grupo hasta el superior. La jerarqua del
grupo se determina por el orden en que se especifican las columnas de agrupamiento.
Cambiar el orden de las columnas de agrupamiento puede afectar al nmero de filas
generadas en el conjunto de resultados.
Por ejemplo:
SELECT rep, clie, count(numpedido) AS [Nmero de pedidos],
MAX(importe) AS [Importe mximo]
FROM pedidos
WHERE YEAR(fechapedido) = 1997
GROUP BY rep, clie WITH ROLLUP;
Resultado:
rep clie
Nmero
de pedidos
Importe
mximo
101 2113 1 225,00
101 NULL 1 225,00
102 2106 1 21,30
102 2120 1 37,50
95
102 NULL 3 37,50
103 2111 2 21,00
103 NULL 2 21,00
105 2103 4 275,00
105 2111 1 37,45
105 NULL 5 275,00
106 2101 1 14,28
106 NULL 1 14,28
107 2109 1 313,50
107 2124 2 24,30
107 NULL 3 313,50
108 2112 1 29,25
108 2114 1 71,00
108 2118 3 14,20
108 NULL 5 71,00
... ... ... ...
NULL NULL 23 450,00
Efecto: Se han aadido automticamente subtotales por cada nivel de agrupamiento y
una lnea de totales generales al final. En este caso no hemos incluido ORDER BY porque
las filas salen ya ordenadas.
Unidad 5. Consultas de resumen (VI)
CUBE especifica que, adems de las filas que normalmente proporciona GROUP BY,
deben incluirse filas de resumen en el conjunto de resultados. Se devuelve una fila de
resumen GROUP BY por cada posible combinacin de grupo y subgrupo del conjunto de
resultados. En el resultado se muestra una fila de resumen GROUP BY como NULL, pero
se utiliza para indicar todos los valores.
Por ejemplo:
SELECT rep, clie, count(numpedido) AS [Nmero de pedidos],
MAX(importe) AS [Importe mximo]
96
FROM pedidos
WHERE YEAR(fechapedido) = 1997
GROUP BY rep, clie WITH CUBE;
Resultado:
rep clie
Nmero
de pedidos
Importe
mximo
101 2113 1 225,00
101 NULL 1 225,00
102 2106 1 21,30
102 2120 1 37,50
102 NULL 3 37,50
103 2111 2 21,00
103 NULL 2 21,00
105 2103 4 275,00
105 2111 1 37,45
105 NULL 5 275,00
106 2101 1 14,28
106 NULL 1 14,28
107 2109 1 313,50
107 2124 2 24,30
107 NULL 3 313,50
108 2112 1 29,25
108 2114 1 71,00
108 2118 3 14,20
108 NULL 5 71,00
... ... ... ...
97
NULL NULL 23 450,00
NULL 2101 1 14,58
NULL 2103 4 275,00
NULL 2106 2 21,30
NULL 2107 1 6,32
NULL 2108 1 56,25
NULL 2109 1 313,50
NULL 2111 3 37,45
NULL 2112 2 450,00
NULL 2113 1 225,00
NULL 2114 1 71,00
NULL 2118 3 14,20
NULL 2120 1 37,50
NULL 2124 2 24,30
Efecto: Obtenemos adems de los resultados obtenidos con ROLLUP (los totales por
cada representante), los totales por el otro criterio (los totales por cada cliente).
El nmero de filas de resumen del conjunto de resultados se determina mediante el
nmero de columnas que contiene la clusula GROUP BY. Cada operando (columna) de
la clusula GROUP BY se enlaza segn el agrupamiento NULL y se aplica el
agrupamiento al resto de los operandos (columnas). CUBE devuelve todas las
combinaciones posibles de grupo y subgrupo.
Tanto si utilizamos CUBE como ROLLUP, nos ser til la funcin de agregado
GROUPING.
Si cogemos por ejemplo la primera fila remarcada (101 NULL ) el valor NULL, no
sabemos si se refiere a una fila de subtotal o a que el representante 101 ha realizado un
pedido sin nmero de cliente. Para poder salvar este problema se utiliza la funcin de
agregado GROUPING.
SELECT rep, clie, count(numpedido) AS [Nmero de pedidos],
MAX(importe) AS [Importe mximo], GROUPING(clie) AS [Fila resumen]
FROM pedidos
WHERE YEAR(fechapedido) = 1997
GROUP BY rep, clie WITH ROLLUP;
98
rep clie
Nmero
de pedidos
Importe
mximo
Fila
Resumen
101 2113 1 225,00 0
101 NULL 1 225,00 1
102 2106 2 21,30 0
102 2120 1 37,50 0
102 NULL 3 37,50 1
103 2111 2 21,00 0
Las filas que corresponden a subtotales aparecen con un 1 y las normales con un cero.
Ahora que estamos ms familiarizados con las columnas de agrupamiento debemos
comentar una regla a no olvidar:
EN LA LISTA DE SELECCIN DE UNA CONSULTA DE RESUMEN UN NOMBRE DE
COLUMNA NO PUEDE APARECER FUERA DE UNA FUNCIN DE AGREGADO SI NO
ES UNA COLUMNA DE AGRUPACIN.
Unidad 5. Consultas de resumen (VII)
5.15. Seleccin sobre grupos de filas, la clusula HAVING
Cuando queremos incluir una clusula de seleccin sobre las filas del origen, utilizamos
la clusula WHERE, pero cuando estamos definiendo una consulta de resumen, no
podemos utilizar esta clusula para seleccionar filas del resultado ya que cada una de
stas representa un grupo de filas de la tabla original. Para seleccionar filas del resumen
tenemos la clusula HAVING.
HAVING condicin de bsqueda
HAVING funciona igual que la clusula WHERE pero en vez de actuar sobre las filas
del origen de datos, acta sobre las filas del resultado, selecciona grupos de filas por lo
que la condicin de bsqueda sufrir alguna limitacin, la misma que para la lista de
seleccin:
Ejemplo:
SELECT oficina, count(numemp) AS [Nmero de empleados]
FROM empleados
GROUP BY oficina
HAVING COUNT(numemp)<2;
Resultado:
99
oficina Nmero de empleados
13 1
22 1
Esta SELECT es la misma que la del primer ejemplo del apartado sobre la clusula
GROUP BY, la diferencia es que le hemos aadido la clusula HAVING, que hace que del
resultado slo se visualicen los grupos que cumplan la condicin. Es decir slo aparecen
las oficinas que tienen menos de 2 empleados.
Siempre que en una condicin de seleccin haya una funcin de columna, la condicin
deber incluirse en la clusula HAVING, adems, como HAVING filtra filas del resultado,
slo puede contener expresiones (nombres de columnas, expresiones, funciones) que
tambin pueden aparecer en la lista de seleccin, por lo que tambin se aplica la misma
regla a no olvidar:
EN LA CLUSULA HAVING UN NOMBRE DE COLUMNA NO PUEDE APARECER
FUERA DE UNA FUNCIN DE AGREGADO SI NO ES UNA COLUMNA DE
AGRUPACIN.
Las expresiones que pongamos en HAVING no tienen porqu aparecer en la lista de
seleccin, por ejemplo en la SELECT anterior se poda haber escrito:
HAVING SUM(ventas)=10000
Unidad 6. Las subconsultas (I)
6.1. Introduccin
Una subconsulta es una consulta que aparece dentro de otra consulta o subconsultas,
en la lista de seleccin o en la clusula WHERE o HAVING, originalmente no se podan
incluir en la lista de seleccin.
Una subconsulta se denomina tambin consulta o seleccin interna, mientras que la
instruccin que contiene la subconsulta es conocida como consulta o seleccin externa.
Aparece siempre encerrada entre parntesis y tiene la misma sintaxis que una
sentencia SELECT normal con alguna limitacin:
No puede incluir una clusula COMPUTE o FOR BROWSE y slo puede incluir una
clusula ORDER BY cuando se especifica tambin una clusula TOP.
Una subconsulta puede anidarse en la clusula WHERE o HAVING de una instruccin
externa SELECT, INSERT, UPDATE o DELETE, o bien en otra subconsulta. Se puede
disponer de hasta 32 niveles de anidamiento, aunque el lmite vara dependiendo de la
memoria disponible y de la complejidad del resto de las expresiones de la consulta. Hay
que tener en cuenta que para cada fila de la consulta externa, se calcula la subconsulta, si
anidamos varias consultas, el nmero de veces que se ejecutarn las subconsultas
puede dispararse!
Cuando la subconsulta aparece en la lista de seleccin de otra consulta, deber
devolver un solo valor, de lo contrario provocar un error.
100
Ejemplo de subconsulta: Listar los empleados cuya cuota no supere el importe vendido
por el empleado.
SELECT nombre
FROM empleados
WHERE cuota <= (SELECT SUM(importe)
FROM pedidos
WHERE rep = numemp);
Por cada fila de la tabla de empleados (de la consulta externa) se calcula la subconsulta
y se evala la condicin, por lo que utilizar una subconsulta puede en algunos casos
ralentizar la consulta, en contrapartida se necesita menos memoria que una composicin
de tablas.
Muchas de las instrucciones Transact-SQL que incluyen subconsultas se pueden
formular tambin utilizando composiciones de tablas. Otras preguntas se pueden formular
slo con subconsultas.
En Transact-SQL, normalmente no hay una regla fija en cuanto a diferencias de
rendimiento entre una instruccin que incluya una subconsulta y una versin
semnticamente equivalente que no la incluya.
Podremos utilizar una subconsulta siempre y cuando no se quiera que aparezcan en el
resultado columnas de la subconsulta ya que si una tabla aparece en la subconsulta y no
en la consulta externa, las columnas de esa tabla no se pueden incluir en la salida (la lista
de seleccin de la consulta externa).
Tenemos tres tipos de subconsultas:
Las que devuelven un solo valor, aparecen en la lista de seleccin de la consulta
externa o con un operador de comparacin sin modificar.
Las que generan una columna de valores, aparecen con el operador IN o con
un operador de comparacin modificado con ANY, SOME o ALL.
Las que pueden generar cualquier nmero de columnas y filas, son utilizadas en
pruebas de existencia especificadas con EXISTS.
A lo largo del tema las estudiaremos todas.
Antes de terminar con la introduccin queda comentar el concepto de referencia externa
muy til en las subconsultas.
A menudo, es necesario, dentro del cuerpo de una subconsulta, hacer referencia al
valor de una columna en la fila actual de la consulta externa, el nombre de columna de la
consulta externa dentro de la subconsulta recibe el nombre de referencia externa, ya que
hace referencia a una columna externa.
En el ejemplo anterior numemp es una referencia externa, no es una columna del
origen de datos de la subconsulta (pedidos), es una columna del origen de la consulta
externa (empleados).
Hay que tener en cuenta de cmo se ejecuta la consulta; por cada fila de la consulta
externa se calcula el resultado de la subconsulta y se evala la comparacin.
En el ejemplo, se coge el primer empleado (numemp= 101, por ejemplo) y se calcula la
subconsulta sustituyendo numemp por el valor 101, se calcula la suma de los pedidos del
101
rep = 101, y el resultado se compara con la cuota de ese empleado, y as se repite el
proceso con todas las filas de empleados.
El nombre de una columna dentro de la subconsulta se presupone del origen de datos
de la subconsulta y, slo si no se encuentra en ese origen, la considera como columna
externa y la busca en el origen de la consulta externa.
Por ejemplo:
SELECT oficina, ciudad
FROM oficinas
WHERE objetivo > (SELECT SUM(ventas)
FROM empleados
WHERE oficina = oficina);
La columna oficina se encuentra en los dos orgenes (oficinas y empleados) pero esta
consulta no dar error (no se nos pedir cualificar los nombres como pasara en una
composicin de tablas), dentro de la subconsulta se considera oficina el campo de la tabla
empleados. Con lo que comparara la oficina del empleado con la misma oficina del
empleado y eso no es lo que queremos, queremos comparar la oficina del empleado con
la oficina de oficinas, lo escribiremos pues as para forzar a que busque la columna en la
tabla oficinas.
SELECT oficina, ciudad
FROM oficinas
WHERE objetivo > (SELECT SUM(ventas)
FROM empleados
WHERE oficina = oficinas.oficina);
Unidad 6. Las subconsultas (II)
6.2. Subconsultas de resultado nico
Existen subconsultas que deben obligatoriamente devolver un nico valor, son las que
aparecen en la lista de seleccin de la consulta externa o las que aparecen en WHERE o
HAVING combinadas con un operador de comparacin sin modificar.
Los operadores de comparacin sin modificar son los operadores de comparacin que
vimos con la clusula WHERE.
Sintaxis:
<expresion> {=|<>|!=|>|>=|!>|<|<=|!<} <subconsulta>
En este caso la segunda expresin ser una subconsulta, con una sola columna en la
lista de seleccin y deber devolver una nica fila como mucho.
Ese valor nico ser el que se compare con el resultado de la primera expresin.
Si la subconsulta no devuelve ninguna fila, la comparacin opera como si la segunda
expresin fuese nula.
102
Si la subconsulta devuelve ms de una fila o ms de una columna, da error.
Ejemplo:
SELECT nombre
FROM empleados
WHERE cuota <= (SELECT SUM(importe)
FROM pedidos
WHERE rep = numemp);
La subconsulta devuelve una sola columna y como mucho una fila ya que es una
consulta de resumen sin clusula GROUP BY.
Para practicar puedes realizar este Ejercicio Subconsultas de resultado nico.
6.3. Subconsultas de lista de valores
Otro tipo de subconsultas son las que devuelven una lista de valores en forma de una
columna y cero, una o varias filas.
Estas consultas aparecen en las clusulas WHERE o HAVING combinadas con el
operador IN o con comparaciones modificadas.
6.4. El operador IN con subconsulta
<expresion> IN subconsulta
IN examina si el valor de expresion es uno de los valores incluidos en la lista de valores
generados por la subconsulta.
La subconsulta tiene que generar valores de un tipo compatible con la expresin.
Ejemplo:
SELECT *
FROM empleados
WHERE oficina IN (SELECT oficina
FROM oficinas
WHERE region = 'Este');
Por cada empleado se calcula la lista de las oficinas del Este (n de oficina) y se evala
si la oficina del empleado est en esta lista. Obtenemos pues los empleados de oficinas
del Este.
numem
p
nombre
eda
d
oficin
a
titulo
contrat
o
jefe cuota ventas
101
Antonio
Viguer
45 12
representant
e
1986-
10-20
104
30000,0
0
30500,0
0
103
103
Juan
Rovira
29 23
representant
e
1987-
03-01
104
27500,0
0
28600,0
0
104
Jos
Gonzle
z
33 23 dir ventas
1987-
05-19
106
20000,0
0
14300,0
0
105
Vicente
Pantalla
37 13
representant
e
1988-
02-12
104
35000,0
0
36800,0
0
106
Luis
Antonio
52 11 dir general
1988-
06-14
NUL
L
27500,0
0
29900,0
0
Si la subconsulta no devuelve ninguna fila:
SELECT *
FROM empleados
WHERE oficina IN (SELECT oficina
FROM oficinas
WHERE region = 'Otro');
La lista generada est vaca por lo que la condicin IN devuelve FALSE y en este caso
no sale ningn empleado.
Muchas veces la misma pregunta se puede resolver mediante una composicin de
tablas.
SELECT empleados.*
FROM Empleados INNER JOIN oficinas ON empleados.oficina =
oficinas.oficina
WHERE region = 'Este';
Esta sentencia es equivalente. En el resultado no queremos ver ninguna columna de la
tabla oficinas, el JOIN lo tenemos slo para la pregunta, en este caso pues se puede
sustituir por una subconsulta.
Unidad 6. Las subconsultas (III)
Si combinamos el operador IN con NOT obtenemos el operador NOT IN.
<expresion> NOT IN subconsulta
Devuelve TRUE si el valor de la expresin no est en la lista de valores devueltos por la
subconsulta.
SELECT *
104
FROM empleados
WHERE oficina NOT IN (SELECT oficina
FROM oficinas
WHERE region = 'Este');
Devuelve los empleados cuya oficina no est en la lista generada por la subconsulta, es
decir empleados que trabajan en oficinas que no son del Este.
OJO con NOT IN.
Hay que tener especial cuidado con los valores nulos cuando utilizamos el operador
NOT IN porque el resultado obtenido no siempre ser el deseado por ejemplo:
* En la consulta anterior no salen los empleados que no tienen oficina ya que para esos
empleados la columna oficina contiene NULL por lo que no se cumple el NOT IN.
* Si la subconsulta no devuelve ninguna fila, la condicin se cumplir para todas las filas
de la consulta externa, en este caso todos los empleados.
* Si la subconsulta devuelve algn valor NULL, la condicin NOT IN es NULL lo que nos
puede ocasionar algn problema.
Por ejemplo, queremos obtener las oficinas que no estn asignadas a ningn
empleado.
SELECT *
FROM Oficinas
WHERE oficina NOT IN (SELECT oficina
FROM empleados);
Esta consulta no devuelve ninguna fila cuando s debera ya que hay oficinas que nos
estn asignadas a ningn empleado. El problema est en que la columna oficina de la
tabla empleados admite nulos por lo que la subconsulta devuelve valores nulos en todos
los empleados que no estn asignados a ninguna oficina. Estos valores nulos hacen que
no se cumpla el NOT IN. La solucin pasa por eliminar estos valores molestos:
SELECT *
FROM Oficinas
WHERE oficina NOT IN (SELECT oficina
FROM empleados
WHERE oficina IS NOT NULL);
En el primer ejemplo no tenemos ese problema porque la columna oficina en oficinas no
admite nulos.
A diferencia de IN, NOT IN no siempre puede resolverse con una composicin:
SELECT numemp AS [IN]
105
FROM empleados
WHERE numemp IN (SELECT rep
FROM pedidos
WHERE fab = 'ACI');
Se puede resolver con una composicin:
SELECT DISTINCT empleados.numemp AS [=]
FROM Empleados INNER JOIN pedidos ON numemp = rep
WHERE fab = 'ACI';
En este caso, como un empleado puede tener varios pedidos hay que aadir DISTINCT
para eliminar las repeticiones de empleados (si un empleado tiene varios pedidos de ACI
aparecera varias veces).
Sin embargo esta sentencia con NOT IN, queremos los empleados que no tienen
pedidos de ACI:
SELECT numemp AS [NOT IN]
FROM empleados
WHERE numemp NOT IN (SELECT rep
FROM pedidos
WHERE fab = 'ACI');
No se puede resolver con una composicin:
SELECT DISTINCT empleados.numemp AS [<>]
FROM Empleados INNER JOIN pedidos ON numemp = rep
WHERE fab <> 'ACI';
Esta consulta devuelve los empleados que tienen pedidos que no son de ACI, pero un
empleado puede tener pedidos de ACI y otros de otros fabricantes y por estos otros
saldra en el resultado cuando s tiene pedidos de ACI y no debera salir.
Hay que tener mucho cuidado con este tipo de preguntas.
Para practicar puedes realizar este Ejercicio El operador IN con subconsulta.
Unidad 6. Las subconsultas (IV)
6.5. La comparacin modificada (ANY, ALL)
Los operadores de comparacin que presentan una subconsulta se pueden modificar
mediante las palabras clave ALL, ANY o SOME. SOME es un equivalente del estndar de
SQL-92 de ANY.
106
Se utiliza este tipo de comparacin cuando queremos comparar el resultado de la
expresin con una lista de valores y actuar en funcin del modificador empleado.
El test ANY
<expresion> {=|<>|!=|>|>=|!>|<|<=|!<} {ANY|SOME} subconsulta
ANY significa que, para que una fila de la consulta externa satisfaga la condicin
especificada, la comparacin se debe cumplir para al menos un valor de los devueltos por
la subconsulta.
Por cada fila de la consulta externa se evala la comparacin con cada uno de los
valores devueltos por la subconsulta y si la comparacin es True para alguno de los
valores ANY es verdadero, si la comparacin no se cumple con ninguno de los valores de
la consulta, ANY da False a no ser que todos los valores devueltos por la subconsulta
sean nulos en tal caso ANY dar NULL.
Si la subconsulta no devuelve filas ANY da False incluso si expresion es nula.
Ejemplo:
SELECT *
FROM empleados
WHERE cuota > ANY (SELECT cuota
FROM empleados empleados2
WHERE empleados.oficina = empleados2.oficina);
Obtenemos los empleados que tienen una cuota superior a la cuota de alguno de sus
compaeros de oficina, es decir los empleados que no tengan la menor cuota de su
oficina.
En este caso hemos tenido un alias de tabla en la subconsulta (empleados2) para
poder utilizar una referencia externa.
Para practicar puedes realizar este Ejercicio Comparacin modificada ANY.
El test ALL
<expresion> {=|<>|!=|>|>=|!>|<|<=|!<} ALL subconsulta
Con el modificador ALL, para que se cumpla la condicin, la comparacin se debe
cumplir con cada uno de los valores devueltos por la subconsulta.
Si la subconsulta no devuelve ninguna fila ALL da True.
SELECT *
FROM empleados
WHERE cuota > ALL (SELECT cuota
FROM empleados empleados2
WHERE empleados.oficina = empleados2.oficina);
107
En el ejemplo anterior obtenemos los empleados que tengan una cuota superior a todas
las cuotas de la oficina del empleado. Podramos pensar que obtenemos el empleado de
mayor cuota de su oficina pero no lo es, aqu tenemos un problema, la cuota del empleado
aparece en el resultado de subconsulta por lo tanto > no se cumplir para todos los
valores y slo saldrn los empleados que no tengan oficina (para los que la subconsulta
no devuelve filas).
Para salvar el problema tendramos que quitar del resultado de la subconsulta la cuota
del empleado modificando el WHERE:
WHERE empleados.oficina = empleados2.oficina
AND empleados.numemp <> empleados2.numemp);
De esta forma saldran los empleados que tienen una cuota mayor que cualquier otro
empleado de su misma oficina.
O bien
WHERE empleados.oficina = empleados2.oficina
AND empleados.cuota <> empleados2.cuota);
Para no considerar los empleados que tengan la misma cuota que el empleado. En este
caso saldran los empleados con la mayor cuota de sus oficina, pero si dos empleados
tienen la misma cuota superior, saldran, hecho que no sucedera con la otra versin.
Cuando la comparacin es una igualdad, = ANY es equivalente a IN y <> ALL es
equivalente a NOT IN (con los mismos problemas).
Unidad 6. Las subconsultas (V)
6.6. Subconsultas con cualquier nmero de columnas (EXISTS)
Existe otro operador de subconsulta con el que la subconsulta puede devolver ms de
una columna, el operador EXISTS.
En este caso la sintaxis es algo diferente:
WHERE [NOT] EXISTS subconsulta
No se realiza ninguna comparacin con los valores devueltos por la subconsulta,
simplemente se evala si la subconsulta devuelve alguna fila, en este caso EXISTS ser
True y si la subconsulta no devuelve ninguna fila, EXISTS ser False.
Ejemplo:
SELECT *
FROM empleados
WHERE EXISTS (SELECT *
FROM pedidos
108
WHERE numemp = rep and fab ='ACI');
Obtenemos los empleados que tengan un pedido del fabricante ACI. Por cada
empleado, se calcula la subconsulta (obteniendo los pedidos de ese empleado y con
fabricante ACI), si existe alguna fila, el empleado sale en el resultado, si no, no sale.
Cuando se utiliza el operador EXISTS es muy importante aadir una referencia externa,
no es obligatorio pero en la mayora de los casos ser necesario. Vemoslo con ese
mismo ejemplo, si quitamos la referencia externa:
SELECT *
FROM empleados
WHERE EXISTS (SELECT *
FROM pedidos
WHERE fab ='ACI');
Sea el empleado que sea, la subconsulta siempre devolver filas (si existe algn
pedido cuyo fabricante sea ACI) o nunca, indistintamente del empleado que sea, por lo
que se obtendrn todos los empleados o ninguno para que el resultado vare segn las
filas de la consulta externa habr que incluir una referencia externa.
Otra cosa a tener en cuenta es que la lista de seleccin de una subconsulta que se
especifica con EXISTS casi siempre consta de un asterisco (*). No hay razn para
enumerar los nombres de las columnas porque no se van a utilizar y supone un trabajo
extra para el sistema.
Si utilizamos NOT EXISTS el resultado ser el contrario.
SELECT *
FROM empleados
WHERE NOT EXISTS (SELECT *
FROM pedidos
WHERE fab ='ACI' AND rep=numemp);
Devuelve los empleados que no tienen ningn pedido de ACI.
Unidad 7. Actualizacin de datos (I)
7.1. Introduccin
Hasta ahora hemos trabajado con tablas que tenan datos introducidos y cuando nos ha
hecho falta hemos aadido nuevos datos en las mismas y hemos modificado algn dato
directamente desde el entorno de SSMS, en este tema veremos cmo hacerlo con
instrucciones de Transact-SQL.
Seguimos en el DML porque las instrucciones que veremos actan sobre los datos de
la base de datos no sobre su definicin y tenemos tres tipos de operaciones posibles:
109
Insertar nuevas filas en una tabla.
Modificar datos ya almacenados.
Eliminar filas de una tabla.
7.2. Insertar creando una nueva tabla
Una forma de insertar datos es crear una tabla que incluya los datos de otra. Esta es la
sentencia SELECT... INTO.
SELECT ...
INTO nb_NuevaTabla
FROM ...
nb_NuevaTabla es el nombre de la tabla que se va a crear, si en la base de datos ya
hay una tabla con ese nombre, el sistema genera un error y no se ejecuta la sentencia.
En la nueva tabla las columnas tendrn el mismo tipo y tamao que las columnas del
resultado de la SELECT, se llamarn con el nombre de alias de la columna o en su
defecto con el nombre de la columna, pero no se transfiere ninguna otra propiedad del
campo o de la tabla como por ejemplo las claves e ndices.
Si retomamos el ejemplo del punto anterior:
CREATE TABLE trabajo (col1 INT, col2 VARCHAR(20), col3 MONEY);
INSERT INTO trabajo SELECT oficina, ciudad, ventas
FROM oficinas
WHERE region = 'Centro';
Se podra obtener el mismo resultado con una sola instruccin:
SELECT oficina AS col1, ciudad AS col2, ventas AS col3
INTO trabajo
FROM oficinas
WHERE region = 'Centro'
Si se tiene poca experiencia en esta instruccin, lo mejor es primero escribir la SELECT
que permite obtener las filas a insertar y una vez la tenemos aadir la clusula INTO
destino delante de FROM.
Para practicar puedes realizar este Ejercicio Insertar datos creando una nueva tabla.
7.3. Insertar en una tabla existente INSERT INTO
La insercin de nuevos datos en una tabla, se realiza aadiendo filas enteras a la tabla,
la sentencia SQL que lo permite es la orden INSERT (o tambin denominada INSERT
INTO).
110
De la sentencia INSERT completa, nosotros estudiaremos la sintaxis ms utilizada y
estndar:
INSERT [INTO] <destino>
{
[(lista_columnas)]
{VALUES ({DEFAULT|NULL|expresion}[ ,...n ])
|tabla_derivada
}
}
|DEFAULT VALUES
[;]
<destino> ::=
{
[nbBaseDatos.nbEsquema. | nbEsquema.]nbTablaVista
}
Con esta instruccin podemos insertar una fila de valores determinados o un conjunto
de filas derivadas de otra consulta.
Unidad 7. Actualizacin de datos (II)
7.4. Insertar una fila de valores
Para insertar una fila de valores utilizamos la sintaxis:
INSERT [INTO] <destino> [(lista_columnas)]
VALUES ({DEFAULT|NULL|expresion}[ ,...n ]) [;]
La palabra reservada INTO es opcional y no aade funcionalidad a la instruccin,
originalmente era obligatoria.
Despus de indicar que queremos insertar, debemos indicar dnde, mediante
<destino>.
<destino> es el nombre de la tabla donde queremos insertar, puede ser un nombre de
tabla o un nombre de vista.
Si utilizamos una vista, y sta tiene un origen basado en varias tablas, en su lista de
seleccin debern aparecer columnas de una sola tabla (no podemos insertar datos en
varias tablas a la vez).
Con la clusula VALUES indicamos entre parntesis los valores a insertar, separados
por comas.
Cada valor se puede indicar mediante:
111
una expresin que normalmente ser una constante,
mediante la palabra reservada DEFAULT que indica valor por defecto en este caso
la columna se rellenar con el valor predeterminado de la columna, si la columna no
tiene DEFAULT se sustituir por el valor nulo NULL.
Mediante la palabra reservada NULL valor nulo.
Delante de VALUES, de forma opcional podemos indicar una lista de columnas entre
parntesis. Las columnas son columnas del destino.
Cuando indicamos nombres de columnas, esas columnas sern las que reciban los
valores a insertar, la asignacin de valores se realiza por posicin, la primera columna
recibe el primer valor, la segunda columna el segundo, y as sucesivamente.
En la lista, las columnas pueden estar en cualquier orden y tambin se pueden omitir
algunas columnas.
Una columna que no aparezca en la lista de columnas se rellenar de acuerdo a su
definicin:
con su valor por defecto si est definida con la clusula DEFAULT
con el valor de identidad incremental siguiente si tiene la propiedad IDENTITY.
con el valor calculado si es una columna calculada.
con el valor NULL , en cualquier otro caso y si la columna lo admite.
Cuando no se indica una lista de columnas el sistema asume por defecto todas las
columnas de la tabla y en el mismo orden que aparecen en la definicin de la tabla, en
este caso, los valores se tienen que especificar en el mismo orden que las columnas en la
definicin de la tabla, y se tiene que especificar un valor por cada columna ya que los
valores se rellenan por posicin, la primera columna recibe el primer valor, la segunda
columna el segundo, y as sucesivamente.
En cualquier caso, el nmero de valores debe coincidir con el nmero de columnas y
los tipos de dato de los valores deben ser compatibles con las columnas.
Aunque pueda parecer ms engorroso escribir la lista de columnas, es un hbito
recomendable, hace que la sentencia sea ms fcil de leer y mantener (cuando leemos la
sentencia sabemos en qu columnas asignamos los valores sin necesidad de consultar la
definicin de la tabla) y evita que se tenga que cambiar la sentencia si se modifica el
esquema de la tabla (si el orden de las columnas dentro de la tabla cambia).
Los registros se agregan al final de la tabla.
Cuando se insertan nuevas filas en una tabla, el sistema comprobar que la nueva fila
no infrinja ninguna regla de integridad, por ejemplo no podremos asignar a una columna
PRIMARY KEY un valor nulo o que ya exista en la tabla, a una columna UNIQUE un valor
que ya exista en la tabla, a una columna NOT NULL un valor NULL, a una clave ajena
(FOREIGN KEY) un valor que no exista en la tabla de referencia.
De producirse alguna de las situaciones anterior, la instruccin genera un mensaje de
error y la fila no se inserta.
Ejemplos.
INSERT INTO oficinas (oficina, ciudad) VALUES (26, 'Elx');
112
En este caso hemos indicado slo dos columnas y dos valores, las dems columnas se
rellenan con el valor por defecto si lo tiene (DEFAULT) o con NULL. Si alguna columna no
nombrada no admite nulos ni tiene clusula DEFAULT definida, la instruccin dar error.
INSERT INTO oficinas
VALUES (27,'Mstoles','Centro',default ,null, default)
Aqu no hemos indicado una lista de columnas luego los valores se tienen que indicar
en el mismo orden que las columnas dentro de la tabla, si nos equivocamos de orden, el
valor se guardar en una columna errnea (si los tipos son compatibles) o generar un
mensaje de error y la fila no se insertar (si los tipos no son compatibles).
Unidad 7. Actualizacin de datos (III)
7.5. Insercin de varias filas
Si los valores que queremos insertar los tenemos en otras tablas, podemos insertar
varias filas a la vez indicando una consulta que genere las filas de valores a insertar. En
este caso utilizamos la sintaxis:
INSERT [INTO] <destino> [(lista_columnas)]
tabla_derivada [;]
<destino> y lista_columnas funcionan igual que en el punto anterior.
Tabla_derivada es cualquier instruccin SELECT vlida que devuelva filas con los datos
que se van a cargar en el destino.
Cada fila devuelta por la SELECT es una lista de valores que se intentar insertar como
con la clusula VALUES, por lo que las columnas devueltas por la SELECT debern
cumplir las mismas reglas que los valores de la lista de valores anteriores.
Ejemplo:
CREATE TABLE trabajo (col1 INT, col2 VARCHAR(20), col3 MONEY);
Creamos una tabla trabajo de 3 columnas
INSERT INTO trabajo SELECT oficina, ciudad, ventas
FROM oficinas
WHERE region = 'Centro';
Insertamos en trabajo el resultado de la SELECT (el nmero de oficina, ciudad y ventas
de las oficinas del Centro).
En este caso no hemos incluido una lista de columnas, por lo que en la SELECT
tenemos que generar los valores en el mismo orden que en trabajo.
Si hubiesemos escrito:
113
INSERT INTO trabajo SELECT ciudad, oficina, ventas
FROM oficinas
WHERE region = 'Centro';
Hubiese dado error porque la columna col1 es INT y el valor a asignar es texto (el
nombre de la ciudad de la oficina).
INSERT INTO trabajo (col2, col1)
SELECT ciudad, oficina
FROM oficinas
WHERE region = 'Este';
En este caso hemos incluido una lista de columnas, la SELECT debe generar los
valores correspondientes, y col3 que no se rellena explcitamente se rellenar con NULL
porque la columna col3 no est definida como columna calculada, ni con DEFAULT, ni
IDENTITY y adems admite nulos.
Para practicar puedes realizar este Ejercicio Insertar varias filas.
7.6. Insertar una fila de valores por defecto
TRANSACT-SQL nos permite insertar una fila de valores por defecto utilizando la
sintaxis:
INSERT [INTO] <destino> DEFAULT VALUES
[;]
Hace que la nueva fila contenga los valores predeterminados definidos para cada
columna.
Hay que tener en cuenta una serie de aspectos al utilizar esta instruccin:
Puede generar filas duplicadas en la tabla si los valores que se generan son siempre los
mismos.
Si la tabla tiene una clave principal, esta tendr que estar basada en una columna con la
propiedad IDENTITY para que se generen valores diferentes automticamente.
Si una columna est definida como NOT NULL tendr que incluir un DEFAULT o ser una
columna calculada con una expresin compatible.
Unidad 7. Actualizacin de datos (IV)
7.7. Modificar datos almacenados - UPDATE
La sentencia UPDATE modifica los valores de una o ms columnas en las filas
seleccionadas de una nica tabla.
Para modificar los datos de una tabla es necesario disponer del privilegio UPDATE
sobre dicha tabla.
UPDATE
114
[ TOP ( expression ) [ PERCENT ] ]
<destino>
SET { nbcolumna = { expresion | DEFAULT | NULL }
} [ ,...n ]
[ FROM{ <origen> }]
[ WHERE <condicion> ]
[;]
<destino> ::=
{
[nbBaseDatos.[nbEsquema.]| nbEsquema.]nbTablaVista
}
Con <destino> indicamos la tabla que se va a actualizar.
La clusula SET especifica qu columnas van a modificarse y con qu valor, el valor se
puede expresar mediante una expresin, la palabra DEFAULT que equivale al valor
predeterminado de la columna, o el valor nulo NULL.
Las columnas de identidad no se pueden actualizar.
Expresin en cada asignacin debe generar un valor del tipo de dato apropiado para la
columna indicada. La expresin debe ser calculable basada en los valores de la fila
actualmente en actualizacin. Si para el clculo se utiliza una columna que tambin se
modifica, el valor que se utilizar es el de antes de la modificacin, lo mismo para la
condicin del WHERE.
Expresin tambin puede ser una subconsulta siempre y cuanto devuelva un nico
valor y cumpla las condiciones anteriormente expuestas.
Por ejemplo:
UPDATE oficinas SET ventas = 0;
Actualiza todas las filas de la tabla oficinas dejando el campo ventas con el valor cero.
Si el campo ventas est definido con un valor predeterminado 0, la sentencia anterior
equivale a:
UPDATE oficinas SET ventas = DEFAULT;
Si lo que queremos es dejar el campo a nulo:
UPDATE oficinas SET ventas = NULL;
En una misma sentencia podemos actualizar varias columnas, slo tenemos que indicar
las distintas asignaciones separadas por comas:
UPDATE oficinas SET ventas = 0, objetivo = 0;
115
Los nombres de columna pueden especificarse en cualquier orden.
Si no queremos actualizar todas las filas de la tabla sino unas cuantas, utilizaremos la
clusula TOP, o unas determinadas, utilizaremos la clusula WHERE.
TOP ( expresion ) [ PERCENT ]
Especifica el nmero o porcentaje de filas aleatorias que se van a modificar.
expression debe generar un valor numrico e indica el nmero de filas a modificar
empezando por el principio. Como en la SELECT, si aadimos la palabra PERCENT, el
nmero representado por expresin se refiere al porcentaje de filas a modificar sobre el
total. La clusula TOP funciona casi igual que en la SELECT pero en este caso, las filas
no se ordenan, y la expresin debe ir entre parntesis.
Por ejemplo:
UPDATE TOP (10) PERCENT oficinas
SET ventas = 0;
Actualiza el 10% de filas de la tabla oficinas.
[ WHERE <condicion> ]
Utilizamos la clusula WHERE para filtrar las filas a actualizar. Se actualizarn todas las
filas que cumplan la condicin. Por ejemplo si queremos actualizar slo las oficinas del
Este:
UPDATE oficinas
SET ventas = 0
WHERE region = 'Este';
Cuando para la condicin de la clusula WHERE necesitamos un dato de otra tabla
podemos utilizar una subconsulta:
UPDATE empleados SET ventas = 0
WHERE oficina IN (SELECT oficina
FROM oficinas
WHERE region = 'Este');
Cuando el campo de la otra tabla se utiliza para la clusula SET, entonces debemos
utilizar la clusula FROM.
La clusula FROM permite definir un origen de datos basado en varias tablas, y ese
origen ser el utilizado para realizar la actualizacin.
Por ejemplo queremos actualizar el importe de los pedidos con el precio de la tabla
productos.
UPDATE pedidos SET importe = cant * precio
116
FROM pedidos INNER JOIN productos
ON fab = idfab AND producto = idproducto;
Modificamos la tabla pedidos dejando en la columna importe el resultado de multiplicar
la cantidad del pedido por el precio del producto que se encuentra en la tabla productos.
Si la actualizacin de una fila infringe una restriccin o una regla, infringe la
configuracin de valores NULL de la columna o si el nuevo valor es de un tipo de datos
incompatible con la columna, se cancela la instruccin, se devuelve un error y no se
actualiza ningn registro.
Cuando una instruccin UPDATE encuentra un error aritmtico (error de
desbordamiento, divisin por cero o de dominio) durante la evaluacin de la expresin, la
actualizacin no se lleva a cabo. El resto del lote no se ejecuta y se devuelve un mensaje
de error.
Adems del permiso de UPDATE, se requieren permisos SELECT para la tabla que se
actualiza si la instruccin UPDATE contiene una clusula WHERE o en el caso de que el
argumento expression de la clusula SET utilice una columna de la tabla, y permisos
SELECT para la tabla del origen si utilizamos una clusula FROM o un WHERE con
subconsulta.
Unidad 7. Actualizacin de datos (V)
7.8. Eliminar filas - DELETE
La sentencia DELETE elimina filas de una tabla. Si se borran todas las filas, o se borra
la nica fila de una tabla, la definicin de la tabla no desaparece, slo que la tabla se
queda vaca.
DELETE
[ TOP ( expression ) [ PERCENT ] ] [ FROM ] <destino>
[ FROM <origen>]
[ WHERE < condicion>]
[; ]
<destino> ::=
{
[nbBaseDatos. nbEsquema. | nbEsquema.]nbTablaVista
}
Con esta instruccin podemos eliminar una o varias filas de una tabla.
La palabra FROM (la primera) es opcional (originalmente era obligatorio) y no aade
funcionalidad slo sirve para introducir el destino.
<destino> es el nombre de la tabla de donde queremos eliminar las filas, puede ser un
nombre de tabla o un nombre de vista (de momento basada en una slo tabla).
La segunda clusula FROM sirve para indicar un origen que permita una condicin de
WHERE sobre una tabla diferente de destino.
117
La instruccin bsica sera pues:
DELETE oficinas;
Equivalente a:
DELETE FROM oficinas;
Con esta instruccin eliminamos todas las filas de la tabla oficinas.
La clusula WHERE permite eliminar determinadas filas, indica una condicin que
deben cumplir las filas que se eliminan.
Por ejemplo:
DELETE oficinas
WHERE region = Este;
Elimina las oficinas del Este.
TOP ( expresion ) [ PERCENT ]
Especifica el nmero o porcentaje de filas aleatorias que se van a eliminar.
expression debe generar un valor numrico e indica el nmero de filas a eliminar
empezando por el principio. Como en la SELECT, si aadimos la palabra PERCENT, el
nmero representado por expresin se refiere al porcentaje de filas a eliminar sobre el
total. La clusula TOP funciona casi igual que en la SELECT pero en este caso, las filas
no se ordenan, y la expresin debe ir entre parntesis.
Por ejemplo:
DELETE TOP (10) PERCENT
FROM oficinas;
Elimina el 10% de filas de la tabla oficinas.
Originalmente slo se poda indicar una tabla en la clusula FROM, pero ahora
podemos indicar un origen basado en varias tablas.
Si utilizamos un origen basado en varias tablas, se debe de utilizar una extensin de
TRANSACT-SQL que consiste en escribir dos clusulas FROM, una indica la tabla de
donde eliminamos las filas y la otra el origen que utilizamos para eliminar.
Este caso se produce cuando las filas a eliminar dependen de un valor que est en otra
tabla. Por ejemplo queremos eliminar los empleados de las oficinas del Este. Como la
regin de la oficina no est en empleados, habra que aadir al origen la tabla oficinas
para poder formular la condicin del WHERE:
DELETE FROM empleados
FROM empleados INNER JOIN oficinas
ON empleados.oficina = oficinas.oficina
118
WHERE region = 'Este';
En el origen tenemos las dos tablas y en la primera FROM indicamos de qu tabla
queremos borrar.
Esto se poda haber resuelto, como toda la vida, mediante una subconsulta:
DELETE FROM empleados
WHERE oficina IN (SELECT oficina
FROM oficinas
WHERE region = 'Este');
Para finalizar no debemos olvidar que para poder ejecutar un DELETE se requieren
permisos DELETE en la tabla de donde vamos a eliminar, y tambin se requieren los
permisos para utilizar SELECT si la instruccin contiene una clusula WHERE.
Muy importante siempre que actualicemos datos en nuestras tablas, no debemos
olvidar tampoco las reglas de integridad referencial. Si la tabla afectada interviene como
tabla principal en una relacin con otra tabla, no se podrn eliminar sus filas que estn
relacionadas con registros de la otra tabla (no se pueden eliminar padres que tengan
hijos ). Si se van a eliminar varias filas y al menos una no se puede eliminar por infringir
las reglas de integridad, entonces la operacin abortar y no se eliminar ninguna fila.
En el ejemplo anterior, si un empleado asignado a una oficina del Este tiene pedidos, no
se podr eliminar y entonces no se eliminar ningn empleado.
Unidad 7. Actualizacin de datos (VI)
7.9. Borrado masivo - TRUNCATE
Si queremos eliminar todas las filas de una tabla podemos utilizar tambin la instruccin
TRUNCATE TABLE.
TRUNCATE TABLE
[nbBaseDatos.[nbEsquema.]| nbEsquema.]nbTabla [; ]
Esta sentencia quita todas las filas de una tabla sin registrar las eliminaciones
individuales de filas. Desde un punto de vista funcional, TRUNCATE TABLE es
equivalente a la instruccin DELETE sin una clusula WHERE; no obstante, TRUNCATE
TABLE es ms rpida y utiliza menos recursos de registros de transacciones y de sistema.
En comparacin con la instruccin DELETE, TRUNCATE TABLE ofrece las siguientes
ventajas:
Se utiliza menos espacio del registro de transacciones.
La instruccin DELETE quita una a una las filas y graba una entrada en el registro
de transacciones por cada fila eliminada.
TRUNCATE TABLE quita los datos al cancelar la asignacin de las pginas de datos
utilizadas para almacenar los datos de la tabla y slo graba en el registro de
transacciones las cancelaciones de asignacin de pginas.
119
Por regla general, se utilizan menos bloqueos.
Si se ejecuta la instruccin DELETE con un bloqueo de fila, se bloquea cada fila de
la tabla para su eliminacin. TRUNCATE TABLE siempre bloquea la tabla y la
pgina, pero no cada fila.
Las pginas cero se conservan en la tabla sin excepciones.
Despus de ejecutar una instruccin DELETE, la tabla puede seguir conteniendo
pginas vacas. Por ejemplo, no se puede cancelar la asignacin de las pginas
vacas de un montn sin un bloqueo de tabla exclusivo como mnimo. Si en la
operacin de eliminacin no se utiliza un bloqueo de tabla, la tabla contiene muchas
pginas vacas. En el caso de los ndices, la operacin de eliminacin puede dejar
pginas vacas, aunque la asignacin de estas pginas se puede cancelar
rpidamente mediante un proceso de limpieza en segundo plano.
Si la tabla contiene una columna de identidad, el contador para dicha columna se
restablece al valor de inicializacin definido para ella. Si no se define ningn valor de
inicializacin, se utiliza el valor predeterminado 1. Para conservar el contador de identidad,
se utiliza DELETE.
Pero no todo son ventajas, no se puede utilizar TRUNCATE TABLE en las siguientes
tablas:
Tablas a las que se hace referencia mediante una restriccin FOREIGN KEY (las
tablas que entran como principales en una relacin).
Tablas que participan en una vista indizada.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (I)
8.1. Introduccin
El DDL (Data Definition Language, o Data Description Language segn autores), es la
parte del SQL dedicada a la definicin de la base de datos, consta de sentencias para
definir la estructura de la base de datos, permite definir gran parte del nivel interno de la
base de datos. Por este motivo estas sentencias sern utilizadas normalmente por el
administrador de la base de datos.
La definicin de la estructura de la base de datos incluye tanto la creacin inicial de los
diferentes objetos que formarn la base de datos, como el mantenimiento de esa
estructura. Las sentencias del DDL utilizan unos verbos que se repiten para los distintos
objetos. Por ejemplo para crear un objeto nuevo el verbo ser CREATE y a continuacin
el tipo de objeto a crear. CREATE DATABASE es la sentencia para crear una base de
datos, CREATE TABLE nos permite crear una nueva tabla, CREATE INDEX crear un
nuevo ndice Para eliminar un objeto utilizaremos el verbo DROP (DROP TABLE, DROP
INDEX) y para modificar algo de la definicin de un objeto ya creado utilizamos el verbo
ALTER (ALTER TABLE, ALTER INDEX).
Los objetos que veremos en este tema son:
Bases de datos
Tablas
Vistas
ndices
120
Como ya hemos comentado, las sentencias DDL estn ms orientadas al administrador
de la base de datos, es el que ms las va a utilizar, el programador tiene que conocer
cuestiones relativas a la estructura interna de una base de datos, pero no tiene que ser
experto en ello por lo que el estudio del tema se centrar en las sentencias y sobre todo
en las clusulas que pensamos pueden ser tiles a un programador y no entraremos en
mucho detalle en cuanto a la estructura fsica de la base de datos y en la administracin
de la misma.
8.2. Definir una base de datos CREATE DATABASE
Estructura interna
Como ya vimos en el primer tema, las bases de datos de SQL Server 2005 utilizan tres
tipos de archivos:
Archivos de datos principales (.mdf): Archivo requerido.
Archivos de datos secundarios (.ndf): Archivo opcional.
Archivos de registro (.ldf): Archivo requerido.
Y se deben situar en sistemas de archivos FAT o NTFS. Se recomienda NTFS.
CREATE DATABASE
CREATE DATABASE nbBasedeDatos
[ ON
[ PRIMARY ] [ <esp_fichero> [ ,...n ]
[ , <grupo> [ ,...n ] ]
[ LOG ON { < esp_fichero > [ ,...n ] } ]
]
[ COLLATE nbintercalacion]
[ WITH <external_access_option> ]
]
[;]
Como vemos la instruccin mnima es:
CREATE DATABASE nbBasedeDatos
nbBasedeDatos: Es el nombre de la nueva base de datos. Los nombres de base de
datos deben ser nicos en una instancia de SQL Server y cumplir las reglas de los
identificadores. Puede tener 128 caracteres como mximo, excepto en un caso que
veremos ms adelante.
Con la clusula ON especificamos los ficheros utilizados para almacenar los archivos
de datos.
[ ON
[ PRIMARY ] [ <esp_fichero> [ ,...n ]
121
[ , <grupo> [ ,...n ] ]
<esp_fichero> ::=
(
NAME = nbfichero_logico ,
FILENAME = 'nbfichero_fisico'
[ , SIZE = tamao [ KB | MB | GB | TB ] ]
[ , MAXSIZE = { max_size [ KB | MB | GB | TB ] |
UNLIMITED } ]
[ , FILEGROWTH = incremento_crecimiento [ KB | MB | GB |
TB | % ] ]
)
nbfichero_logico es el nombre que se utiliza para hacer referencia al archivo en todas
las instrucciones Transact-SQL. El nombre de archivo lgico tiene que cumplir las reglas
de los identificadores de SQL Server y tiene que ser nico entre los nombres de archivos
lgicos de la base de datos.
nbfichero_fisico es el nombre del archivo fsico que incluye la ruta de acceso al
directorio. Debe seguir las reglas para nombres de archivos del sistema operativo.
Con la clusula SIZE indicamos el tamao original del archivo.
Los archivos de SQL Server 2005 pueden crecer automticamente a partir del tamao
originalmente especificado. Con FILEGROWTH se puede especificar un incremento de
crecimiento y cada vez que se llena el archivo, el tamao aumentar en la cantidad
especificada.
Cada archivo tambin puede tener un tamao mximo especificado con MAXSIZE. Si
no se especifica un tamao mximo, el archivo puede crecer hasta utilizar todo el espacio
disponible en el disco. Esta caracterstica es especialmente til cuando SQL Server se
utiliza como una base de datos incrustada en una aplicacin para la que el usuario no
dispone fcilmente de acceso a un administrador del sistema. El usuario puede dejar que
los archivos crezcan automticamente cuando sea necesario y evitar as las tareas
administrativas de supervisar la cantidad de espacio libre en la base de datos y asignar
ms espacio manualmente.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (II)
Si no se especifica un nombre de archivo de datos, SQL Server utiliza el nombre de la
base de datos como nbfichero_logico y nbfichero_fisico.
Si queremos definir varios archivos de datos, despus de la palabra ON escribiremos
las definiciones de cada archivo separadas por comas.
PRIMARY especifica que la lista de archivos asociada define el grupo de archivos
principal, y el primer archivo especificado se convierte en el archivo de datos principal.
Si no se especifica PRIMARY, el primer archivo enumerado en la instruccin CREATE
DATABASE se convierte en el archivo principal.
Detrs de la lista de archivos del grupo de archivos principal, con <grupo> se puede
colocar una lista opcional de elementos separados por comas que definan los grupos de
archivos de usuario y sus archivos.
122
<grupo> ::=
{
FILEGROUP nbgrupo [ DEFAULT ]
<esp_fichero> [ ,...n ]
}
Nbgrupo es el nombre del grupo y a continuacin indicamos los archivos de datos que
pertenecen a ese grupo, los archivos pertenecientes al grupo se indican con los del grupo
principal.
DEFAULT
Cambia el grupo de archivos predeterminado de la base de datos a Nbgrupo. Slo un
grupo de archivos de la base de datos puede ser el grupo de archivos predeterminado.
Con la clusula LOG ON definiremos los archivos utilizados para almacenar el registro
de la base de datos (los archivos de registro).
[ LOG ON { <esp_fichero> [ ,...n ] } ]
Si no se especifica LOG ON, se crea automticamente un archivo de registro cuyo
tamao es el 25 por ciento de la suma de los tamaos de todos los archivos de datos de la
base de datos, o 512 KB (lo que sea mayor), tambin limitar el nombre de la base de
datos a 123 caracteres ya que el sistema generar el nombre del archivo de registro
aadiendo al nombre de la base de datos un sufijo.
Con la clusula COLLATE podemos cambiar la intercalacin predeterminada.
La intercalacin define:
El alfabeto o lenguaje cuyas reglas de ordenacin se aplican si se especifica la
ordenacin de diccionario.
La pgina de cdigos usada para almacenar datos de caracteres que no son
Unicode.
Las reglas de comportamiento frente a maysculas y minsculas y caracteres
acentuados.
La sintaxis es la siguiente:
COLLATE <nbintercalacion>
< nbintercalacion >:: =
nbinterWindows_ CaseSensitivity_AccentSensitivity
nbinterWindows: Es un nombre de intercalacin de Windows. Visita el siguiente bsico
para saber ms sobre las intercalaciones.
CaseSensitivity: Especifica que s se distingue entre maysculas y minsculas (CS), o
no (CI). SQL Server Mobile slo admite esta opcin.
AccentSensitivity: Especifica si se distinguen los caracteres acentuados (AS), o no (AI).
SQL Server Mobile slo admite la opcin AS.
Si no se especifica, se asigna a la base de datos la intercalacin predeterminada de la
instancia de SQL Server. No se puede especificar un nombre de intercalacin en una
123
instantnea de base de datos, ni tampoco con las clusulas FOR ATTACH o FOR.
Existen otras clusulas a nivel de administracin de la base de datos que no detallaremos
aqu como son:
[ WITH <external_access_option> ]
<external_access_option> ::=
{
DB_CHAINING { ON | OFF }
| TRUSTWORTHY { ON | OFF }
}
Para controlar el acceso externo a la base de datos y desde sta.
CREATE DATABASE nbBasedeDatos
ON <esp_fichero> [ ,...n ]
FOR { ATTACH [ WITH <service_broker_option> ]
| ATTACH_REBUILD_LOG }
[;]
<service_broker_option> ::=
{
ENABLE_BROKER
| NEW_BROKER
| ERROR_BROKER_CONVERSATIONS
}
Para adjuntar una base de datos.
CREATE DATABASE nbInstantanea_basedatos
ON
(
NAME = nbfichero_logico ,
FILENAME = 'nbfichero_fisico'
) [ ,...n ]
AS SNAPSHOT OF nbBaseDatos_origen
[;]
Para crear una instantnea de base de datos (copia de slo lectura de una base de
datos).
CREATE DATABASE database_name
[DATABASEPASSWORD 'database_password'
124
[ENCRYPTION {ON|OFF}]
]
[COLLATE collation_name comparison_style]
database password ::= identifier
Para crear una base de datos protegida mediante contrasea, opcin disponible para
SQL Server Mobile (Microsoft SQL Server 2005 Mobile Edition (SQL Server Mobile), antes
denominado Microsoft SQL Server 2000 Windows CE 2.0 (SQL Server CE), es una base
de datos compacta y con una gran variedad de funciones diseada para admitir una lista
ampliada de dispositivos inteligentes y Tablet PC. Entre los dispositivos inteligentes estn
todos los dispositivos que ejecuten Microsoft Windows CE 5.0, Microsoft Mobile
Pocket PC 2003, Microsoft Mobile Version 5.0 Pocket PC o Microsoft Mobile Version 5.0
Smart Phone. Esta compatibilidad adicional con dispositivos permite a los programadores
usar la misma funcionalidad de base de datos en un gran nmero de dispositivos.)
Unidad 8. El DDL, Lenguaje de Definicin de Datos (III)
8.3. Eliminar una base de datos DROP DATABASE
Para eliminar una base de datos tenemos la instruccin DROP DATABASE.
DROP DATABASE { nbBasedeDatos } [ ,...n ] [;]
La base de datos puede ser una base de datos normal o una instantnea de base de
datos.
Para poder ejecutar la sentencia el usuario debe tener permiso de CONTROL y se debe
de ejecutar en un contexto diferente del de la base de datos a eliminar, por ejemplo:
use b1
DROP DATABASE b1
Falla porque con el use estamos en el contexto de la base de datos a eliminar.
Como se ve en la sintaxis podemos eliminar varias bases de datos con una sla
sentencia DROP DATABASE.
Por ejemplo:
DROP DATABASE b1,b2
Elimina las bases de datos b1 y b2.
8.4. Modificar las propiedades de una BD ALTER DATABASE
Si despus de crear la base de datos queremos cambiar algo de su definicin
podramos eliminarla (con DROP DATABASE) y luego crearla otra vez (con CREATE
DATABASE), pero si ya la hemos rellenado con tablas u otros objetos, esta solucin no
sera muy prctica. Para cambiar la definicin de la base de datos una vez creada
tenemos que utilizar la sentencia ALTER DATABASE.
125
Para poder ejecutar esta sentencia se debe de tener el permiso ALTER en la base de
datos. Esta sentencia se debe ejecutar en el modo de confirmacin automtica (modo de
administracin de transacciones predeterminado) y no se permite en una transaccin
explcita o implcita.
Las instantneas de bases de datos no se pueden modificar, y para modificar las
opciones de base de datos asociadas a la rplica, se utiliza el procedimiento almacenado
del sistema sp_replicationdboption.
Sintaxis:
ALTER DATABASE nbBasedeDatos
{
<cambiar_ficheros>
| <cambiar_grupos>
| <opciones>
| MODIFY NAME = nuevo_nbBasedeDatos
| COLLATE nbintercalacin
}
[;]
Con esta sentencia resumida vemos que nos permite cambiar la definicin de la base
de datos, nos va a permitir cambiar la definicin de los ficheros que conforman la base de
datos, tambin nos permite cambiar la definicin de los grupos, la definicin de varias
opciones, el tipo de intercalacin e incluso cambiar el nombre de la base de datos (con la
clusula MODIFY NAME).
Por ejemplo:
ALTER DATABASE Cliente
MODIFY NAME = Clientes;
La base de datos Cliente pasa a llamarse Clientes.
Como con la instruccin CREATE DATABASE veremos aqu un resumen de lo que ms
le puede interesar a un programador, sin entrar en demasiados detalles de administracin.
Como muchas de las palabras ya las hemos explicado con la sentencia CREATE
DATABASE, slo insistiremos en lo nuevo.
<cambiar_ficheros>::=
{
ADD FILE < esp_fichero > [ ,...n ]
[ TO FILEGROUP { nbgrupo | DEFAULT } ]
| ADD LOG FILE < esp_fichero > [ ,...n ]
| REMOVE FILE nbfichero
| MODIFY FILE < esp_fichero >
126
}
Con este grupo de opciones podemos cambiar la definicin de los archivos de datos de
la base de datos.
ADD FILE permite aadir un nuevo archivo de datos (o varios) si no se aade nada (o
TO FILEGROUP DEFAULT), el archivo se aadir al grupo principal, si aadimos TO
FILEGROUP nbgrupo, se aadir el archivo al grupo indicado.
Con ADD LOG FILE podemos aadir un nuevo archivo de registro.
Con REMOVE FILE nbfichero eliminamos el archivo con nombre nbfichero.
Se elimina la definicin del archivo lgico (nbfichero) y elimina el archivo fsico asociado.
El archivo no se puede quitar a menos que est vaco.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (IV)
Con MODIFY FILE <esp_fichero> podemos cambiar las especificaciones de alguno de
los archivos de la base de datos.
<esp_fichero>::=
(
NAME = nbarchivo
[ , NEWNAME = nuevo_nbarchivo ]
[ , FILENAME = 'nbarchivo_fisico' ]
[ , SIZE = tamao [ KB | MB | GB | TB ] ]
[ , MAXSIZE = { tamao_mximo [ KB | MB | GB | TB ] |
UNLIMITED } ]
[ , FILEGROWTH = incremento [ KB | MB | GB | TB| % ] ]
[ , OFFLINE ]
)
Slo se puede cambiar una propiedad <especificacinDeArchivo> cada vez.
NAME se debe especificar siempre para identificar el archivo que se va a modificar.
Si se especifica SIZE, el nuevo tamao debe ser mayor que el tamao actual del archivo.
Para reducir el tamao de una base de datos, se utiliza el comando de
consola SHRINKDATABASE de Transact_SQL.
Para modificar el nombre lgico de un archivo de datos o de un archivo de registro,
especificamos el nombre lgico nuevo para el archivo en la clusula NEWNAME. Por
ejemplo:
ALTER DATABASE MiBasedeDatos
MODIFY FILE ( NAME = bd1, NEWNAME = base1)
Con esta sentencia, el archivo bd1 ahora se llama base1.
127
Con FILENAME podemos cambiar el nombre del fichero fsico, esto nos permite
tambin cambiar la ubicacin del archivo fsico.
Por ejemplo:
ALTER DATABASE MiBasedeDatos
MODIFY FILE(NAME = nbficherolgico,
FILENAME = 'nueva_ruta/nb_fichero_fsico')
La clusula OFFLINE establece el archivo sin conexin e impide el acceso a todos los
objetos del grupo de archivos. Muy importante!, esta opcin slo se debe de utilizar si el
archivo est daado y si se puede restaurar. Un archivo establecido en OFFLINE slo se
puede restablecer con conexin mediante la restauracin del archivo a partir de una copia
de seguridad. Para obtener ms informacin acerca de cmo restaurar un solo archivo,
consultar en la ayuda la sentencia RESTORE (Transact-SQL).
UNLIMITED especifica que el tamao del archivo aumenta hasta que el disco est
lleno. En SQL Server 2005, un archivo de registro especificado con un aumento ilimitado
tiene un tamao mximo de 2 TB y un archivo de datos tiene un tamao mximo de 16
TB.
En cuanto a la modificacin de la definicin de grupos, tenemos esta sintaxis:
<cambiar_grupos>::=
{
| ADD FILEGROUP nbgrupo
| REMOVE FILEGROUP nbgrupo
| MODIFY FILEGROUP nbgrupo
{
{ READONLY | READWRITE }
| { READ_ONLY | READ_WRITE }
}
| DEFAULT
| NAME = nuevo_ nbgrupo
}
}
Con ADD FILEGROUP nbgrupo aadimos un nuevo grupo de archivos de la base de
datos.
Con REMOVE FILEGROUP nbgrupo eliminamos el grupo de la base de datos.
El grupo de archivos no se puede quitar a menos que est vaco. Para quitar todos los
archivos del grupo, primero se mueven los archivos a otro grupo, si los archivos estn
vacos, se pueden eliminar directamente.
Con MODIFY FILEGROUP nbgrupo, modificamos el grupo de archivos.
DEFAULT Cambia el grupo de archivos predeterminado de la base de datos a nbgrupo.
NAME = nuevo_nbgrupo Cambia el nombre del grupo a nuevo_nbgrupo.
128
READ_ONLY | READONLY Especifica que el grupo de archivos es de slo lectura. En
este caso no se permitir la actualizacin de los objetos del mismo. Una base de datos de
slo lectura no permite realizar modificaciones en los datos por lo que:
Se omite la recuperacin automtica cuando se inicia el sistema.
No es posible reducir la base de datos.
No se produce ningn bloqueo en las bases de datos de slo lectura. Esto puede
acelerar el rendimiento de las consultas.
Para cambiar este estado, se debe tener acceso exclusivo a la base de datos.
El grupo de archivos principal no puede ser de slo lectura.
Se puede utilizar indistintamente la palabra clave READONLY o READ_ONLY, pero
READONLY se quitar en una versin futura de Microsoft SQL Server por lo que se
recomienda READ_ONLY.
READ_WRITE | READWRITE Especifica que el grupo es de lectura y escritura por lo
que pueden realizarse actualizaciones en los objetos del grupo de archivos.
Para cambiar este estado se debe tener acceso exclusivo a la base de datos.
Se puede utilizar indistintamente la palabra clave READWRITE o READ_ WRITE, pero
READWRITE se quitar en una versin futura de Microsoft SQL Server por lo que se
recomienda READ_WRITE.
Nota. El estado de estas opciones se puede determinar mediante el examen de la
columna is_read_only de la vista de catlogo sys.databases o la propiedad
Updateability de la funcin DATABASEPROPERTYEX.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (V)
Para finalizar tenemos el apartado <opciones> que nos permite definir y/o cambiar
muchas opciones de la base de datos. La lista de opciones es muy larga, como podemos
observar a continuacin, y no entraremos en detalles.
<opciones>::=
SET
{
{ <optionspec> [ ,...n ] [ WITH <termination> ] }
| ALLOW_SNAPSHOT_ISOLATION {ON | OFF }
| READ_COMMITTED_SNAPSHOT {ON | OFF } [ WITH
<termination> ]
}
<optionspec>::=
{
<db_state_option>
| <db_user_access_option>
| <db_update_option> | <external_access_option>
| <cursor_option>
129
| <auto_option>
| <sql_option>
| <recovery_option>
| <database_mirroring_option>
| <supplemental_logging_option>
| <service_broker_option>
| <date_correlation_optimization_option>
| <parameterization_option>
}
<db_state_option> ::=
{ ONLINE | OFFLINE | EMERGENCY }
<db_user_access_option> ::=
{ SINGLE_USER | RESTRICTED_USER | MULTI_USER }
<db_update_option> ::=
{ READ_ONLY | READ_WRITE }
<external_access_option> ::=
DB_CHAINING { ON | OFF }
| TRUSTWORTHY { ON | OFF }
}
<cursor_option> ::=
{ CURSOR_CLOSE_ON_COMMIT { ON | OFF }
| CURSOR_DEFAULT { LOCAL | GLOBAL }
}
<auto_option> ::=
{
AUTO_CLOSE { ON | OFF }
| AUTO_CREATE_STATISTICS { ON | OFF }
| AUTO_SHRINK { ON | OFF }
| AUTO_UPDATE_STATISTICS { ON | OFF }
| AUTO_UPDATE_STATISTICS_ASYNC { ON | OFF }
}
<sql_option> ::=
{
ANSI_NULL_DEFAULT { ON | OFF }
| ANSI_NULLS { ON | OFF }
| ANSI_PADDING { ON | OFF }
| ANSI_WARNINGS { ON | OFF }
130
| ARITHABORT { ON | OFF }
| CONCAT_NULL_YIELDS_NULL { ON | OFF }
| NUMERIC_ROUNDABORT { ON | OFF }
| QUOTED_IDENTIFIER { ON | OFF }
| RECURSIVE_TRIGGERS { ON | OFF }
}
<recovery_option> ::=
{
RECOVERY { FULL | BULK_LOGGED | SIMPLE }
| TORN_PAGE_DETECTION { ON | OFF }
| PAGE_VERIFY { CHECKSUM | TORN_PAGE_DETECTION | NONE }
}
< database_mirroring_option> ::=
{ <partner_option> | <witness_option> }
<partner_option> ::=
PARTNER { = 'partner_server'
| FAILOVER
| FORCE_SERVICE_ALLOW_DATA_LOSS
| OFF
| RESUME
| SAFETY { FULL | OFF }
| SUSPEND
| REDO_QUEUE ( integer { KB | MB | GB } |
UNLIMITED )
| TIMEOUT integer
}
<witness_option> ::=
WITNESS { = 'witness_server'
| OFF
}
<supplemental_logging_option> ::=
SUPPLEMENTAL_LOGGING { ON | OFF }
<service_broker_option> ::=
{
ENABLE_BROKER
| DISABLE_BROKER
| NEW_BROKER
131
| ERROR_BROKER_CONVERSATIONS
}
<date_correlation_optimization_option> ::=
{
DATE_CORRELATION_OPTIMIZATION { ON | OFF }
}
<parameterization_option> ::=
{
PARAMETERIZATION { SIMPLE | FORCED }
}
<termination> ::=
{
ROLLBACK AFTER integer [ SECONDS ]
| ROLLBACK IMMEDIATE
| NO_WAIT
}
Unidad 8. El DDL, Lenguaje de Definicin de Datos (V)
Para finalizar tenemos el apartado <opciones> que nos permite definir y/o cambiar
muchas opciones de la base de datos. La lista de opciones es muy larga, como podemos
observar a continuacin, y no entraremos en detalles.
<opciones>::=
SET
{
{ <optionspec> [ ,...n ] [ WITH <termination> ] }
| ALLOW_SNAPSHOT_ISOLATION {ON | OFF }
| READ_COMMITTED_SNAPSHOT {ON | OFF } [ WITH
<termination> ]
}
<optionspec>::=
{
<db_state_option>
| <db_user_access_option>
| <db_update_option> | <external_access_option>
| <cursor_option>
| <auto_option>
132
| <sql_option>
| <recovery_option>
| <database_mirroring_option>
| <supplemental_logging_option>
| <service_broker_option>
| <date_correlation_optimization_option>
| <parameterization_option>
}
<db_state_option> ::=
{ ONLINE | OFFLINE | EMERGENCY }
<db_user_access_option> ::=
{ SINGLE_USER | RESTRICTED_USER | MULTI_USER }
<db_update_option> ::=
{ READ_ONLY | READ_WRITE }
<external_access_option> ::=
DB_CHAINING { ON | OFF }
| TRUSTWORTHY { ON | OFF }
}
<cursor_option> ::=
{ CURSOR_CLOSE_ON_COMMIT { ON | OFF }
| CURSOR_DEFAULT { LOCAL | GLOBAL }
}
<auto_option> ::=
{
AUTO_CLOSE { ON | OFF }
| AUTO_CREATE_STATISTICS { ON | OFF }
| AUTO_SHRINK { ON | OFF }
| AUTO_UPDATE_STATISTICS { ON | OFF }
| AUTO_UPDATE_STATISTICS_ASYNC { ON | OFF }
}
<sql_option> ::=
{
ANSI_NULL_DEFAULT { ON | OFF }
| ANSI_NULLS { ON | OFF }
| ANSI_PADDING { ON | OFF }
| ANSI_WARNINGS { ON | OFF }
| ARITHABORT { ON | OFF }
133
| CONCAT_NULL_YIELDS_NULL { ON | OFF }
| NUMERIC_ROUNDABORT { ON | OFF }
| QUOTED_IDENTIFIER { ON | OFF }
| RECURSIVE_TRIGGERS { ON | OFF }
}
<recovery_option> ::=
{
RECOVERY { FULL | BULK_LOGGED | SIMPLE }
| TORN_PAGE_DETECTION { ON | OFF }
| PAGE_VERIFY { CHECKSUM | TORN_PAGE_DETECTION | NONE }
}
< database_mirroring_option> ::=
{ <partner_option> | <witness_option> }
<partner_option> ::=
PARTNER { = 'partner_server'
| FAILOVER
| FORCE_SERVICE_ALLOW_DATA_LOSS
| OFF
| RESUME
| SAFETY { FULL | OFF }
| SUSPEND
| REDO_QUEUE ( integer { KB | MB | GB } |
UNLIMITED )
| TIMEOUT integer
}
<witness_option> ::=
WITNESS { = 'witness_server'
| OFF
}
<supplemental_logging_option> ::=
SUPPLEMENTAL_LOGGING { ON | OFF }
<service_broker_option> ::=
{
ENABLE_BROKER
| DISABLE_BROKER
| NEW_BROKER
| ERROR_BROKER_CONVERSATIONS
134
}
<date_correlation_optimization_option> ::=
{
DATE_CORRELATION_OPTIMIZATION { ON | OFF }
}
<parameterization_option> ::=
{
PARAMETERIZATION { SIMPLE | FORCED }
}
<termination> ::=
{
ROLLBACK AFTER integer [ SECONDS ]
| ROLLBACK IMMEDIATE
| NO_WAIT
}
Se pueden ver ms detalles de estas opciones en la ayuda de SQL SERVER buscando
ALTER DABATABASE.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (VI)
8.5. Crear una tabla CREATE TABLE
Para crear una nueva tabla se emplea la sentencia CREATE TABLE.
Se necesita el permiso CREATE TABLE en la base de datos y el permiso ALTER en el
esquema en que se crea la tabla.
Si las columnas de la instruccin CREATE TABLE se definen como un tipo definido por
el usuario CLR, se necesita la propiedad del tipo o el permiso REFERENCES.
Si las columnas de la instruccin CREATE TABLE tienen una coleccin de esquemas
XML asociada, se necesita la propiedad de la coleccin de esquemas XML o el permiso
REFERENCES.
Empezaremos por una sintaxis reducida:
CREATE TABLE
[ nbBaseDatos.[nbEsquema].| nbEsquema.]nbTabla
( { <definicion_columna> | < definicion_colCalc > } [
,...n ]
[ <restriccion_tabla> ] [ ,...n ] )
[ ; ]
nbBaseDatos Es el nombre de la base de datos en la que se crea la tabla. Debe ser el
nombre de una base de datos existente. Si no se especifica nbBaseDatos, se utiliza de
135
manera predeterminada la base de datos actual. El inicio de sesin de la conexin actual
debe estar asociado a un Id. de usuario existente en la base de datos especificada por
nbBaseDatos, y ese Id. de usuario debe tener permisos CREATE TABLE.
nbEsquema Es el nombre del esquema al que pertenece la nueva tabla.
nbTabla Es el nombre de la nueva tabla. Los nombres de tablas deben seguir las reglas
de los identificadores. nbTabla puede contener un mximo de 128 caracteres excepto
para los nombres de tablas temporales locales (nombres precedidos por un nico signo de
nmero (#)) que no pueden superar los 116 caracteres.
Despus de indicar el nombre de la tabla, entre parntesis definimos, separadas por
una coma, cada una de las columnas de la tabla y al final las restricciones a nivel de tabla
si las hay.
Definir columnas fsicas
< definicion_columna > ::=
nbCol <tipo_dato>
[ COLLATE nbIntercalacion ]
[ NULL | NOT NULL ]
[
[ CONSTRAINT nbRestriccion ] DEFAULT exp_constante ]
| [ IDENTITY [( semilla, incremento )] [NOT FOR
REPLICATION] ]
]
[ ROWGUIDCOL ]
[ <restriccion_columna> [ ...n ] ]
Como mnimo debemos indicar el nombre de la columna nbCol y su tipo de datos.
Los nombres de columnas deben seguir las reglas de los identificadores y deben ser
nicos en la tabla. nbCol puede contener de 1 a 128 caracteres. nbCol se puede omitir en
las columnas creadas con un tipo de datos timestamp, en tal caso, si no se especifica
nbCol, el nombre de la columna timestamp ser de manera predeterminada timestamp.
En cuanto al tipo de dato, esta es la sintaxis:
<tipo_dato> ::=
[nbEsquema_tipo. ] nbtipo
[ ( precision [ , escala ] | max |
[ { CONTENT | DOCUMENT } ] xml_schema_collection )
]
[ nbEsquema_tipo. ] nbtipo
nbtipo Especifica el tipo de datos de la columna y nbEsquema_tipo el esquema al que
pertenece el tipo. El tipo de datos puede ser uno de los siguientes:
Un tipo de datos del sistema de SQL Server 2005 como los que ya conocemos.
Un tipo de alias basado en un tipo de datos del sistema de SQL Server. Los tipos de
datos de alias se crean con la instruccin CREATE TYPE para poder utilizarlos en
una definicin de tabla. La asignacin NULL o NOT NULL de un tipo de datos de
136
alias puede anularse durante la instruccin CREATE TABLE. No obstante, la
especificacin de longitud no se puede cambiar; la longitud del tipo de datos de alias
no se puede especificar en una instruccin CREATE TABLE.
Un tipo definido por el usuario CLR. Los tipos definidos por el usuario CLR se crean
con la instruccin CREATE TYPE para poder utilizarlos en una definicin de tabla.
Si no se especifica el parmetro nbEsquema_tipo, el SQL Server Database Engine
(Motor de base de datos de SQL Server) hace referencia a nbtipo en el siguiente orden:
El tipo de datos del sistema de SQL Server.
El esquema predeterminado del usuario actual en la base de datos actual.
El esquema de dbo de la base de datos actual.
Precision es la precisin del tipo de datos especificado.
Escala es la escala del tipo de datos especificado.
Max slo se aplica a los tipos de datos varchar, nvarchar y varbinary para almacenar
231 bytes de datos de caracteres y binarios, y 230 bytes de datos Unicode.
Tambin podemos definir tipos de datos XML.
Para obtener ms informacin acerca de los valores de precisin y de escala vlidos,
visita el siguiente avanzado.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (VII)
Una vez indicado el tipo de datos de la columna podemos opcionalmente completar su
definicin con una serie de clusulas.
[ COLLATE nbIntercalacion ]
Con la clusula COLLATE podemos definir el tipo de intercalacin que se utilizar para
la columna (Ver CREATE TABLE).
[ NULL | NOT NULL ]
Determina si se permiten valores nulos (NULL) en la columna o no (NOT NULL).
Realmente NULL no es estrictamente una restriccin, si no indicamos nada la columna
permitir valores nulos, pero se puede especificar de la misma forma que NOT NULL.
NOT NULL se puede especificar para las columnas calculadas slo si se especifica
tambin PERSISTED.
[ CONSTRAINT nbRestriccion ] DEFAULT exp_constante ]
Con la clusula DEFAULT podemos especificar un valor por defecto, es decir el valor
que tomar el campo cuando no se haya especificado explcitamente un valor durante la
insercin. Las definiciones DEFAULT se pueden aplicar a cualquier columna excepto a las
definidas como timestamp o a aquellas que tengan la propiedad IDENTITY. Si se
especifica un valor por defecto a una columna de un tipo definido por el usuario, dicho tipo
debe ser compatible con la conversin implcita de exp_constante en el tipo definido por el
usuario. exp_constante slo puede ser NULL o un valor constante (por ejemplo, una
137
cadena de caracteres, una funcin escalar o una funcin del sistema, definida por el
usuario o CLR).
Para mantener la compatibilidad con las versiones anteriores de SQL Server, se puede
asignar un nombre de restriccin a DEFAULT con [ CONSTRAINT nbRestriccion ]. Los
nombres de restriccin deben ser nicos en el esquema al que pertenece la tabla.
[ IDENTITY [( semilla, incremento )] [NOT FOR REPLICATION] ]
IDENTITY indica que la nueva columna es una columna de identidad. Cuando se
agrega una nueva fila a la tabla, el Motor de base de datos proporciona un valor
incremental nico para la columna. Las columnas de identidad se utilizan normalmente
como claves principales.
La propiedad IDENTITY se puede asignar a las columnas tinyint, smallint, int, bigint,
decimal(p,0) o numeric(p,0). Slo se puede crear una columna de identidad para cada
tabla. Las restricciones DEFAULT y los valores predeterminados enlazados no se pueden
utilizar en las columnas de identidad. En este caso, deben especificarse el valor de
inicializacin y el incremento, o ninguno de esto valores. Si no se especifica ninguno, el
valor predeterminado es (1,1).
semilla es el valor que se utiliza para la primera fila cargada en la tabla.
Incremento es el valor incremental que se agrega al valor de identidad de la fila cargada
anterior.
De forma general, si se especifica la clusula NOT FOR REPLICATION para una
restriccin, dicha restriccin no se impone cuando los agentes de rplica realizan
operaciones de insercin, actualizacin o eliminacin. Si se especifica esta clusula, junto
con IDENTITY, los valores no se incrementan en las columnas de identidad cuando los
agentes de rplica realizan inserciones.
[ ROWGUIDCOL ]
ROWGUIDCOL indica que la nueva columna es una columna de GUID de filas. Slo se
puede designar una columna uniqueidentifier por tabla como columna ROWGUIDCOL.
La propiedad ROWGUIDCOL se puede asignar nicamente a una columna
uniqueidentifier.
Las columnas de tipos de datos definidos por el usuario no se pueden designar con
ROWGUIDCOL.
La propiedad ROWGUIDCOL no impone la unicidad de los valores almacenados en la
columna. ROWGUIDCOL tampoco genera automticamente valores para nuevas filas
insertadas en la tabla, por lo que se debe de utilizar la funcin NEWID en las instrucciones
INSERT o utilizar la funcin NEWID como el valor predeterminado de la columna para
generar valores nicos en cada fila.
Para ver ms consideraciones sobre columnas IDENTITY y ROWGUIDCOL.
Por ltimo nos quedan las restricciones de clave que aparecen en la sintaxis como:
[ <restriccion_columna> [ ...n ] ]
< restriccion_columna > ::=
[ CONSTRAINT nbRestriccion]
{ { PRIMARY KEY | UNIQUE }[ CLUSTERED | NONCLUSTERED ]
[ WITH FILLFACTOR = factorRelleno
| WITH ( < opcion_indice > [ , ...n ] )
138
]
[ ON { partition_scheme_name ( partition_column_name
)
| filegroup | "default" } ]
| [ FOREIGN KEY ]
REFERENCES [ nbEsquema.] nbTablaPadre [ ( col_padre
) ]
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET
DEFAULT } ]
}
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET
DEFAULT } ]
[ NOT FOR REPLICATION ]
| CHECK [ NOT FOR REPLICATION ] (expresion_validacion)
nbRestriccion es el nombre de la restriccin, como hemos visto antes, debe ser nico
en el esquema al que pertenece la tabla. Las restricciones se implementan internamente
con ndices por lo que a veces podemos utilizar el trmino ndice o restriccin
indistintamente.
{PRIMARY KEY | UNIQUE} [ CLUSTERED | NONCLUSTERED ]
PRIMARY KEY indica que la columna es la clave principal de la tabla. Slo se puede
crear una restriccin PRIMARY KEY para cada tabla. Si la clave primaria (principal) est
compuesta por varias columnas entonces no podemos utilizar esta restriccin, tendremos
que utilizar una restriccin de tabla que veremos ms adelante.
CLUSTERED indica que el ndice que se va a crear es un ndice agrupado. Como slo
puede haber un ndice agrupado por tabla, si todava no hay ninguno definido, por defecto
se crear con la clave primaria, si ya existe un ndice agrupado, la clave principal se
crear sin ndice agrupado.
Una clave primaria no puede contener valores nulos, por lo que todas las columnas
definidas en una restriccin PRIMARY KEY se deben definir como NOT NULL. Si cuando
definimos la columna, no se indica nada, la columna se establecer a NOT NULL.
Si la clave principal se define en una columna de tipo definido por el usuario CLR, la
implementacin del tipo debe admitir el orden binario.
UNIQUE indica que la columna no admite valores duplicados, por lo que se crea un
ndice nico. Una tabla puede tener varios ndices nicos.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (VIII)
Si no se especifica CLUSTERED o NONCLUSTERED, de forma predeterminada se
utiliza NONCLUSTERED.
Como cada restriccin UNIQUE genera un ndice. El nmero de restricciones UNIQUE
no puede hacer que el nmero de ndices de la tabla exceda de 249 ndices no agrupados
y 1 ndice agrupado.
139
Si se define una restriccin UNIQUE en una columna de tipo definido por el usuario
CLR, la implementacin del tipo debe admitir el orden binario o basado en el operador.
Las dems opciones de ndices:
[ WITH FILLFACTOR = factorRelleno
| WITH ( < opcion_indice > [ , ...n ] ) ]
< opcion_indice > ::=
{
PAD_INDEX = { ON | OFF }
| FILLFACTOR = factorRelleno
| IGNORE_DUP_KEY = { ON | OFF }
| STATISTICS_NORECOMPUTE = { ON | OFF }
| ALLOW_ROW_LOCKS = { ON | OFF}
| ALLOW_PAGE_LOCKS ={ ON | OFF}
}
Son clusulas que nos permiten definir con ms detalle el ndice pero que no veremos
aqu por entrar demasiado en cuestiones internas.
La clusula CHECK.
CHECK [ NOT FOR REPLICATION ] ( expresion_validacion )
Con CHECK indicamos una regla de validacin que debern cumplir todas las filas de la
tabla, es una restriccin que exige la integridad del dominio al limitar los valores posibles
que se pueden escribir en la columna.
expression es una expresin lgica que devuelve TRUE o FALSE.
Si queremos definir una restriccin CHECK sobre una columna calculada, esta se deber
definir como PERSISTED.
Una columna puede tener cualquier nmero de restricciones CHECK y la condicin
puede incluir varias expresiones lgicas combinadas con AND y OR. Varias restricciones
CHECK para una columna se validan en el orden en que se crean.
La condicin de bsqueda debe evaluarse como una expresin booleana y no puede
hacer referencia a otra tabla.
Una restriccin CHECK en el nivel de columna slo puede hacer referencia a la
columna restringida y una restriccin CHECK en el nivel de tabla slo puede hacer
referencia a columnas de la misma tabla.
Las restricciones CHECK no se pueden definir en las columnas text, ntext o image.
Por ejemplo queremos que la columna Precio de la tabla que estamos definiendo no
pueda contener valores negativos:
Precio CURRENCY CONSTRAINT precio_pos CHECK (Precio > = 0)
140
Por ltimo a nivel de columna podemos definir una restriccin de clave ajena:
[ FOREIGN KEY ]
REFERENCES [ nbEsquema.] nbTablaPadre [ ( col_padre )
]
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET
DEFAULT } ]
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET
DEFAULT } ]
[ NOT FOR REPLICATION ]
Con esta clusula definimos una regla de integridad referencial, los valores contenidos
en la columna debern apuntar a un registro en la tabla de referencia (la tabla padre).
La palabra FOREIGN KEY no es obligatoria cuando estamos a nivel de columna, el
utilizarla o no tiene el mismo efecto.
Nbesquema es el nombre del esquema al que pertenece la tabla padre y nbTablaPadre
es el nombre de la tabla padre.
Col_padre es la columna de la tabla padre que se relaciona con la columna que
estamos definiendo. Esta columna debe tener el mismo tipo de datos que la columna en la
que se define la restriccin.
La col_padre debe tener en la tabla padre una restriccin de PRIMARY KEY o UNIQUE,
si no se indica una columna padre (columna de referencia) se utiliza la clave primaria de la
tabla padre.
Las reglas de integridad referencial obligan a que si se especifica un valor distinto de
NULL en una columna con una restriccin FOREIGN KEY, ese valor debe existir en la
columna referenciada de la tabla padre; de lo contrario, se devolver un error de infraccin
de clave externa.
Las restricciones FOREIGN KEY slo pueden hacer referencia a las tablas de la misma
base de datos en el mismo servidor. La integridad referencial entre bases de datos debe
implementarse a travs de desencadenadores.
Las restricciones FOREIGN KEY pueden hacer referencia a otras columnas de la
misma tabla. Esto se denomina autorreferencia.
create table personas (codigo integer primary Key,
dni integer UNIQUE,
madre integer references personas,
padre integer references personas (col1),
dniTutor integer references personas (col4));
En esta tabla de personas, identificamos a cada persona por un cdigo, tambin
tenemos el dni de la persona y el cdigo de su padre y de su madre, adems nos
guardamos el dni del tutor de la persona. Las madres, padres y tutores son personas que
deben de existir en la tabla Personas y en este caso utilizamos el cdigo para referenciar
141
padres y madres y el dni para referencial el tutor, esto ltimo lo podemos hacer porque el
campo dni tiene una restriccin UNIQUE.
Por ltimo nos queda completar las reglas de integridad referencial en cuanto a qu
hacer cuando se eliminan o modifican valores que intervienen en una relacin referencial.
ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Indica qu ocurre cuando se intenta eliminar un registro padre en la relacin que
estamos definiendo. El valor predeterminado es NO ACTION.
NO ACTION El Motor de base de datos genera un error y no es posible eliminar la fila
de la tabla primaria (el padre).
CASCADE Si se borra una fila de la tabla primaria, se eliminan automticamente todas
las filas correspondientes de la tabla que estamos definiendo, en otras palabras, si se
elimina un padre, se eliminan todos sus hijos.
SET NULL Si se borra una fila de la tabla primaria, todas las filas correspondientes de
la tabla que estamos definiendo tomarn el valor NULL en el campo clave ajena. En otras
palabras, si se elimina un padre, sus hijos se quedan sin padre.
Para ejecutar esta restriccin, la columna clave ajena debe admitir valores NULL.
SET DEFAULT Es como la anterior pero en vez del valor NULL toman el valor que tienen
predeterminado. Si no hay ningn valor predeterminado establecido de forma explcita,
tomarn el valor NULL. Hay que tener en cuenta que el valor predeterminado debe de
existir en la tabla primaria.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (IX)
Veamos estas opciones con un ejemplo:
Tenemos una tabla Proveedores y una tabla artculos, en la tabla artculos nos
guardamos el cdigo del proveedor del artculo, por lo tanto definiremos la tabla artculos
de la siguiente forma:
CREATE TABLE articulos (
Codigo INTEGER PRIMARY KEY,
Denominacion VARCHAR(30),
.,
Proveedor INTEGER REFERENCES Proveedores,
)
El campo Proveedor es clave ajena y hace referencia a un cdigo de proveedor de la
tabla Proveedores.
Aqu no hemos aadido ninguna clusula ON DELETE por lo que se toma NO ACTION.
.,
Proveedor INTEGER REFERENCES Proveedores ON DELETE NO
ACTION,
)
142
Estas dos sentencias son equivalentes e indican que si se intenta borrar de la tabla
Proveedores un proveedor asignado a un artculo, el sistema da un error y no deja
eliminar el proveedor.
.,
Proveedor INTEGER REFERENCES Proveedores ON DELETE CASCADE,
)
Se eliminar el proveedor y todos los artculos asignados a l.
.,
Proveedor INTEGER REFERENCES Proveedores ON DELETE SET NULL,
)
Se eliminar el proveedor de la tabla Proveedores y en la tabla Artculos, todas las filas
que tenan ese nmero de proveedor pasarn a tener el valor nulo en el campo proveedor.
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Indica qu ocurre cuando se intenta cambiar un valor del campo relacionado de la tabla
padre en la relacin que estamos definiendo. El valor predeterminado es NO ACTION.
Las opciones son las mismas que para ON DELETE.
NO ACTION El Motor de base de datos genera un error y no es posible modificar la fila
de la tabla primaria (el padre).
CASCADE Si se modifica un valor de la columna padre en la tabla primaria, se
modificarn automticamente todas las filas correspondientes de la tabla que estamos
definiendo, en otras palabras, si se modifica el identificativo de un padre, se actualizan
todos sus hijos.
SET NULL Si se modifica un valor de la columna padre en la tabla primaria, todas las
filas correspondientes de la tabla que estamos definiendo tomarn el valor NULL en el
campo clave ajena. En otras palabras, si se modifica el identificativo de un padre, sus hijos
se quedan sin padre.
Para ejecutar esta restriccin, la columna clave ajena debe admitir valores NULL.
SET DEFAULT Es como la anterior pero en vez del valor NULL toman el valor que tienen
predeterminado. Si no hay ningn valor predeterminado establecido de forma explcita,
tomarn el valor NULL. Hay que tener en cuenta que el valor predeterminado debe de
existir en la tabla primaria.
Volviendo al ejemplo anterior:
.,
Proveedor INTEGER REFERENCES Proveedores ON UPDATE NO
ACTION,
)
143
Si cambiamos el cdigo del proveedor 3 a 3000 y hay artculos asignados al proveedor
3, el sistema da un error y no deja modificar el proveedor.
.,
Proveedor INTEGER REFERENCES Proveedores ON UPDATE CASCADE,
)
Se modifica el proveedor y todos los artculos asignados a l pasan a tener el valor
3000 en el campo Proveedor.
.,
Proveedor INTEGER REFERENCES Proveedores ON UPDATE SET
NULL,
)
Se modifica el proveedor y todos los artculos asignados a l pasan a tener el valor
NULL en el campo Proveedor.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (X)
Definir restricciones de tabla
Hasta el momento hemos aprendido a definir restricciones sobre una columna, mientras
la estamos definiendo aadimos a su definicin la restriccin o restricciones que
queramos.
Tambin existen restricciones de tabla, son restricciones que se definen despus de
definir todas las columnas de la tabla y que pueden afectar a una o varias columnas de la
tabla. Como veremos la sintaxis para definir una restriccin de tabla es muy parecida a la
sintaxis de la misma restriccin de columna, lo que vara es que ahora tenemos que
indicar las columnas afectadas por la restriccin.
< restriccion_tabla > ::=
[ CONSTRAINT nbRestriccion]
{
{PRIMARY KEY | UNIQUE } [ CLUSTERED | NONCLUSTERED ]
(nbCol[ASC|DESC][ ,...n ] )
[ WITH FILLFACTOR = factorRelleno
|WITH ( < opcion_indice > [ , ...n ] )
]
[ ON { partition_scheme_name (partition_column_name)
| filegroup | "default" } ]
|
FOREIGN KEY(nbCol[,...n])REFERENCES nbTablaPadre
144
[(col_padre)[,...n] )]
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET
DEFAULT } ]
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET
DEFAULT } ]
[ NOT FOR REPLICATION ]
| CHECK [NOT FOR REPLICATION] (expresion_validacion )
}
Como las clusulas son las mismas que para las restricciones de columna, no
repetiremos la explicacin de cada clusula, lo que veremos es un ejemplo y la
explicacin de ese ejemplo.
Volviendo al ejemplo anterior de la tabla de Personas, podemos definir la misma
utilizando restricciones de tabla:
CREATE TABLE personas (
codigo int,
dni int,
madre int,
padre int,
dniTutor int,
PRIMARY KEY (codigo),
UNIQUE (dni),
FOREIGN KEY (madre) REFERENCES Personas,
FOREIGN KEY (padre) REFERENCES Personas (codigo),
FOREIGN KEY (dniTutor) REFERENCES Personas (dni));
Tambin podamos haber mezclado restricciones de columna con restricciones de
tabla, lo que no podemos hacer es definir dos veces la misma restriccin, o la definimos a
nivel de columna o a nivel de tabla pero no dos veces!
Utilizando la restricciones de tabla parece que la definicin queda ms clara, por un
lado tenemos la definicin de cada columna, y luego las restricciones.
Las restricciones de tabla se hacen imprescindibles cuando la restriccin afecta a una
combinacin de columnas. Por ejemplo imaginemos una tabla de productos en la que la
clave principal est formada por el cdigo de fabricante y cdigo de producto (porque dos
productos diferentes pueden tener el mismo cdigo de producto con proveedores
diferentes).
No podemos definir la clave de esta manera:
CREATE TABLE Productos (
Codproducto int PRIMARY KEY,
Codproveedor int PRIMARY KEY,
145
El Motor de la base de datos entendera que queremos definir dos claves primarias y
eso es imposible. En este caso habra que utilizar una restriccin de tabla:
CREATE TABLE Productos (
Codproducto int,
Codproveedor int,
las dems columnas,
PRIMARY KEY (Codproducto, Codproveedor));
Ocurre lo mismo con las dems restricciones. Imaginemos ahora una tabla de lneas de
pedido en la que tenemos en una lnea el producto pedido, y la cantidad pedida.
CREATE TABLE LineasPed (
pedido INT,
nlin INT,
codprod INT,
codprov INT,
cantidad INT,
PRIMARY KEY (pedido, nlin),
FOREIGN KEY (codprod,codprov) REFERENCES Productos,
UNIQUE (pedido,codprod,codprov));
La combinacin (codprod,codprov) forma una clave ajena que hace referencia a la tabla
Productos, en este caso como la clave principal de la tabla Productos est compuesta por
los dos campos, la clave ajena tiene que tener el mismo nmero de campo y del mismo
tipo.
Con la restriccin UNIQUE indicamos que la combinacin formada por un nmero de
pedido un cdigo de producto y cdigo de proveedor no se puede repetir, esto hace que
no se puedan insertar en un mismo pedido dos lneas del mismo producto. No se puede
duplicar la combinacin pero s las columnas individualmente (pueden haber varias filas
con el mismo nmero de pedido, varias filas con el mismo cdigo de producto y varias filas
con el mismo codigo de proveedor.
Aqu termina la explicacin de la sintaxis bsica de las instrucciones CREATE TABLE.
Nos queda hablar de las columnas calculadas y de las tablas temporales, otras clusulas
de la instruccin se pueden consultar en la ayuda de la instruccin SQL CREATE TABLE.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (XI)
Definir columnas calculadas.
Una columna calculada es una columna cuyo valor no se introduce, sino que se obtiene
como resultado de un clculo.
146
< definicion_columna > ::=
nbCol AS expresion
[ PERSISTED
[NOT NULL]
[ <restriccion_columna> [...n ] ]
]
expresion es la expresin que define el valor de una columna calculada y est basada
en otras columnas de la tabla.
Por ejemplo, una columna calculada puede ser definida as:
importe AS precio * cantidad
La expresin puede ser un nombre de columna no calculada, una constante, una
funcin, una variable o cualquier combinacin de estos elementos conectados mediante
uno o ms operadores. La expresin no puede ser una subconsulta ni contener tipos de
datos de alias.
Una columna calculada es, por defecto, una columna virtual no almacenada fsicamente
en la tabla. PERSISTED indica que la columna calculada se almacena en la tabla y
automticamente se actualizan los valores almacenados en ella cuando se actualizan las
columnas de las que depende.
Para que la columna pueda ser definida con PERSISTED la expresin que la calcula
debe ser determinista. Una expresin es determinista a menos que utilice una funcin no
determinista.
Una columna calculada se puede utilizar en la lista de seleccin, clusula WHERE,
clusula ORDER BY u otras ubicaciones en que se puedan utilizar expresiones regulares,
con las siguientes excepciones:
Una columna calculada no puede utilizarse como definicin de restriccin DEFAULT
o FOREIGN KEY ni como NOT NULL.
Una columna calculada no puede ser el destino de una instruccin INSERT o
UPDATE. No tiene sentido querer asignar un determinado
Definir tablas temporales
Una tabla temporal es una tabla creada por un determinado proceso y desaparece
cuando termina ste.
Se pueden crear tablas temporales locales y globales. Las tablas temporales locales
son visibles slo en la sesin actual y las tablas temporales globales son visibles para
todas las sesiones.
Para indicar que la tabla que queremos crear es temporal aadimos a su nombre el
prefijo # (#nbTabla) para tablas temporales locales y el prefijo ## (##nbTabla) tablas
temporales globales.
Por ejemplo:
147
CREATE TABLE #trabajo (col1 INT PRIMARY KEY);
Esta instruccin crea una tabla temporal local llamada trabajo con una sola columna.
Las tablas temporales funcionan casi como las tablas normales con algunas diferencias.
No se pueden crear particiones en las tablas temporales.
nbTabla no puede tener ms de 116 caracteres. Esto se debe a que si se crea una
tabla temporal local en un procedimiento almacenado o una aplicacin que varios usuarios
pueden ejecutar al mismo tiempo, el Motor de base de datos tiene que ser capaz de
distinguir las tablas creadas por los distintos usuarios, lo consigue aadiendo
internamente un sufijo numrico a cada nombre de tabla temporal local. El nombre
completo de una tabla temporal tal como se almacena en la tabla sysobjects de tempdb
consta del nombre de la tabla especificado en la instruccin CREATE TABLE y el sufijo
numrico generado por el sistema.
Las tablas temporales se quitan automticamente cuando estn fuera de mbito, a
menos que ya se hayan quitado explcitamente mediante DROP TABLE:
Una tabla temporal local creada en un procedimiento almacenado se quita
automticamente cuando se completa el procedimiento almacenado. Cualquiera de los
procedimientos almacenados anidados ejecutados por el procedimiento almacenado que
cre la tabla, puede hacer referencia a la tabla. El proceso que llam al procedimiento
almacenado que cre la tabla no puede hacer referencia a la tabla.
Las tablas temporales se quitan automticamente al final de la sesin actual.
Las tablas temporales globales se quitan automticamente cuando la sesin que cre la
tabla finaliza y las tareas restantes han dejado de hacer referencia a ellas. La asociacin
entre una tarea y una tabla se mantiene slo durante la vida de una nica instruccin
Transact-SQL. Esto significa que la tabla temporal global se quita al finalizar la ltima
instruccin Transact-SQL que estuviera haciendo referencia activamente a la tabla cuando
finaliz la sesin que la cre.
Una tabla temporal local creada en un procedimiento almacenado o desencadenador,
puede tener el mismo nombre que una tabla temporal creada antes de que se llame al
procedimiento almacenado o al desencadenador. No obstante, si una consulta hace
referencia a una tabla temporal y hay dos tablas temporales con el mismo nombre, no est
definido en cul de las dos tablas debe resolverse la consulta. Los procedimientos
almacenados anidados pueden crear tambin tablas temporales con el mismo nombre que
la tabla temporal creada por el procedimiento almacenado que la llam. Sin embargo, en
el caso de las modificaciones que se van a resolver en la tabla creada en el procedimiento
anidado, la tabla debe tener la misma estructura, con los mismos nombres de columnas,
que la tabla creada en el procedimiento que realiza la llamada. Esto se muestra en el
ejemplo siguiente.
Con tablas temporales globales o locales, la sintaxis CREATE TABLE admite la
definicin de restricciones, excepto las restricciones FOREIGN KEY. Si se especifica una
restriccin FOREIGN KEY en una tabla temporal, la instruccin devuelve un mensaje de
advertencia que indica que la restriccin se ha omitido. La tabla se crea sin las
restricciones FOREIGN KEY. En las restricciones FOREIGN KEY no se puede hacer
referencia a tablas temporales.
Se recomienda utilizar variables de tabla en lugar de tablas temporales. Las tablas
temporales son tiles cuando es necesario crear en ellas ndices de forma explcita o bien
cuando los valores de tabla deben ser visibles en varios procedimientos almacenados o
funciones. En general, las variables de tabla contribuyen a que el procesamiento de las
consultas sea ms eficaz.
148
Unidad 8. El DDL, Lenguaje de Definicin de Datos (XII)
8.6. Eliminar una tabla DROP TABLE
Para eliminar una tabla de una base de datos tenemos la sentencia DROP TABLE. Con
ella quitamos una o varias definiciones de tabla y todos los datos, ndices,
desencadenadores, restricciones y especificaciones de permisos que tengan esas tablas.
Las vistas o procedimientos almacenados que hagan referencia a la tabla quitada se
deben quitar explcitamente con DROP VIEW o DROP PROCEDURE.
Su sintaxis es:
DROP TABLE [nbBaseDatos.[nbEsquema].|nbEsquema.]nbTabla[ ,...n
] [ ; ]
Para que las reglas de integridad referencial se cumplan, no se puede eliminar una
tabla sealada por una restriccin FOREIGN KEY. Primero se debe quitar la restriccin
FOREIGN KEY o la tabla que tiene la clave ajena.
Se pueden quitar varias tablas de cualquier base de datos en una misma sentencia
DROP TABLE. Se irn eliminando en el mismo orden en que aparecen en la lista por lo
que podremos eliminar dos tablas relacionadas con una sola sentencia pero escribiendo la
tabla que contiene la clave ajena primero y despus la tabla principal.
Requiere el permiso CONTROL en la tabla o pertenecer a la funcin fija de base de
datos db_ddladmin.
Ejemplo:
DROP TABLE mitabla;
Elimina la tabla miTabla tanto su definicin como los datos, ndices definidos sobre ella
y permisos.
8.7. Modificar la definicin de una tabla ALTER TABLE
ALTER TABLE [nbBaseDatos.[nbEsquema].| nbEsquema.]nbTabla
{ ALTER COLUMN nbColumna
{
<tipo_dato>
[ NULL | NOT NULL ]
[ COLLATE nbIntercalacion ]
| {ADD | DROP } { ROWGUIDCOL | PERSISTED }
}
| [WITH{ CHECK | NOCHECK}] ADD
{
<definicion_columna>
| <definicion_colCalc>
149
| <restriccion_tabla>
} [ ,...n ]
| DROP
{
[CONSTRAINT] nbRestriccion
|COLUMN nbColumna
} [,...n ]
| {CHECK|NOCHECK} CONSTRAINT {ALL|nbRestriccion[ ,...n ]}
| {ENABLE|DISABLE} TRIGGER {ALL | nbTrigger [ ,...n ] }
}
[ ; ]
Aunque la sintaxis parece un poco complicada, realmente no lo es. La sentencia nos
permite variar la definicin de una tabla ya creada, en qu consiste esta variacin:
modificar la definicin de columnas ya existentes (ALTER COLUMN), aadir ms
columnas o restricciones (ADD), eliminar columnas y restricciones (DROP),
habilitar/deshabilitar restricciones (CHECK CONSTRAINT) y habilitar/deshabilitar triggers.
Como muchas de las clusulas las hemos estudiado con CREATE TABBLE, slo
incidiremos en lo nuevo.
Para modificar una columna escribiremos la clusula ALTER COLUMN seguida del
nombre de la columna que queremos modificar y la nueva definicin, podemos cambiar su
tipo de datos indicando uno nuevo, hacer que la columna acepte o no valores nulos
(NULL|NOTNULL), cambiar la intercalacin (COLLATE).
Con ADD ROWGUIDCOL hacemos que la columna sea GUID de filas y DROP
ROWGUIDCOL hacemos que ya no lo sea.
Si la columna es una columna calculada podemos cambiar su condicin de columna
almacenada con ADD/DROP PERSISTED.
Ejemplo:
ALTER TABLE Clientes ALTER COLUMN direccion VARCHAR(40);
Hace que la columna direccion de la tabla Clientes, ahora admita 40 caracteres
alfanumricos.
Cuando cambiamos el tipo de una columna hay que tener en cuenta que el nuevo tipo
debe ser compatible con el antiguo para que no se pierdan los datos almacenados.
Adems la columna no se puede modificar si es ROWGUIDCOL, calculada o si se utiliza
en una columna calculada, si se utiliza en un ndice (a menos que la columna sea del tipo
de datos varchar, nvarchar o varbinary, el tipo de datos no se cambie y el nuevo tamao
sea igual al tamao anterior o mayor que ste), si se utiliza en estadsticas, en una
restriccin PRIMARY KEY, FOREIGN KEY, CHECK o UNIQUE. Sin embargo, se permite
el cambio de longitud de una columna de longitud variable en una restriccin CHECK o
UNIQUE.
150
Unidad 8. El DDL, Lenguaje de Definicin de Datos (XIII)
Para aadir una nueva columna o restriccin utilizamos la clusula ADD seguida de la
definicin de lo que queremos aadir, para eso seguimos la misma sintaxis que para
definir las columnas y restricciones de tabla del CREATE TABLE.
Por ejemplo:
ALTER TABLE Clientes ADD email varchar(50);
Aade una nueva columna email.
ALTER TABLE Clientes ADD CONSTRAINT Pk PRIMARY KEY (codcli);
Aade una restriccin de clave primaria sobre la columna codcli que ya existe en la
tabla.
La clusula WITH CHECK|NOCHECK permite establecer si la restriccin que estamos
aadiendo se tiene que comprobar en las filas que ya existen en la tabla.
Con la clusula DROP podemos eliminar de la tabla una restriccin (DROP
CONSTRAINT), o una columna (DROP COLUMN).
Con las siguientes limitaciones:
Una restriccin PRIMARY KEY no puede quitarse si existe un ndice XML en la tabla.
Una columna no puede quitarse si se utiliza en un ndice, en una restriccin CHECK,
FOREIGN KEY, UNIQUE o PRIMARY KEY, DEFAULT.
Ejemplo:
ALTER TABLE Clientes DROP COLUMN email;
Elimina de la tabla Clientes la columna email que habamos creado anteriormente.
ALTER TABLE Clientes DROP CONSTRAINT pk ;
Elimina de la tabla Clientes la restriccin de PRIMARY KEY, la columna sigue en la
tabla pero ya no es clave principal.
Para finalizar, las dos ltimas clusulas nos permiten indicar si se tienen que comprobar
o no determinadas restricciones y habilitar y deshabilitar triggers.
CHECK CONSTRAINT ALL activa la comprobacin de todas las restricciones definidas
sobre la tabla.
DISABLE TRIGGER ALL deshabilita todos los triggers definidos sobre la tabla.
Cuando deshabilitamos un trigger, ste sigue definido, pero no entra en accin cuando se
produce el evento que debera activarlo. En cualquier momento lo podremos habilitar con
otra instruccin ALTER TABLE.
8.8. Crear una vista CREATE VIEW
Una vista es una tabla virtual que representa los datos de una o ms tablas de una
forma alternativa. Para crear una nueva vista se emplea la sentencia CREATE VIEW,
debe ser la primera instruccin en un lote de consultas.
151
Una vista slo se puede crear en la base de datos actual.
Para ejecutar CREATE VIEW, se necesita, como mnimo, el permiso CREATE VIEW
en la base de datos y el permiso ALTER en el esquema en el que se est creando la vista.
Sintaxis:
CREATE VIEW [nbEsquema.] nbVista
[ (columna [ ,...n ] ) ]
AS ( sentencia_select ) [ ; ]
nbEsquema Es el nombre del esquema al que pertenece la nueva tabla.
nbVista Es el nombre de la nueva vista. Los nombres de vistas deben seguir las reglas
de los identificadores.
sentencia_select Es la instruccin SELECT que define la vista. Dicha instruccin puede
utilizar ms de una tabla y otras vistas. Se necesitan permisos adecuados para
seleccionar los objetos a los que se hace referencia en la clusula SELECT de la vista que
se ha creado.
Una vista no tiene por qu ser un simple subconjunto de filas y de columnas de una
tabla determinada. Es posible crear una vista que utilice ms de una tabla u otras vistas
mediante una clusula SELECT de cualquier complejidad.
Tambin se pueden utilizar funciones y varias instrucciones SELECT separadas por
UNION o UNION ALL.
Una vista puede tener como mximo 1.024 columnas.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (XIV)
Ejemplos:
CREATE VIEW oficinas_este
AS SELECT * FROM oficinas WHERE region = Este;
Crea una vista con las oficinas del este.
CREATE VIEW oficinas_empleados
AS
SELECT oficinas.oficina AS ofi, ciudad, dir, region,
objetivo, oficinas.ventas AS ventas_ofi, empleados.*
FROM oficinas INNER JOIN empleados
ON oficinas.oficina = empleados.oficina;
Crea una vista con los datos de todos los empleados y de sus oficinas.
En este caso hemos tenido que definir alias de campo porque en el origen de la sentencia
SELECT existe duplicidad de nombres.
152
CREATE VIEW oficinas_EO
AS
SELECT * FROM oficinas WHERE region = Este;
UNION ALL
SELECT * FROM oficinas WHERE region = Oeste;
Por defecto las columnas de la vista heredan los nombres de las columnas de la
sentencia SELECT asociada, pero podemos cambiar estos nombres indicando una lista
de columnas despus del nombre de la vista.
CREATE VIEW oficinas_este (Eoficina, Eciudad, Eregion, Edir,
Eobjetivo,Eventas)
AS SELECT * FROM oficinas WHERE region = Este;
Utilizando una lista de columnas ya no tenemos que definir alias de columna en la
sentencia SELECT como pasaba en el caso de la vista oficinas_empleados.
Normalmente se utiliza la lista de columnas cuando una columna proviene de una
expresin aritmtica, una funcin o una constante; cuando dos o ms columnas puedan
tener el mismo nombre, normalmente debido a una combinacin; o cuando una columna
de una vista recibe un nombre distinto al de la columna de la que proviene.
En definitiva se puede optar por utilizar la lista de columnas o definir alias de campo en
la sentencia SELECT.
Cuando utilizamos una vista en una operacin de actualizacin (INSERT, UPDATE,
DELETE), la vista debe ser actualizable, para ello debe seguir las siguientes reglas:
Cualquier modificacin, incluida en las instrucciones UPDATE, INSERT y DELETE,
debe hacer referencia a las columnas de una nica tabla base.
Las columnas que se vayan a modificar en la vista deben hacer referencia directa a los
datos subyacentes de las columnas de la tabla, es decir que las columnas no se pueden
obtener de otra forma, como con una funcin de agregado: AVG, COUNT, SUM, MIN,
MAX, GROUPING, STDEV, STDEVP, VAR y VARP, o un clculo.
Las columnas formadas mediante los operadores de conjunto UNION, UNION ALL,
CROSSJOIN, EXCEPT e INTERSECT equivalen a un clculo y tampoco son
actualizables.
Las columnas que se van a modificar no se ven afectadas por las clusulas GROUP
BY, HAVING o DISTINCT.
Las restricciones anteriores se aplican a cualquier subconsulta de la clusula FROM de
la vista, al igual que a la propia vista. Normalmente, el Database Engine (Motor de base
de datos) debe poder realizar un seguimiento sin ambigedades de las modificaciones de
la definicin de la vista a una tabla base.
8.9. Eliminar una vista DROP VIEW
Para eliminar una vista de una base de datos tenemos la sentencia DROP TABLE.
Sintaxis:
153
DROP VIEW [nbEsquema.]nbVista[ ,...n ] [ ; ]
Se eliminan las vista de la base de datos actual. Cuando eliminamos una vista
eliminamos su definicin y los permisos asociados a ella.
Se pueden quitar varias vistas en una misma sentencia DROP VIEW escribiendo los
nombres de las vistas a eliminar separados por comas.
Para ejecutar DROP VIEW, como mnimo, se necesita el permiso ALTER en SCHEMA
o el permiso CONTROL en OBJECT.
Ejemplo:
DROP VIEW oficinas_este, oficinas_EO;
Elimina las vistas oficinas_este y oficinas_EO.
Si eliminamos una tabla mediante DROP TABLE, se deben quitar explcitamente, con
DROP VIEW, las vistas basadas en esta tabla ya que no se quitarn por s solas.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (XV)
8.10. Definicin de ndice
Un ndice es una estructura de datos definida sobre una columna de tabla (o varias) y
que permite localizar de forma rpida las filas de la tabla en base a su contenido en la
columna indexada adems de permitir recuperar las filas de la tabla ordenadas por esa
misma columna.
Funciona de forma parecida al ndice de un libro donde tenemos el ttulo del captulo y
la pgina donde empieza dicho captulo, en un ndice definido sobre una determinada
columna tenemos el contenido de la columna y la posicin de la fila que contiene dicho
valor dentro de la tabla.
La definicin de los ndices de la base de datos es tarea del administrador de la base de
datos, los administradores ms experimentados pueden disear un buen conjunto de
ndices, pero esta tarea es muy compleja, consume mucho tiempo y est sujeta a errores,
incluso con cargas de trabajo y bases de datos con un grado de complejidad no excesivo.
8.11. Tipos de ndices
ndice simple y compuesto.
Un ndice simple est definido sobre una sla columna de la tabla mientras que un
ndice compuesto est formado por varias columnas de la misma tabla (tabla sobre la cual
est definido el ndice.
Cuando se define un ndice sobre una columna, los registros que se recuperen
utilizando el ndice aparecern ordenados por el campo indexado. Si se define un ndice
compuesto por las columnas col1 y col2, las filas que se recuperen utilizando dicho ndice
aparecern ordenadas por los valores de col1 y todas las filas que tengan el mismo valor
de col1 se ordenarn a su vez por los valores contenidos en col2, funcin igual que la
clusula ORDER BY vista en el tema de consultas simples.
154
Por ejemplo si definimos un ndice compuesto basado en las columnas (provincia,
localidad), las filas que se recuperen utilizando este ndice aparecern ordenadas por
provincia y dentro de la misma provincia por localidad.
ndice agrupado y no agrupado,
El trmino ndice agrupado no se debe confundir con ndice compuesto, el significado
es totalmente diferente.
Un ndice agrupado (CLUSTERED) es un ndice en el que el orden lgico de los valores
de clave determina el orden fsico de las filas correspondientes de la tabla. El nivel inferior,
u hoja, de un ndice agrupado contiene las filas de datos en s de la tabla. Una tabla o
vista permite un solo ndice agrupado al mismo tiempo.
Los ndices no agrupados existentes en las tablas se vuelven a generar al crear un
ndice agrupado, por lo que es conveniente crear el ndice agrupado antes de crear los
ndices no agrupados.
Un ndice no agrupado especifica la ordenacin lgica de la tabla. Con un ndice no
agrupado, el orden fsico de las filas de datos es independiente del orden indizado.
ndice nico
ndice nico es aquel en el que no se permite que dos filas tengan el mismo valor en la
columna de clave del ndice. Es decir que no permite valores duplicados.
8.12. Ventajas e inconvenientes de los ndices
Ventajas
La utilizacin de ndices puede mejorar el rendimiento de las consultas, ya que los
datos necesarios para satisfacer las necesidades de la consulta existen en el propio
ndice. Es decir, slo se necesitan las pginas de ndice y no las pginas de datos de la
tabla o el ndice agrupado para recuperar los datos solicitados; por tanto, se reduce la E/S
global en el disco. Por ejemplo, una consulta de las columnas a y b de una tabla que
dispone de un ndice compuesto creado en las columnas a, b y c puede recuperar los
datos especificados del propio ndice.
Los ndices en vistas pueden mejorar de forma significativa el rendimiento si la vista
contiene agregaciones, combinaciones de tabla o una mezcla de agregaciones y
combinaciones.
Inconvenientes
Las tablas utilizadas para almacenar los ndices ocupan espacio.
Los ndices consumen recursos ya que cada vez que se realiza una operacin de
actualizacin, insercin o borrado en la tabla indexada, se tienen que actualizar todas las
tablas de ndice definidas sobre ella (en la actualizacin slo es necesaria la actualizacin
de los ndices definidos sobre las columnas que se actualizan).
Por estos motivos no es buena idea definir ndices indiscriminadamente.
Consideraciones a tener en cuenta
A la hora de definir ndices se deben de tener en cuenta estas consideraciones:
Hay que evitar crear demasiados ndices en tablas que se actualizan con mucha
frecuencia y procurar definirlos con el menor nmero de columnas posible.
155
Es conveniente utilizar un nmero mayor de ndices para mejorar el rendimiento de
consultas en tablas con pocas necesidades de actualizacin, pero con grandes
volmenes de datos. Un gran nmero de ndices contribuye a mejorar el rendimiento
de las consultas que no modifican datos, como las instrucciones SELECT, ya que el
optimizador de consultas dispone de ms ndices entre los que elegir para
determinar el mtodo de acceso ms rpido.
La indizacin de tablas pequeas puede no ser una solucin ptima, porque puede
provocar que el optimizador de consultas tarde ms tiempo en realizar la bsqueda
de los datos a travs del ndice que en realizar un simple recorrido de la tabla. De
este modo, es posible que los ndices de tablas pequeas no se utilicen nunca; sin
embargo, sigue siendo necesario su mantenimiento a medida que cambian los datos
de la tabla.
Se recomienda utilizar una longitud corta en la clave de los ndices agrupados. Los
ndices agrupados tambin mejoran si se crean en columnas nicas o que no
admitan valores NULL.
Un ndice nico en lugar de un ndice no nico con la misma combinacin de
columnas proporciona informacin adicional al optimizador de consultas y, por tanto,
resulta ms til.
Hay que tener en cuenta el orden de las columnas si el ndice va a contener varias
columnas. La columna que se utiliza en la clusula WHERE en una condicin de
bsqueda igual a (=), mayor que (>), menor que (<) o BETWEEN, o que participa en
una combinacin, debe situarse en primer lugar. Las dems columnas deben
ordenarse basndose en su nivel de diferenciacin, es decir, de ms distintas a
menos distintas.
Unidad 8. El DDL, Lenguaje de Definicin de Datos (XVI)
8.13. Definir un ndice CREATE INDEX
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX
nombre_indice
ON <objeto> (columna [ ASC | DESC ] [ ,...n ] )
[ ; ]
<objeto> ::=
{
[nbBaseDatos.[nbEsquema].| nbEsquema.]nbTablaVista
}
Esta es la sintaxis simplicada de la instruccin CREATE INDEX que permite crear un
ndice en una tabla sobre una o varias columnas.
nbBaseDatos Es el nombre de la base de datos.
nbEsquema Es el nombre del esquema al que pertenece la tabla/vista.
nbTablaVista Es el nombre de la tabla o vista sobre la que se quiere crear el ndice.
nombre_indice Es el nombre del ndice que estamos creando.
156
Columna Es el nombre de la columna que forma parte del ndice. Se pueden definir
ndices compuestos escribiendo entre parntesis los nombres de las columnas separados
por comas.
ASC los valores de la columna se ordenarn de forma ASCendente o DESCendente.
Por defecto se asume ASC.
UNIQUE permite definir un ndice nico (no admite valores repetidos).
CLUSTERED el ndice ser agrupado.
NONCLUSTERED (valor por defecto) el ndice ser no agrupado.
Ejemplos:
CREATE INDEX I_clientes_nombre ON Clientes (nombre)
Crea un ndice no agrupado sobre la columna nombre de la tabla Clientes en la base de
datos actual, las filas se ordenarn de forma ascendente.
CREATE INDEX I_clientes_ApeNom ON Clientes (apellidos, nombre)
Crea un ndice no agrupado sobre las columnas apellidos y nombre de la tabla Clientes
en la base de datos actual, las filas se ordenarn de forma ascendente por apellido y
dentro del mismo apellido por nombre.
CREATE INDEX I_clientes_EdadApe ON Clientes (edad
DESC,apellidos)
Crea un ndice no agrupado sobre las columnas edad y apellidos de la tabla Clientes en
la base de datos actual, las filas se ordenarn de forma descendente por edad y
ascendente por apellido. Aparecern los clientes de mayor a menor edad y los clientes de
la misma edad se ordenarn por apellido (por orden alfabtico).
CREATE CLUSTERED INDEX I_clientes_cod ON Clientes (codigo)
Crea un ndice agrupado sobre la columna codigo de la tabla Clientes en la base de
datos actual, las filas se ordenarn y almacenarn por orden de cdigo.
CREATE UNIQUE INDEX U_clientes_col ON Clientes (col)
Crea un ndice nico sobre la columna col de la tabla Clientes en la base de datos
actual, la columna col no podr contener valores duplicados.
8.14. Eliminar un ndice DROP INDEX
Para eliminar un ndice tenemos la sentencia DROP INDEX.
La instruccin DROP INDEX no es aplicable a los ndices creados mediante la definicin
de restricciones PRIMARY KEY y UNIQUE. Para quitar la restriccin y el ndice
correspondiente, se tiene que ejecutar un ALTER TABLE con la clusula DROP
CONSTRAINT.
157
Sintaxis simplificada:
DROP INDEX <indice> [ ,...n ] [ ; ]
<indice>::=
{
nbindice ON [nbBaseDatos.[nbEsquema].|nbEsquema.]nbTablaVista
}
nbBaseDatos Es el nombre de la base de datos.
nbEsquema Es el nombre del esquema al que pertenece la tabla/vista.
nbTablaVista Es el nombre de la tabla o vista de la que se quiere eliminar el ndice.
nbindice Es el nombre del ndice a eliminar.
Ejemplo:
DROP INDEX U_clientes_col ON Clientes;
Elimina el ndice U_clientes_col definido sobre la tabla Clientes.
Unidad 9. Programacin en TRANSACT SQL (I)
9.1. Introduccin
Hasta ahora hemos estudiado sentencias SQL orientadas a realizar una determinada
tarea sobre la base de datos como definir tablas, obtener informacin de las tablas,
actualizarlas; estas sentencias las hemos ejecutado desde el editor de consultas del
MSSMS de una en una o a lo sumo una a continuacin de la otra dentro de la misma
consulta formando un lote de instrucciones.
Las sentencias que ya conocemos son las que en principio forman parte de cualquier
lenguaje SQL. Ahora veremos que TRANSACT-SQL va ms all de un lenguaje SQL
cualquiera ya que aunque no permita:
Crear interfaces de usuario.
Crear aplicaciones ejecutables, sino elementos que en algn momento llegarn al
servidor de datos y sern ejecutados.
Incluye caractersticas propias de cualquier lenguaje de programacin, caractersticas
que nos permiten definir la lgica necesaria para el tratamiento de la informacin:
Tipos de datos.
Definicin de variables.
Estructuras de control de flujo.
Gestin de excepciones.
Funciones predefinidas.
158
Elementos para la visualizacin, que permiten mostrar mensajes definidos por el
usuario gracias a la clusula PRINT.
Estas caractersticas nos van a permitir crear bloques de cdigo orientados a realizar
operaciones ms complejas. Estos bloques no son programas sino procedimientos o
funciones que podrn ser llamados en cualquier momento.
En SQL Server 2005 podemos definir tres tipos de bloques de cdigo, los procedimientos
almacenados, los desencadenadores (o triggers) y funciones definidas por el usuario.
Nosotros estudiaremos los dos primeros.
Empezaremos por los procedimientos almacenados, veremos primero las sentencias
para crear y eliminar procedimientos almacenados, luego estudiaremos las instrucciones
Transact-SQL ms propias de un lenguaje de programacin nombradas en el tema de
Introduccin al Transact-SQL como son por ejemplo los bucles y estructuras
condicionales. Estas instrucciones las utilizaremos dentro de procedimientos
almacenados pero veremos que tambin nos servirn para definir otros bloques de
cdigo.
Terminaremos esta unidad de programacin estudiando los disparadores o Triggers
muy similares a los procedimientos almacenados que difieren bsicamente en la forma en
que entran en funcionamiento.
9.2. Procedimientos almacenados STORE PROCEDURE
Un procedimiento almacenado (STORE PROCEDURE) est formado por un conjunto
de instrucciones Transact-SQL que definen un determinado proceso, puede aceptar
parmetros de entrada y devolver un valor o conjunto de resultados. Este procedimiento
se guarda en el servidor y puede ser ejecutado en cualquier momento.
Los procedimientos almacenados se diferencian de las instrucciones SQL ordinarias y
de los lotes de instrucciones SQL en que estn precompilados. La primera vez que se
ejecuta un procedimiento, el procesador de consultas de SQL Server lo analiza y prepara
un plan de ejecucin que se almacena en una tabla del sistema. Posteriormente, el
procedimiento se ejecuta segn el plan almacenado. Puesto que ya se ha realizado la
mayor parte del trabajo de procesamiento de consultas, los procedimientos almacenados
se ejecutan casi de forma instantnea por lo que el uso de procedimientos almacenados
mejora notablemente la potencia y eficacia del SQL.
SQL Server incorpora procedimientos almacenados del sistema, se encuentran en la
base de datos master y se reconocen por su nombre, todos tienen un nombre que
empieza por sp_. Permiten recuperar informacin de las tablas del sistema y pueden
ejecutarse en cualquier base de datos del servidor.
Tambin estn los procedimientos de usuario, los crea cualquier usuario que tenga los
permisos oportunos.
Se pueden crear tambin procedimiento temporales locales y globales. Un
procedimiento temporal local se crea por un usuario en una conexin determinada y slo
se puede utilizar en esa sesin, un procedimiento temporal global lo pueden utilizar todos
los usuarios, cualquier conexin puede ejecutar un procedimiento almacenado temporal
global. ste existe hasta que se cierra la conexin que el usuario utiliz para crearlo, y
hasta que se completan todas las versiones del procedimiento que se estuvieran
ejecutando mediante otras conexiones. Una vez cerrada la conexin que se utiliz para
crear el procedimiento, ste ya no se puede volver a ejecutar, slo podrn finalizar las
conexiones que hayan empezado a ejecutar el procedimiento.
Tanto los procedimientos temporales como los no temporales se crean y ejecutan de
la misma forma, el nombre que le pongamos indicar de qu tipo es el procedimiento.
159
Los procedimientos almacenados se crean mediante la sentencia CREATE
PROCEDURE y se ejecutan con EXEC (o EXECUTE). Para ejecutarlo tambin se puede
utilizar el nombre del procedimiento almacenado slo, siempre que sea la primera palabra
del lote. Para eliminar un procedimiento almacenado utilizamos la sentencia DROP
PROCEDURE.
9.3. Eliminar procedimientos almacenados
Aunque no sabemos todava crear un procedimiento comentaremos aqu la instruccin
para eliminar procedimientos y as podremos utilizarla en los dems ejercicios.
DROP {PROC|PROCEDURE} [nombreEsquema.]nombreProcedimiento
[,...n ].
Transact-SQL permite abreviar la palabra reservada PROCEDURE por PROC sin que
ello afecte a la funcionalidad de la instruccin.
Ejemplos:
DROP PROCEDURE Dice_Hola;
Elimina el procedimiento llamado Dice_Hola.
DROP PROC Dice_Hola;
Es equivalente, PROC y PROCEDURE indican lo mismo.
Para eliminar varios procedimientos de golpe, indicamos sus nombres separados por
comas:
DROP PROCEDURE Dice_Hola, Ventas_anuales;
Elimina los procedimientos Dice_Hola y Ventas_anuales.
Unidad 9. Programacin en TRANSACT SQL (II)
9.4. Crear y ejecutar un procedimiento
CREATE PROCEDURE
Para crear un procedimiento almacenado como hemos dicho se emplea la instruccin
CREATE PROCEDURE:
CREATE {PROC|PROCEDURE} [NombreEsquema.]NombreProcedimiento
[{@parametro tipo} [VARYING] [= valorPredet]
[OUT|OUTPUT] ] [,...n]
AS { <bloque_instrucciones> [ ...n] }[;]
<bloque_instrucciones> ::=
160
{[BEGIN] instrucciones [END] }
Las instrucciones CREATE PROCEDURE no se pueden combinar con otras
instrucciones SQL en el mismo lote.
Despus del verbo CREATE PROCEDURE indicamos el nombre del procedimiento,
opcionalmente podemos incluir el nombre del esquema donde queremos que se cree el
procedimiento, por defecto se crear en dbo. Ya que Sqlserver utiliza el prefijo sp_ para
nombrar los procedimientos del sistema se recomienda no utilizar nombres que empiecen
por sp_.
Como se puede deducir de la sintaxis (no podemos indicar un nombre de base de datos
asociado al nombre del procedimiento) slo se puede crear el procedimiento almacenado
en la base de datos actual, no se puede crear en otra base de datos.
Si queremos definir un procedimiento temporal local el nombre deber empezar por una
almohadilla (#) y si el procedimiento es temporal global el nombre debe de empezar por
##.
El nombre completo de un procedimiento almacenado o un procedimiento almacenado
temporal global, incluidas ##, no puede superar los 128 caracteres. El nombre completo
de un procedimiento almacenado temporal local, incluidas #, no puede superar los 116
caracteres.
Transact-SQL permite abreviar la palabra reservada PROCEDURE por PROC sin que
ello afecte a la funcionalidad de la instruccin.
CREATE PROC Calcula_comision AS
Es equivalente a
CREATE PROCEDURE calcula_comision AS
@parametro: representa el nombre de un parmetro. Se pueden declarar uno o ms
parmetros indicando para cada uno su nombre (debe de empezar por arroba) y su tipo
de datos, y opcionalmente un valor por defecto (=valorPredet) este valor ser el asumido
si en la llamada el usuario no pasa ningn valor para el parmetro. Un procedimiento
almacenado puede tener un mximo de 2.100 parmetros.
Los parmetros son locales para el procedimiento; los mismos nombres de parmetro
se pueden utilizar en otros procedimientos. De manera predeterminada, los parmetros
slo pueden ocupar el lugar de expresiones constantes; no se pueden utilizar en lugar de
nombres de tabla, nombres de columna o nombres de otros objetos de base de datos.
VARYING Slo se aplica a los parmetros de tipo cursor por lo que se explicar
cuando se expliquen los cursores.
OUTPUT | OUT (son equivalentes)
Indica que se trata de un parmetro de salida. El valor de esta opcin puede devolverse
a la instruccin EXECUTE que realiza la llamada.
El parmetro variable OUTPUT debe definirse al crear el procedimiento y tambin se
indicar en la llamada junto a la variable que recoger el valor devuelto del parmetro. El
nombre del parmetro y de la variable no tienen por qu coincidir; sin embargo, el tipo de
datos y la posicin de los parmetros deben coincidir a menos que se indique el nombre
del parmetro en la llamada de la forma @parametro=valor.
161
Procedimiento bsico
CREATE PROCEDURE Dice_Hola
AS
PRINT Hola;
GO - Indicamos GO para cerrar el lote que crea el
procedimiento y empezar otro lote.
EXEC Dice_Hola; -- De esta forma llamamos al procedimiento
(se ejecuta).
En este caso, como la llamada es la primera del lote (va detrs del GO) podamos
haber obviado la palabra EXEC y haber escrito directamente:
Dice_Hola
Unidad 9. Programacin en TRANSACT SQL (III)
Con un parmetro de entrada (la palabra que queremos que escriba)
CREATE PROCEDURE Dice_Palabra @palabra CHAR(30)
AS
PRINT @palabra;
GO
EXEC Dice_Palabra Lo que quiera;
EXEC Dice_Palabra Otra cosa;
Aqu hemos hecho dos llamadas, una con el valor Lo que quiera y otra con el valor
Otra cosa.
Con varios parmetros
Si queremos indicar varios parmetros los separamos por comas.
USE Biblio;
--DROP PROC VerUsuariosPoblacion; --La comentamos la primera
vez
GO
CREATE PROCEDURE VerUsuariosPoblacion @pob CHAR(30),@pro
CHAR(30)
AS
SELECT * FROM usuarios WHERE poblacion=@pob AND provincia =
@pro;
GO
162
EXEC VerUsuariosPoblacion Madrid, Valencia
En la llamada podemos indicar los valores de los parmetros de varias formas,
indicando slo el valor de los parmetros (en este caso los tenemos que indicar en el
mismo orden en que estn definidos) como en el ejemplo anterior, o bien indicando el
nombre del parmetro:
EXEC VerUsuariosPoblacion @pob=Madrid, @pro=Valencia
Indicar el nombre del parmetro en la llamada tambin nos permite indicar los valores
en cualquier orden, la siguiente llamada es equivalente a la anterior, hemos invertido el
orden y se ejecuta igual:
EXEC VerUsuariosPoblacion @pro=Valencia, @pob=Madrid
En este procedimiento todos los parmetros son obligatorios, no deja llamar con un solo
parmetro.
EXEC VerUsuariosPoblacion Madrid
Da error.
Con parmetros opcionales
Para definir un parmetro opcional tenemos que asignarle un valor por defecto en la
definicin del procedimiento.
DROP PROC VerUsuariosPoblacion2;
GO
CREATE PROCEDURE VerUsuariosPoblacion2 @pob CHAR(30),@pro
CHAR(30)='Madrid'
AS
SELECT * FROM usuarios WHERE poblacion=@pob AND provincia =
@pro;
GO
EXEC VerUsuariosPoblacion2 Madrid
En este caso, en la llamada slo hemos indicado un valor, para el primer parmetro, el
parmetro opcional no lo hemos indicado y se rellenar con el valor por defecto que
indicamos en la definicin.
Lo podemos hacer as porque el parmetro opcional es el ltimo de la lista de
parmetros. Cuando el parmetro opcional no es el ltimo la llamada tiene que ser
diferente, tenemos que nombrar los parmetros en la llamada, al menos a partir del
parmetro opcional.
DROP PROC VerUsuariosPoblacion3;
GO
163
CREATE PROCEDURE VerUsuariosPoblacion3 @a CHAR(2),@pob
CHAR(30)='Madrid',@pro CHAR(30)
AS
SELECT * FROM usuarios WHERE poblacion=@pob AND provincia =
@pro;
GO
EXEC VerUsuariosPoblacion3 a,@pro='Madrid'
En este caso el parmetro opcional es el segundo de la lista de parmetros, cuando
hacemos la llamada no podemos hacer como en otros lenguajes de dejar un hueco:
EXEC VerUsuariosPoblacion3 a, ,'Madrid'
Da error.
Esta forma da error, debemos utilizar la palabra DEFAULT o indicar el nombre de todos
los parmetros que van detrs del opcional.
EXEC VerUsuariosPoblacion3 a,DEFAULT,'Madrid'
Unidad 9. Programacin en TRANSACT SQL (IV)
Con parmetros de salida
Un procedimiento almacenado puede tambin devolver resultados, definiendo el
paramtro como OUTPUT o bien utilizando la instruccin RETURN que veremos en el
siguiente apartado.
Para poder recoger el valor devuelto por el procedimiento, en la llamada se tiene que
indicar una variable donde guardar ese valor.
Ejemplo:
Definimos el procedimiento ultimo_contrato que nos devuelte la fecha en que se firm el
ltimo contrato en una determinada oficina. El procedimiento tendr pues dos parmetros,
uno de entrada para indicar el nmero de la oficina a considerar y uno de salida que
devolver la fecha del contrato ms reciente de entre los empleados de esa oficina.
USE Gestion
GO
CREATE PROC ultimo_contrato @ofi INT, @fecha DATETIME OUTPUT
AS
SELECT @fecha=(SELECT MAX(contrato) FROM empleados WHERE
oficina=@ofi)
GO
Con @fecha DATETIME OUTPUT indicamos que el parmetro @fecha es de salida, el
proceso que realice la llamada podr recoger su valor despus de ejecutar el
procedimiento.
164
En la llamada, para los parmetros de salida, en vez de indicar un valor de entrada se
indica un nombre de variable, variable que recoger el valor devuelto por el procedimiento
sin olvidar la palabra OUTPUT:
DECLARE @ultima AS DATETIME;
EXEC ultimo_contrato 12,@ultima OUTPUT;
PRINT @ultima;
RETURN
RETURN ordena salir incondicionalmente de una consulta o procedimiento, se puede
utilizar en cualquier punto para salir del procedimiento y las instrucciones que siguen a
RETURN no se ejecutan. Adems los procedimientos almacenados pueden devolver un
valor entero mediante esta orden.
RETURN [expresion_entera]
Expresion_entera es el valor entero que se devuelve.
A menos que se especifique lo contrario, todos los procedimientos almacenados del
sistema devuelven el valor 0. Esto indica que son correctos y un valor distinto de cero
indica que se ha producido un error.
Cuando se utiliza con un procedimiento almacenado, RETURN no puede devolver un
valor NULL. Si un procedimiento intenta devolver un valor NULL (por ejemplo, al utilizar
RETURN @var si @var es NULL), se genera un mensaje de advertencia y se devuelve el
valor 0.
Si queremos recoger el valor de estado devuelto por el procedimiento la llamada debe
ser distinta, y seguir el siguiente modelo:
EXECUTE @variable_donde_recogemos_estado =
nombre_procedimiento @par, ...
Con el procedimiento del punto anterior no se puede utilizar esta forma de devolver un
resultado porque lo que se devuelve es una fecha, no es un valor entero, pero si
quisiramos definir un procedimiento que nos devuelva el nmero de empleados de una
oficina podramos hacerlo de dos formas:
De la forma normal con un parmetro de salida:
USE Gestion
GO
CREATE PROC trabajadores @ofi INT, @num INT OUTPUT
AS
SELECT @num=(SELECT COUNT(*) FROM empleados WHERE
oficina=@ofi)
GO
165
Para obtener en la variable @var el resultado devuelto por el procedimiento la llamada
sera:
DECLARE @var INT;
EXEC trabajadores 12, @var OUTPUT
Utilizando return en vez de un parmetro de salida:
CREATE PROC trabajadores2 @ofi INT
AS
RETURN (SELECT COUNT(*) FROM empleados WHERE oficina=@ofi)
GO
Para obtener en la variable @var el resultado devuelto por el procedimiento la llamada
sera:
DECLARE @var INT;
EXEC @var= trabajadores2 12
PRINT @var
Nos visualiza el nmero de trabajadores de la oficina nmero 12.
Unidad 9. Programacin en TRANSACT SQL (V)
9.5. Instrucciones de control de flujo
Disponemos de diferentes elementos para el control de flujo, como pueden ser
RETURN, IF... ELSE, WHILE, BREAK, CONTINUE, GO TO, EXECUTE, etc. En los
siguientes apartados aprenderemos cmo utilizarlos.
9.6. IF ELSE
Proporciona una ejecucin condicional, permite ejecutar o no ciertas instrucciones
dependiendo de si se cumple o no una determinada condicin.
IF condicion
{ sentencia_sql | bloque_sql }
[ ELSE
{ sentencia_sql | bloque_sql } ]
Si la condicin se cumple (da como resultado TRUE) se ejecuta la instruccin SQL o
bloque de instrucciones que aparecen a continuacin de la condicin, si la condicin no se
cumple se ejecutan las sentencias que aparecen despus de la palabra ELSE. El bloque
ELSE es opcional.
166
Ejemplo: Si nos queremos guardar en una consulta todos los ejemplos para probarlos
en cualquier momento, es conveniente antes de los CREATE PROCEDURE colocar un
DROP PROCEDURE para que la instruccin CREATE no d error si el procedimiento ya
existe, pero la primera vez la instruccin DROP PROC nos dar error porque el
procedimiento todava no existe, as que lo mejor es ejecutar el DROP slo si el
procedimiento existe, utilizando la funcin object_id(nombre_de_objeto,tipo de objeto)
que nos devuelve el id del objeto y NULL si el objeto no existe.
IF object_id('trabajadores', 'P') IS NOT NULL
DROP PROCEDURE trabajadores;
GO
CREATE PROC trabajadores.
Otro ejemplo. Ahora queremos el procedimiento y si no existe se mandar un mensaje
"el procedimiento no existe":
IF object_id('trabajadores', 'P') IS NOT NULL
BEGIN
PRINT 'Borramos el procedimiento'
DROP PROC trabajadores
END
ELSE PRINT 'El procedimiento ya existe'
Cuando queremos definir un bloque de instrucciones utilizamos los delimitadores
BEGIN..END
Se pueden anidar varias sentencias IF hasta el lmite que permita la memoria.
9.7. WHILE BREAK- CONTINUE
Esta instruccin permite definir un bucle que repite una sentencia o bloque de
sentencias mientras se cumpla una determinada condicin.
WHILE condicion
{ sentencia_sql | bloque_sql }
| BREAK
| CONTINUE
Podemos anidar bucles, colocar un bucle WHILE dentro de otro
BREAK Produce la salida del bucle WHILE ms interno. La instruccin BREAK interna
sale al siguiente bucle ms externo. Todas las instrucciones que se encuentren despus
del final del bucle interno se ejecutan primero y despus se reinicia el siguiente bucle ms
externo.
167
CONTINUE Hace que se reinicie el bucle WHILE y omite las instrucciones que haya
despus de la palabra clave CONTINUE.
Por ejemplo, tenemos los siguientes bucles anidados:
WHILE condicion1 -- Bucle 1
Instrucciones_1_1
WHILE condicion2 -- Bucle 2
Intrucciones2_1
If condicion3 BREAK
Instrucciones2_2
IF condicion4 CONTINUE
Instrucciones2_3
Instrucciones1_2
Las instrucciones se ejecutaran en este orden:
Preguntamos por condicion1:
Si condicion1 se cumple:
Se ejecuta el bloque Instrucciones1_1
Preguntamos por condicon2:
Si se cumple condicion2:
Se ejecuta el bloque de instrucciones Instrucciones_2_1.
Si condicin3 se cumple:
Salimos del bucle 2,
Se ejecuta el bloque Instrucciones1_2
Y se vuelve a preguntar por condicion1.
Si condicin3 no se cumple:
Se ejecuta el bloque instrucciones2_2
Si se cumple condicion4:
Saltamos el bloque Instrucciones2_3
Y se vuelve a preguntar por condicion2
Si no se cumple condicion4:
Se ejecuta el bloque Instrucciones2_3
Y se vuelve a preguntar por condicion2
168
Si condicion2 no se cumple:
Se ejecuta el bloque Instrucciones 1_2
Se vuelve a preguntar por condicion1
Si condicion1 no se cumple:
Hemos terminado
Unidad 9. Programacin en TRANSACT SQL (VI)
9.8. WAITFOR
Bloquea la ejecucin de un lote, un procedimiento almacenado o una transaccin hasta
alcanzar la hora o el intervalo de tiempo especificado, o hasta que una instruccin
especificada modifique o devuelva al menos una fila. Nosotros estudiaremos los dos
primeros casos.
WAITFOR {DELAY 'tiempo_a_transcurrir'
|TIME 'fechaHora_de_ejecucion'}
DELAY permite indicar un perodo de tiempo especificado (hasta un mximo de 24
horas) que debe transcurrir antes de la ejecucin de un lote, un procedimiento
almacenado o una transaccin.
'tiempo_a_transcurrir' Es el perodo de tiempo que hay que esperar, se puede
especificar en uno de los formatos aceptados para el tipo de datos datetime o como una
variable local. No se pueden especificar fechas; por lo tanto, no se permite la parte de
fecha del valor datetime.
TIME permite indicar la hora especfica a la que se ejecuta el lote, el procedimiento
almacenado o la transaccin.
'fechaHora_de_ejecucion' Es la hora a la que termina la instruccin WAITFOR por tanto
a la que empieza la ejecucin de las instrucciones siguientes a WAITFOR. Se puede
especificar en uno de los formatos aceptados para el tipo de datos datetime o como una
variable local. No se pueden especificar fechas; por lo tanto, no se permite la parte de
fecha del valor datetime.
Cada instruccin WAITFOR tiene un subproceso asociado. Si se especifica un gran
nmero de instrucciones WAITFOR en el mismo servidor, se pueden acumular muchos
subprocesos a la espera de que se ejecuten estas instrucciones. SQL Server supervisa el
nmero de subprocesos asociados con las instrucciones WAITFOR y selecciona
aleatoriamente algunos de estos subprocesos para salir si el servidor empieza a
experimentar la falta de subprocesos.
Ejemplo:
PRINT CONVERT(CHAR(8),Getdate(),108);
WAITFOR DELAY '00:00:03'
PRINT CONVERT(CHAR(8),Getdate(), 108);
WAITFOR DELAY '00:03'
169
PRINT CONVERT(CHAR(8),Getdate(), 108);
Visualiza la hora actual, espera 3 segundos y vuelve a visualizar la hora actual,
despus espera 3 minutos y vuelve a visualizar la hora actual. Se ha utilizado la funcin
CONVERT con el estilo 108 para que aparezca slo la hora y con segundos.
9.9. GOTO
Altera el flujo de ejecucin y lo dirige a una etiqueta.
Las etiquetas se indican mediante un nombre seguido del carcter:
GOTO NombreEtiqueta
Ejemplo:
IF Condicion GOTO etiq
----
Etiq:
----
----
Es una instruccin a evitar porque puede llevar a redactar programas no estructurados.
9.10. TRY... CATCH
Definicin
La estructura TRYCATCH implementa un mecanismo de control de errores para
Transact-SQL, permite incluir un grupo de instrucciones Transact-SQL en un bloque TRY.
Si se produce un error en el bloque TRY, el control se transfiere a otro grupo de
instrucciones que est incluido en un bloque CATCH.
BEGIN TRY
{sentencia_sql|bloque_sql}
END TRY
BEGIN CATCH
[{sentencia_sql|bloque_sql}]
END CATCH [ ; ]
Una construccin TRYCATCH no puede abarcar varios bloques de instrucciones
Transact-SQL (varios bloques BEGINEND de instrucciones Transact-SQL) ni una
construccin IFELSE.
Si no hay errores en el cdigo incluido en un bloque TRY, cuando la ltima instruccin
de este bloque ha terminado de ejecutarse, el control se transfiere a la instruccin
inmediatamente posterior a la instruccin END CATCH asociada. Si hay un error en el
cdigo incluido en el bloque TRY, el control se transfiere a la primera instruccin del
bloque CATCH asociado. Si la instruccin END CATCH es la ltima instruccin de un
170
procedimiento almacenado o desencadenador, el control se devuelve a la instruccin que
llam al procedimiento almacenado o activ el desencadenador.
Las construcciones TRYCATCH se pueden anidar.
Las construcciones TRYCATCH capturan los errores no controlados de los
procedimientos almacenados o desencadenadores ejecutados por el cdigo del bloque
TRY. Alternativamente, los procedimientos almacenados o desencadenadores pueden
contener sus propias construcciones TRYCATCH para controlar los errores generados
por su cdigo. Por ejemplo, cuando un bloque TRY ejecuta un procedimiento almacenado
y se produce un error en ste, el error se puede controlar de las formas siguientes:
Si el procedimiento almacenado no contiene su propia construccin TRYCATCH,
el error devuelve el control al bloque CATCH asociado al bloque TRY que contiene
la instruccin EXECUTE.
Si el procedimiento almacenado contiene una construccin TRYCATCH, el error
transfiere el control al bloque CATCH del procedimiento almacenado. Cuando
finaliza el cdigo del bloque CATCH, el control se devuelve a la instruccin
inmediatamente posterior a la instruccin EXECUTE que llam al procedimiento
almacenado.
No se pueden utilizar instrucciones GOTO para entrar en un bloque TRY o CATCH pero
se puede utilizar para saltar a una etiqueta dentro del mismo bloque TRY o CATCH, o bien
para salir de un bloque TRY o CATCH.
TRYCATCH no se puede utilizar en una funcin definida por el usuario.
Unidad 9. Programacin en TRANSACT SQL (VII)
Recuperar informacin sobre errores
En el mbito de un bloque CATCH, se pueden utilizar las siguientes funciones del
sistema para obtener informacin acerca del error que provoc la ejecucin del bloque
CATCH:
ERROR_NUMBER() devuelve el nmero del error.
ERROR_SEVERITY() devuelve la gravedad.
ERROR_STATE() devuelve el nmero de estado del error.
ERROR_PROCEDURE() devuelve el nombre del procedimiento almacenado o
desencadenador donde se produjo el error.
ERROR_LINE() devuelve el nmero de lnea de la rutina que provoc el error.
ERROR_MESSAGE() devuelve el texto completo del mensaje de error. Este texto
incluye los valores suministrados para los parmetros reemplazables, como
longitudes, nombres de objetos u horas.
Estas funciones devuelven NULL si se las llama desde fuera del mbito del bloque
CATCH. Con ellas se puede recuperar informacin sobre los errores desde cualquier lugar
dentro del mbito del bloque CATCH. Por ejemplo, en la siguiente secuencia de
comandos se muestra un procedimiento almacenado que contiene funciones de control de
errores. Se llama al procedimiento almacenado en el bloque CATCH de una construccin
TRYCATCH y se devuelve informacin sobre el error.
Ejemplo, vamos a definir un procedimiento para calcular el precio unitario a partir de un
importe y una cantidad:
171
-- Verificamos que el procedimiento que vamos a crear no
existe.
IF OBJECT_ID ('CalculaPrecio', 'P' ) IS NOT NULL
DROP PROCEDURE CalculaPrecio;
GO
-- Creamos el procedimiento
CREATE PROCEDURE CalculaPrecio @importe MONEY,@cant
INT,@precio MONEY OUTPUT
AS
BEGIN TRY
SELECT @precio=@importe/@cant;
END TRY
BEGIN CATCH
IF ERROR_NUMBER() = 8134 SELECT @precio=0
ELSE SELECT ERROR_NUMBER() as ErrorNumero,ERROR_MESSAGE() as
MensajeDeError;
END CATCH;
GO
-- Lo utilizamos
DECLARE @resultado MONEY
EXEC CalculaPrecio 1000, 0, @resultado OUTPUT
SELECT 'resul', @resultado
Si al llamar al procedimiento le pasamos una cantidad igual a cero, la divisin provocar
un error, se pasar el control al bloque CATCH, en este bloque se evala si el error
corresponde al error de divisin por cero (8134), si es as el procedimiento devuelve un
precio igual a cero, sino se enva un mensaje para avisar del error.
Errores controlados por TRYCATCH
TRYCATCH detecta todos los errores de ejecucin que tienen una gravedad mayor
de 10 y que no cierran la conexin de la base de datos.
TRYCATCH no detecta:
Advertencias o mensajes informativos que tienen gravedad 10 o inferior.
Errores que tienen gravedad 20 o superior que detienen el procesamiento de las
tareas de SQL Server Database Engine en la sesin. Si se produce un error con una
gravedad 20 o superior y no se interrumpe la conexin con la base de datos,
TRYCATCH controlar el error.
Atenciones, como solicitudes de interrupcin de clientes o conexiones de cliente
interrumpidas.
Cuando el administrador del sistema finaliza la sesin mediante la instruccin KILL.
Un bloque CATCH no controla los siguientes tipos de errores cuando se producen
en el mismo nivel de ejecucin que la construccin TRYCATCH:
172
Errores de compilacin, como errores de sintaxis, que impiden la ejecucin de un
lote.
Errores que se producen durante la recompilacin de instrucciones, como errores de
resolucin de nombres de objeto que se producen despus de la compilacin debido
a una resolucin de nombres diferida.
Estos errores se devuelven al nivel de ejecucin del lote, procedimiento almacenado o
desencadenador.
En el ejemplo siguiente se muestra cmo la construccin TRYCATCH no captura un
error de resolucin de nombre de objeto generado por una instruccin SELECT, sino que
es el bloque CATCH el que lo captura cuando la misma instruccin SELECT se ejecuta
dentro de un procedimiento almacenado (a un nivel inferior).
USE Gestion;
GO
BEGIN TRY
SELECT * FROM TablaQueNoExiste;
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() as ErrorNumero,ERROR_MESSAGE() as
MensajeDeError;
END CATCH
Intentamos ejecutar una SELECT de una tabla que no existe en la base de datos. El
error no se captura y el control se transfiere fuera de la construccin TRYCATCH, al
siguiente nivel superior, en este caso salta el mensaje de error del sistema.
Al ejecutar la misma instruccin SELECT dentro de un procedimiento almacenado, el error
se producir en un nivel inferior al bloque TRY y la construccin TRYCATCH controlar
el error.
IF OBJECT_ID ('TablaInexistente','P') IS NOT NULL
DROP PROCEDURE TablaInexistente;
GO
-- Creamos el procedimiento.
CREATE PROCEDURE TablaInexistente
AS
SELECT * FROM TablaQueNoExiste;
GO
-- Utilizamos el procedimiento
BEGIN TRY
EXECUTE TablaInexistente
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() as ErrorNumero,ERROR_MESSAGE() as
MensajeDeError;
173
END CATCH;
En este caso como el error se produce dentro del procedimiento, el control del error se
devuelve al nivel superior (el que ha realizado el EXECUTE) por lo que es capturado por
el TRY y entra en el bloque CATCH, en vez de que salte el mensaje de error del sistema
saldr el nuestro.
Unidad 9. Programacin en TRANSACT SQL (VIII)
9.11. Desencadenadores o TRIGGERS
Un desencadenador (o Trigger) es una clase especial de procedimiento almacenado
que se ejecuta automticamente cuando se produce un evento en el servidor de bases de
datos.
SQL Server permite crear varios desencadenadores para una instruccin especfica.
Segn el tipo de evento que los desencadena se clasifican en:
Desencadenadores DML
Desencadenadores DDL
Desencadenadores LOGON
Los desencadenadores DML se ejecutan cuando un usuario intenta modificar datos
mediante un evento de lenguaje de manipulacin de datos (DML). Los eventos DML son
instrucciones INSERT, UPDATE o DELETE de una tabla o vista.
Los desencadenadores DDL se ejecutan en respuesta a una variedad de eventos de
lenguaje de definicin de datos (DDL). Estos eventos corresponden principalmente a
instrucciones CREATE, ALTER y DROP de Transact-SQL, y a determinados
procedimientos almacenados del sistema que ejecutan operaciones de tipo DDL.
Los desencadenadores logon se activan en respuesta al evento LOGON que se genera
cuando se establece la sesin de un usuario.
Nosotros limitaremos nuestro estudio a los desencadenadores DML.
9.12. CREATE TRIGGER
Esta instruccin nos permite definir un trigger:
CREATE TRIGGER [NombreEsquema.]NombreTrigger
ON {tabla | vista } [,...n] ]
{FOR|AFTER|INSTEAD OF} {[INSERT][,][UPDATE][,][DELETE]}
AS sentencia_sql [;] [,...n ]
NombreEsquema es el nombre del esquema al que pertenece el desencadenador DML.
Los desencadenadores DML se limitan al esquema de la tabla o vista en la que se
crearon.
174
NombreTrigger es el nombre que le queremos dar al desencadenador. No puede
comenzar con los smbolos # o ##.
Tabla | vista es el nombre de la tabla o vista en la que se ejecuta el desencadenador.
Slo se puede hacer referencia a una vista mediante un desencadenador INSTEAD OF.
No es posible definir desencadenadores DML en tablas temporales locales o globales.
DELETE INSERT UPDATE Especifica las instrucciones de modificacin de datos que
activan el desencadenador cuando se intenta ejecutarlas en esta tabla o vista. Se debe
especificar al menos una opcin. En la definicin del desencadenador se permite cualquier
combinacin de estas opciones, en cualquier orden.
AFTER indica que el desencadenador slo se activa cuando todas las operaciones
especificadas en la instruccin SQL desencadenadora se han ejecutado correctamente.
Adems, todas las acciones referenciales en cascada y las comprobaciones de
restricciones deben ser correctas para que este desencadenador se ejecute.
AFTER es el valor predeterminado cuando slo se especifica la palabra clave FOR.
Los desencadenadores AFTER no se pueden definir en las vistas.
INSTEAD OF indica que se ejecuta el desencadenador en vez de la instruccin SQL
desencadenadora, por lo que se suplantan las acciones de las instrucciones
desencadenadoras.
Como mximo, se puede definir un desencadenador INSTEAD OF por cada instruccin
INSERT, UPDATE o DELETE en cada tabla o vista. No obstante, en las vistas es posible
definir otras vistas que tengan su propio desencadenador INSTEAD OF.
Los desencadenadores INSTEAD OF no se pueden utilizar en vistas actualizables que
usan WITH CHECK OPTION.
Los desencadenadores INSTEAD OF DELETE/UPDATE no se permiten en tablas que
tengan una clave ajena definida con ON DELETE/UPDATE CASCADE.
CREATE TRIGGER debe ser la primera instruccin en el proceso por lotes.
Un desencadenador se crea solamente en la base de datos actual; sin embargo, puede
hacer referencia a objetos que estn fuera de la base de datos actual.
Si se especifica el nombre del esquema del desencadenador hay que calificar tambin
el nombre de la tabla o vista.
En un desencadenador se puede especificar cualquier instruccin SET. La opcin SET
seleccionada permanece en efecto durante la ejecucin del desencadenador y, despus,
vuelve automticamente a su configuracin anterior.
Un desencadenador est diseado para comprobar o cambiar los datos en base a una
instruccin de modificacin o definicin de datos; no debe devolver datos al usuario por lo
que se aconseja no incluir en un desencadenador instrucciones SELECT que devuelven
resultados ni las instrucciones que realizan una asignacin variable. Si es preciso que
existan asignaciones de variable en un desencadenador, tenemos que utilizar la
instruccin SET NOCOUNT al principio del mismo para impedir la devolucin de cualquier
conjunto de resultados.
Los desencadenadores DML usan las tablas lgicas deleted e inserted. Son de
estructura similar a la tabla en que se define el desencadenador, es decir, la tabla en que
se intenta la accin del usuario. Las tablas deleted e inserted guardan los valores
antiguos o nuevos de las filas que la accin del usuario puede cambiar.
Si un desencadenador INSTEAD OF definido en una tabla ejecuta una instruccin en la
tabla que normalmente volvera a activarlo, al desencadenador no se lo llama de forma
recursiva. En su lugar, la instruccin se procesa como si la tabla no tuviera un
desencadenador INSTEAD OF e inicia la cadena de operaciones de restriccin y
175
ejecuciones de desencadenadores AFTER. Por ejemplo, si para una tabla se define un
desencadenador como INSTEAD OF INSERT, y ste ejecuta una instruccin INSERT en
la misma tabla, la instruccin INSERT ejecutada por el desencadenador INSTEAD OF no
vuelve a llamar al desencadenador. La instruccin INSERT ejecutada por el
desencadenador inicia el proceso que realiza las acciones de restriccin y activa cualquier
desencadenador AFTER INSERT definido para la tabla.
Si un desencadenador INSTEAD OF definido en una vista ejecuta una instruccin en la
vista que normalmente volvera a activarlo, no se llamar el desencadenador de forma
recursiva. En su lugar, la instruccin se resuelve a modo de modificaciones en las tablas
base subyacentes de la vista. En este caso, la definicin de la vista debe cumplir todas las
restricciones para una vista actualizable.
Aunque una instruccin TRUNCATE TABLE es en realidad un desencadenador
DELETE, no puede activar un desencadenador porque la operacin no registra las
eliminaciones de fila individuales.
Las siguientes instrucciones Transact-SQL no estn permitidas en un desencadenador
DML:
ALTER DATABASE CREATE DATABASE DROP DATABASE
Adems, las siguientes instrucciones Transact-SQL no se permiten en el cuerpo de un
desencadenador DML cuando ste se utiliza en la tabla o vista que es objeto de la accin
desencadenadora:
CREATE INDEX ALTER INDEX DROP INDEX DROP TABLE
ALTER TABLE cuando se utiliza para hacer lo siguiente:
Agregar, modificar o quitar columnas.
Cambiar particiones.
Agregar o quitar restricciones de tipo PRIMARY KEY o UNIQUE.
Ejemplo:
USE Gestion8
GO
CREATE TRIGGER ActualizaVentasEmpleados
ON pedidos FOR INSERT
AS
UPDATE empleados SET ventas=ventas+inserted.importe
FROM empleados, inserted
WHERE numemp=inserted.rep;
GO
Unidad 9. Programacin en TRANSACT SQL (IX)
Cuando se INSERTe un pedido, entrar en funcionamiento el trigger
ActualizaVentasEmpleado y se ejecutarn las instrucciones que aparecen despus de AS,
en este caso actualizar (UPDATE) la tabla empleados sumar a las ventas del empleado
(ventas) el importe del pedido insertado (inserted.importe), y slo actualizar el empleado
176
cuyo numemp coincida con el campo rep del pedido insertado (WHERE
numemp=inserted.rep).
-- Ahora comprobamos que funciona
SELECT * FROM empleados WHERE numemp=108;
INSERT INTO pedidos
(numpedido,fechapedido,rep,clie,cant,importe,fab,producto)
VALUES
(123456789,getdate(),108,2103,10,100,'Aci',41001)
SELECT * FROM empleados WHERE numemp=108;
Vemos que al insertar un pedido de 100 del empleado 108, sus ventas han
aumentado en 100.
ALTER TRIGGER
Permite modificar la definicin del desencadenador, no permite cambiar su nombre,
para cambiar el nombre de un desencadenador hay que eliminarlo (DROP TRIGGER) y
volver a crearlo (CREATE TRIGGER).
ALTER TRIGGER [NombreEsquema.]NombreTrigger
ON {tabla|vista}
{FOR|AFTER|INSTEAD OF} {[INSERT][,][UPDATE][,][DELETE]} [WITH
APPEND]
AS sentencia_sql [;] [,...n ]
La sintaxis es similar a la instruccin CREATE TRIGGER.
Ejemplo:
ALTER TRIGGER ActualizaVentasEmpleados
ON pedidos FOR INSERT
AS
UPDATE empleados SET ventas=ventas+inserted.importe
FROM empleados, inserted
WHERE numemp=inserted.rep AND inserted.importe IS NOT NULL;
Hemos modificado el desencadenador para que si el importe del pedido es nulo, no
haga nada, no actualice con un valor nulo.
Realiza el siguiente Ejercicio Triggers para practicar la creacin de
desencadenadores.
9.13. DISABLE TRIGGER
En ocasiones puede ser til inhabilitar temporalmente un desencadenador sin que por
ello suponga eliminarlo, para estos casos podemos utilizar la sentencia DISABLE
TRIGGER.
177
DISABLE TRIGGER {[NombreEsquema.]NombreTrigger [,...n] | ALL }
ON {NombreTablaVista | DATABASE | ALL SERVER} [;]
Ejemplo:
DISABLE TRIGGER ActualizaVentasEmpleado ON pedidos;
Deshabilita el desencadenador que hemos creado anteriormente, si despus de
ejecutar esta sentencia se introduce un nuevo pedido, el empleado correspondiente no se
actualizar.
Lo podemos comprobar con:
SELECT * FROM empleados WHERE numemp=108;
INSERT INTO pedidos
(numpedido,fechapedido,rep,clie,cant,importe,fab,producto)
VALUES
(123456791,getdate(),108,2103,10,300,'Aci',41001)
SELECT * FROM empleados WHERE numemp=108;
DISABLE TRIGGER ALL ON pedidos;
Deshabilita todos los desencadenadores asociados a la tabla pedidos.
DISABLE TRIGGER ALL ON DATABASE;
Deshabilita todos los desencadenadores definidos en la base de datos actual.
DISABLE TRIGGER ALL ON ALL SERVER;
Deshabilita todos los desencadenadores definidos en el servidor.
Unidad 9. Programacin en TRANSACT SQL (X)
9.14. ENABLE TRIGGER
Con esta instruccin volvemos a habilitar los desencadenadores desactivados por la
instruccin anterior.
ENABLE TRIGGER {[NombreEsquema.]NombreTrigger [,...n] | ALL }
ON {NombreTablaVista | DATABASE | ALL SERVER} [ ; ]
Funciona de la misma manera que DISABLE TRIGGER pero habilita en vez de
deshabilitar.
Con este ejemplo lo podemos comprobar:
178
ENABLE TRIGGER ActualizaVentasEmpleados ON pedidos;
SELECT * FROM empleados WHERE numemp=108;
INSERT INTO pedidos
(numpedido,fechapedido,rep,clie,cant,importe,fab,producto)
VALUES (123456792,getdate(),108,2103,10,400,'Aci',41001)
SELECT * FROM empleados WHERE numemp=108;
9.15. DROP TRIGGER
Para eliminar un desencadenador tenemos la instruccin DROP TRIGGER elimina la
definicin del desencadenador.
DROP TRIGGER NombreEsquema.NombreTrigger [,...n] [;]
Ejemplo:
DROP TRIGGER ActualizaVentasEmpleados
Elimina el desencadenador ActualizaVentasEmpleados.
Вам также может понравиться
- DATABASE - Del modelo conceptual a la aplicación final en Access, Visual Basic, Pascal, Html y PhpОт EverandDATABASE - Del modelo conceptual a la aplicación final en Access, Visual Basic, Pascal, Html y PhpОценок пока нет
- Examen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2От EverandExamen Profesional Certificado de Nube AWS Guía de Éxito 2: Examen Profesional Certificado de Nube AWS Guía de Éxito, #2Оценок пока нет
- SQL AulaclicДокумент2 страницыSQL AulaclicGuidoGuirozzОценок пока нет
- 1-Consultas Avanzadas Con T-SQLДокумент37 страниц1-Consultas Avanzadas Con T-SQLDavid CobeñasОценок пока нет
- Guia SQL ServerДокумент19 страницGuia SQL ServerManuelОценок пока нет
- Explicacion Visual Del JOIN en SQL - Jeff Atwood - 2007Документ3 страницыExplicacion Visual Del JOIN en SQL - Jeff Atwood - 2007FedericoОценок пока нет
- El Lenguaje SQL (DML - Subconsultas)Документ158 страницEl Lenguaje SQL (DML - Subconsultas)Gustavo PinoОценок пока нет
- SQL FuncionesДокумент33 страницыSQL FuncionesKenny GpzОценок пока нет
- Intro DMLДокумент29 страницIntro DMLFran RguezОценок пока нет
- SQL Server 2012 Administración de Una Base de Datos Transaccional Con SQL Server Management StudioДокумент14 страницSQL Server 2012 Administración de Una Base de Datos Transaccional Con SQL Server Management StudioDiego Fernando Marin Marin0% (4)
- Fundamentos de SQL EJEMPLOSДокумент33 страницыFundamentos de SQL EJEMPLOScintya100% (1)
- Base de Datos - TriggersДокумент16 страницBase de Datos - TriggersRonaldRoldánSalinasОценок пока нет
- SQL ProntuarioДокумент10 страницSQL ProntuarioDani MatiОценок пока нет
- Practicas SubconsultasДокумент21 страницаPracticas SubconsultasKamil SolОценок пока нет
- Guia TriggersДокумент8 страницGuia TriggersAndresHuamanChamorroОценок пока нет
- Curso Básico de ReporteadorV14Документ42 страницыCurso Básico de ReporteadorV14EstefannyMarОценок пока нет
- Cursores en Transact - SQLДокумент28 страницCursores en Transact - SQLchabucaloca100% (1)
- Temario Curso de Microsoft SQL Server PDFДокумент2 страницыTemario Curso de Microsoft SQL Server PDFErik Wong CamaraОценок пока нет
- Consultas Múltiples en OracleДокумент13 страницConsultas Múltiples en Oraclejchoque314100% (1)
- Base de Datos ExcelДокумент15 страницBase de Datos ExcelIsa BelОценок пока нет
- Tutorial JSPДокумент131 страницаTutorial JSPEst DleoОценок пока нет
- Subconsultas en El Lenguaje SQLДокумент9 страницSubconsultas en El Lenguaje SQLDianitaPrincesОценок пока нет
- BD Diseno Conceptual Logico FisicoДокумент38 страницBD Diseno Conceptual Logico FisicodhexsoftОценок пока нет
- Construccion Base de Datos GuiaДокумент5 страницConstruccion Base de Datos GuiaCarlos CañonОценок пока нет
- SQL SubconsultasДокумент4 страницыSQL SubconsultasAngie RomanaОценок пока нет
- Ejercicios PLSQLДокумент6 страницEjercicios PLSQLJulioОценок пока нет
- Curso de Transact SQL Server 2014 PDFДокумент74 страницыCurso de Transact SQL Server 2014 PDFLuis Anronio Rivas AlgueidaОценок пока нет
- Tutorial PL SQLДокумент53 страницыTutorial PL SQLanarkia54Оценок пока нет
- Ejercicios - SQL PracticosДокумент6 страницEjercicios - SQL PracticosXavi LunaОценок пока нет
- Practica SQLДокумент6 страницPractica SQLROLANDOОценок пока нет
- Gestión de empleados en PL/SQLДокумент8 страницGestión de empleados en PL/SQLquestionОценок пока нет
- 7 - Guía MySQLДокумент48 страниц7 - Guía MySQLMahfiebd0% (1)
- Manual de SQL Server 2014Документ37 страницManual de SQL Server 2014JorgeBeristain100% (1)
- SQL Server Integration ServicesДокумент16 страницSQL Server Integration Servicesluisangel_0387Оценок пока нет
- Edgar Moreno Palma - Práctica 6 Diplomado Oracle 11gДокумент8 страницEdgar Moreno Palma - Práctica 6 Diplomado Oracle 11gEdgarAlbertoОценок пока нет
- Ejercicios ImpressДокумент4 страницыEjercicios ImpressLuis Saravia100% (1)
- Prontuario OracleДокумент20 страницProntuario OracleHéctor Apolinar100% (1)
- Tema5 SQLДокумент95 страницTema5 SQLSkylar Knight100% (1)
- TT Cubos de Información OLAPДокумент122 страницыTT Cubos de Información OLAPSergio LandinОценок пока нет
- Conceptos Básicos de Bases de DatosДокумент9 страницConceptos Básicos de Bases de DatossonyОценок пока нет
- Oracle - Prctica 1Документ12 страницOracle - Prctica 1javiersinho08100% (1)
- Ejercicios Con Sentencias SQLДокумент15 страницEjercicios Con Sentencias SQLFrancisco Hernan'Оценок пока нет
- SQL Consultas Base DatosДокумент8 страницSQL Consultas Base DatosAlex CarreraОценок пока нет
- Guia SQL DMLДокумент9 страницGuia SQL DMLIvan Carrera SkОценок пока нет
- Normalización de Base de Datos RelacionalesДокумент10 страницNormalización de Base de Datos Relacionalesantony.marco7Оценок пока нет
- Silabo Análisis y Visualización de Datos Con Power BiДокумент2 страницыSilabo Análisis y Visualización de Datos Con Power BiERIC ALBERTO HEREDIA MENDOZAОценок пока нет
- Sesion 04 - Modelamiento de Datos IДокумент39 страницSesion 04 - Modelamiento de Datos IMARTA LAURA ROSALES ARIASОценок пока нет
- CUBOДокумент23 страницыCUBOMichael Quispe SanchezОценок пока нет
- Manual de Los Curso T-SQLДокумент107 страницManual de Los Curso T-SQLambarcita06Оценок пока нет
- Práctica 1: Consultas SELECT básicasДокумент4 страницыPráctica 1: Consultas SELECT básicasmarisolОценок пока нет
- Ingenieria Requerimientos v2Документ225 страницIngenieria Requerimientos v2Oscar HunterОценок пока нет
- SQL - Sentencias BasicasДокумент31 страницаSQL - Sentencias BasicasmeОценок пока нет
- Presentación MongoDBДокумент12 страницPresentación MongoDBJose SalazarОценок пока нет
- Deber Pay TriggersДокумент27 страницDeber Pay Triggerserick joel jara vegaОценок пока нет
- Lab 03 Consultas AvanzadasДокумент36 страницLab 03 Consultas AvanzadasMayte NicohlОценок пока нет
- Introducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2От EverandIntroducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2Оценок пока нет
- Curso de SQL ServerДокумент178 страницCurso de SQL ServerJosé Obeniel LópezОценок пока нет
- Memoria Histórica Sobre La Corrupción en El Perú PDFДокумент6 страницMemoria Histórica Sobre La Corrupción en El Perú PDFHeydi Scarlett Valladolid RiveraОценок пока нет
- Ideologías Del Siglo Xix-20marzoДокумент5 страницIdeologías Del Siglo Xix-20marzoRene DCОценок пока нет
- Arquitectura de ComputadoresДокумент19 страницArquitectura de ComputadoresRene DCОценок пока нет
- La VideoconferenciaДокумент13 страницLa VideoconferenciaMelvyn Cachi ZОценок пока нет
- Dirección Estratégica de RRHHДокумент20 страницDirección Estratégica de RRHHRene DCОценок пока нет
- GMD IndraДокумент41 страницаGMD IndraRene DCОценок пока нет
- Informe - Textil y Confeccion en Peru - 11532Документ40 страницInforme - Textil y Confeccion en Peru - 11532Rene DCОценок пока нет
- PMI - 10-GestionCalidadДокумент66 страницPMI - 10-GestionCalidadRene DCОценок пока нет
- Caso Practico Analisis de Un SigДокумент42 страницыCaso Practico Analisis de Un SigRene DCОценок пока нет
- Ciclo de Vida de Un Sistema de InformaciónДокумент5 страницCiclo de Vida de Un Sistema de InformaciónCanel Gomez ErvinОценок пока нет
- 1ro, 2do, 3er Militarismo-HpДокумент7 страниц1ro, 2do, 3er Militarismo-HpRene DCОценок пока нет
- Como Estructurar Un Informe TecnicoДокумент2 страницыComo Estructurar Un Informe TecnicoRückseiteA.MatosОценок пока нет
- Matriz de La Gran Estrategia (GE)Документ15 страницMatriz de La Gran Estrategia (GE)Rene DCОценок пока нет
- Ee 24 El Fraude Sobre Los Ninos IndigoДокумент2 страницыEe 24 El Fraude Sobre Los Ninos IndigoRene DCОценок пока нет
- Informacion SerpostДокумент52 страницыInformacion SerpostMijail-v OtarolaОценок пока нет
- 5668Документ5 страниц5668Rene DCОценок пока нет
- Ee 24 El Fraude Sobre Los Ninos IndigoДокумент2 страницыEe 24 El Fraude Sobre Los Ninos IndigoRene DCОценок пока нет
- Ee 24 El Fraude Sobre Los Ninos IndigoДокумент2 страницыEe 24 El Fraude Sobre Los Ninos IndigoRene DCОценок пока нет
- Gestion de InventarioДокумент28 страницGestion de InventarioMiguel Angel ZuluОценок пока нет
- Historia de las matemáticas de Tales de MiletoДокумент6 страницHistoria de las matemáticas de Tales de MiletoCesar RieraОценок пока нет
- Crecimiento Del NiñoДокумент7 страницCrecimiento Del NiñoRene DCОценок пока нет
- Historia de las matemáticas de Tales de MiletoДокумент6 страницHistoria de las matemáticas de Tales de MiletoCesar RieraОценок пока нет
- Historia de las matemáticas de Tales de MiletoДокумент6 страницHistoria de las matemáticas de Tales de MiletoCesar RieraОценок пока нет
- 5668Документ5 страниц5668Rene DCОценок пока нет
- Primeros Auxilios para BebesДокумент4 страницыPrimeros Auxilios para BebesRene DCОценок пока нет
- Evolution Comercial DefontanaДокумент5 страницEvolution Comercial DefontanaRene DCОценок пока нет
- Teoria de InventariosДокумент7 страницTeoria de InventariosRene DCОценок пока нет
- La Chica de La Torre de MarfilДокумент1 страницаLa Chica de La Torre de MarfilRene DCОценок пока нет
- Evolution Comercial DefontanaДокумент5 страницEvolution Comercial DefontanaRene DCОценок пока нет
- Examen Parcial 1 BddpaДокумент13 страницExamen Parcial 1 Bddpabenito guzman gonzalezОценок пока нет
- Practicas01 09Документ14 страницPracticas01 09Gustavo SalazarОценок пока нет
- Estructura TripticoДокумент5 страницEstructura Tripticooscar enrique alfaro diazОценок пока нет
- Consultas Simples David RamirezДокумент2 страницыConsultas Simples David RamirezRAMSTEVEN2468Оценок пока нет
- UntitledДокумент16 страницUntitledSol PaezОценок пока нет
- Review SQLДокумент12 страницReview SQLJohn WallaceОценок пока нет
- Bases de Datos Académicas y Normas ApaДокумент6 страницBases de Datos Académicas y Normas ApaYudy Vanessa Monroy VaronОценок пока нет
- Historia de los Sistemas de Bases de DatosДокумент132 страницыHistoria de los Sistemas de Bases de DatosMarvin AlfaroОценок пока нет
- TCC Informatica IIДокумент11 страницTCC Informatica II6042020019 JHOJAN JOSE PIÑA GOMEZ ESTUDIANTE ACTIVOОценок пока нет
- Power Bi - Analizar Instrucciones Del SQL Server - EspañolДокумент7 страницPower Bi - Analizar Instrucciones Del SQL Server - EspañoladolfoОценок пока нет
- Funciones GROUP BY, HAVING y ORDER BY en SQLДокумент3 страницыFunciones GROUP BY, HAVING y ORDER BY en SQLJuan Leonardo Medina SanchezОценок пока нет
- Fundamentos SQL - DMLДокумент17 страницFundamentos SQL - DMLMauricio RodríguezОценок пока нет
- Conecta Java y MySQLДокумент3 страницыConecta Java y MySQLSaul Zamarripa RiveraОценок пока нет
- Plan de ProyectoДокумент43 страницыPlan de ProyectoEmerson O. MosqueiraОценок пока нет
- Trigger 180518053438Документ13 страницTrigger 180518053438Master MusicОценок пока нет
- Lab 02 2019-1Документ4 страницыLab 02 2019-1Brigit Trujillo floresОценок пока нет
- Consultas SQLДокумент57 страницConsultas SQLnelson caro yucraОценок пока нет
- Manual de UsuarioДокумент6 страницManual de UsuarioJoy BenitoОценок пока нет
- Ejercicios Expresiones Formatos PostgresДокумент4 страницыEjercicios Expresiones Formatos PostgresAngelSalazarSОценок пока нет
- Creación y uso de vistas en MySQL con menos deДокумент13 страницCreación y uso de vistas en MySQL con menos deJefer Lee ParraОценок пока нет
- Estándares de Programación Oracle v1.1Документ23 страницыEstándares de Programación Oracle v1.1Oscar J Hernández CastilloОценок пока нет
- Auditoria en OracleДокумент16 страницAuditoria en OraclecarpullreОценок пока нет
- Audit LogДокумент11 страницAudit LogWandy Rodriguez GutierrezОценок пока нет
- Examen SQL, SPДокумент4 страницыExamen SQL, SPerick galindo aguilarОценок пока нет
- Ejercicios Extra Realización de Consultas SQLДокумент43 страницыEjercicios Extra Realización de Consultas SQLHumberto LopezОценок пока нет
- Marilen - TrabajoДокумент18 страницMarilen - TrabajoKara TuckerОценок пока нет
- Registros de Usuarios en PHP y Mysql Con Validación de Campos y Activación Por Mail 1Документ50 страницRegistros de Usuarios en PHP y Mysql Con Validación de Campos y Activación Por Mail 1Giovanny RoheОценок пока нет
- Funciones vs Procedimientos Almacenados SQLДокумент15 страницFunciones vs Procedimientos Almacenados SQLBryam Jesus Arias CuellarОценок пока нет
- PSMДокумент2 страницыPSMJairo CarballoОценок пока нет
- Webinar Gratuito: Escanear Vulnerabilidades Web Con Zed Attack ProxyДокумент16 страницWebinar Gratuito: Escanear Vulnerabilidades Web Con Zed Attack ProxyAlonso Eduardo Caballero QuezadaОценок пока нет