Вам также может понравиться
- 05 HWДокумент3 страницы05 HWSandipChowdhuryОценок пока нет
- 04 PPT 4upДокумент8 страниц04 PPT 4upSandipChowdhuryОценок пока нет
- MIPS FSM Diagram!: Cycle 1!Документ1 страницаMIPS FSM Diagram!: Cycle 1!SandipChowdhuryОценок пока нет
- MIPS Datapath (With Exception Handling) !Документ1 страницаMIPS Datapath (With Exception Handling) !SandipChowdhuryОценок пока нет
- 05 BoardДокумент4 страницы05 BoardSandipChowdhuryОценок пока нет
- Lectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"Документ30 страницLectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"SandipChowdhuryОценок пока нет
- 04 PPT 1up PDFДокумент30 страниц04 PPT 1up PDFSandipChowdhuryОценок пока нет
- Lectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"Документ30 страницLectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"SandipChowdhuryОценок пока нет
- 03 HWДокумент3 страницы03 HWSandipChowdhuryОценок пока нет
- 03 LabДокумент8 страниц03 LabSandipChowdhuryОценок пока нет
- 04 BoardДокумент10 страниц04 BoardSandipChowdhuryОценок пока нет
- 02 LabДокумент7 страниц02 LabSandipChowdhuryОценок пока нет
- 1HДокумент8 страниц1HSandipChowdhuryОценок пока нет
- CSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsДокумент8 страницCSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsSandipChowdhuryОценок пока нет
- CSE 30321: Computer Architecture I: LogisticsДокумент3 страницыCSE 30321: Computer Architecture I: LogisticsSandipChowdhuryОценок пока нет
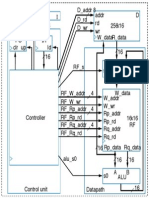
- Notre Dame CSE 30321 Lecture 02-03 Control and DatapathДокумент1 страницаNotre Dame CSE 30321 Lecture 02-03 Control and DatapathSandipChowdhuryОценок пока нет
- 02 HWДокумент6 страниц02 HWSandipChowdhuryОценок пока нет
- 1 LabДокумент10 страниц1 LabSandipChowdhuryОценок пока нет
- From: Subject: Date: To: Reply-ToДокумент1 страницаFrom: Subject: Date: To: Reply-ToSandipChowdhuryОценок пока нет
- Comparator PDFДокумент24 страницыComparator PDFBá Anh ĐàoОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5782)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Debugger Xc800Документ25 страницDebugger Xc800carver_uaОценок пока нет
- SCX6555 Part ListДокумент99 страницSCX6555 Part ListWellington SantosОценок пока нет
- Kyocera-Mita KM3035 Troubleshooting CodesДокумент8 страницKyocera-Mita KM3035 Troubleshooting CodesDezta Hentreza PОценок пока нет
- Dot Net Ieee Project Titles 2017 - 2018: For More Details Contact MR - SARAVANAN - +91 9751812341Документ10 страницDot Net Ieee Project Titles 2017 - 2018: For More Details Contact MR - SARAVANAN - +91 9751812341Kpsmurugesan KpsmОценок пока нет
- Veritas Netbackup (Symantec Netbackup) : What It'S Used ForДокумент3 страницыVeritas Netbackup (Symantec Netbackup) : What It'S Used Forrhel tech07Оценок пока нет
- How To Open NEF Files in Photoshop (CS5) - Photography ForumДокумент6 страницHow To Open NEF Files in Photoshop (CS5) - Photography ForumSamson HaileyesusОценок пока нет
- Ran SharingДокумент69 страницRan SharingBegumKarabatak100% (2)
- Idirect Evolution XLC 11 Data SheetДокумент1 страницаIdirect Evolution XLC 11 Data SheetАнатолий МаловОценок пока нет
- QlikView Connector ManualДокумент100 страницQlikView Connector Manualhergamia9872Оценок пока нет
- ZTE UMTS UR15 NodeB Narrow Band Interference Cancellation Feature GuideДокумент14 страницZTE UMTS UR15 NodeB Narrow Band Interference Cancellation Feature GuideMuhammad HarisОценок пока нет
- System Analysis & DesignДокумент2 страницыSystem Analysis & DesignBijay Mishra0% (1)
- Website and Search Engine OverviewДокумент11 страницWebsite and Search Engine OverviewYemima HanniОценок пока нет
- ColleagueR18InstallationProcedures 02212013Документ312 страницColleagueR18InstallationProcedures 02212013ugaboogaОценок пока нет
- ZXSDR Series Base Station Configuration and Commissioning PDFДокумент145 страницZXSDR Series Base Station Configuration and Commissioning PDFjuan100% (1)
- BOA Installation Manual V11aДокумент29 страницBOA Installation Manual V11aSANKPLYОценок пока нет
- Changeman Administrator GuideДокумент228 страницChangeman Administrator Guideyang_wang19856844100% (3)
- Music MaestroДокумент12 страницMusic Maestrom00sygrlОценок пока нет
- LTE AcronymsДокумент8 страницLTE AcronymspravinbamburdeОценок пока нет
- E85001-0655 - Signature Series Diagnostic ToolДокумент4 страницыE85001-0655 - Signature Series Diagnostic ToolRavi100% (1)
- Using Urls in Cognos 8Документ20 страницUsing Urls in Cognos 8ijagdishraiОценок пока нет
- Smart Restaurant Menu Ordering SystemДокумент27 страницSmart Restaurant Menu Ordering SystemŚowmyà ŚrìОценок пока нет
- Seminario 1 - WiresharkДокумент9 страницSeminario 1 - WiresharkAlvaro WantedeadoraliveОценок пока нет
- Telecom Basics and Introduction to BSSДокумент8 страницTelecom Basics and Introduction to BSSJustice BaloyiОценок пока нет
- Cdce 62005Документ84 страницыCdce 62005hymavathiparvathalaОценок пока нет
- Optical Fiber Communications OverviewДокумент46 страницOptical Fiber Communications OverviewChakravarthi ChittajalluОценок пока нет
- Secure File Folder Access WindowsДокумент58 страницSecure File Folder Access Windowsviknesh61191Оценок пока нет
- DQM SetupДокумент3 страницыDQM Setupzafar.ccna1178Оценок пока нет
- Goofle How To ChartsДокумент3 страницыGoofle How To ChartsPranay MadanОценок пока нет
- FIN 2100 Module 2 Capital Financial Analysis WorksheetДокумент1 460 страницFIN 2100 Module 2 Capital Financial Analysis Worksheetsherif_awadОценок пока нет