Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5795)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- CWNA Guide To Wireless LANs, Second Edition - Ch9Документ3 страницыCWNA Guide To Wireless LANs, Second Edition - Ch9NickHenry100% (1)
- 05 HWДокумент3 страницы05 HWSandipChowdhuryОценок пока нет
- MIPS Datapath (With Exception Handling) !Документ1 страницаMIPS Datapath (With Exception Handling) !SandipChowdhuryОценок пока нет
- MIPS FSM Diagram!: Cycle 1!Документ1 страницаMIPS FSM Diagram!: Cycle 1!SandipChowdhuryОценок пока нет
- Lectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"Документ30 страницLectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"SandipChowdhuryОценок пока нет
- CSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsДокумент8 страницCSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsSandipChowdhuryОценок пока нет
- CSE 30321: Computer Architecture I: LogisticsДокумент3 страницыCSE 30321: Computer Architecture I: LogisticsSandipChowdhuryОценок пока нет
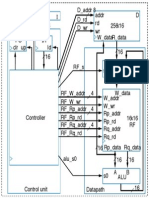
- Control Unit and Datapath For 3-Instruction Processor!Документ1 страницаControl Unit and Datapath For 3-Instruction Processor!SandipChowdhuryОценок пока нет
- From: Subject: Date: To: Reply-ToДокумент1 страницаFrom: Subject: Date: To: Reply-ToSandipChowdhuryОценок пока нет
- 1HДокумент8 страниц1HSandipChowdhuryОценок пока нет
- Indice AashtoДокумент71 страницаIndice AashtoFranklinОценок пока нет
- Exchange 2003 Backup Restore & RecoveryДокумент64 страницыExchange 2003 Backup Restore & RecoveryRajeev KumarОценок пока нет
- SSD Case StudyДокумент2 страницыSSD Case StudyRuthwik S GowdaОценок пока нет
- Active Data Guard and Oracle Golden GateДокумент3 страницыActive Data Guard and Oracle Golden GateMahendranath ReddyОценок пока нет
- BSCE Building ScienceДокумент16 страницBSCE Building ScienceMayank BhatnagarОценок пока нет
- Changes in Is 1893 and Is 13920Документ61 страницаChanges in Is 1893 and Is 13920Kamarajan100% (1)
- Cve 2012 6081Документ25 страницCve 2012 6081Miguel LozanoОценок пока нет
- Feng Shui in Modern House Design Searching For The Rationale and Possible Impacts Assessment Author Gunawan Tanuwidjaja Linda OctaviaДокумент9 страницFeng Shui in Modern House Design Searching For The Rationale and Possible Impacts Assessment Author Gunawan Tanuwidjaja Linda OctaviaIuliaОценок пока нет
- OCI TerraformДокумент15 страницOCI Terraformambipac@yahoo.com100% (1)
- 1.1 Expansive SoilДокумент9 страниц1.1 Expansive SoilYatin JethiОценок пока нет
- Ik2-Bam - B2-SC-D-6503 - 02 PDFДокумент1 страницаIk2-Bam - B2-SC-D-6503 - 02 PDFkramlester1982Оценок пока нет
- Obs Admin Guide enДокумент69 страницObs Admin Guide enKlaas SlagerОценок пока нет
- Project Builder Location:: Mahaveer Rich: Mahaveer Group: Geleyara Balaga Layout, Bangalore WestДокумент6 страницProject Builder Location:: Mahaveer Rich: Mahaveer Group: Geleyara Balaga Layout, Bangalore WestVIRUPAKSHA D GoudaОценок пока нет
- BP090&120 50 HZ TechДокумент24 страницыBP090&120 50 HZ Techmauricio.vidalyork6735Оценок пока нет
- BSR 2020 ConstructionДокумент105 страницBSR 2020 ConstructionGihan KarunasingheОценок пока нет
- F25 - FGB Metro Station To Al Qouz LNDL Area 3&4 Dubai Bus Service TimetableДокумент8 страницF25 - FGB Metro Station To Al Qouz LNDL Area 3&4 Dubai Bus Service TimetableDubai Q&AОценок пока нет
- Alstom Stress 3Документ36 страницAlstom Stress 3sivaguruswamy thangaraj100% (1)
- Alcatel-Lucent 7250 SAS: Service Access Switch - Release 2.0Документ6 страницAlcatel-Lucent 7250 SAS: Service Access Switch - Release 2.0Julio C. Jordán AОценок пока нет
- Steel Tips Committee of California Parte 2Документ391 страницаSteel Tips Committee of California Parte 2RigobertoGuerraОценок пока нет
- Flexbeam ManualДокумент8 страницFlexbeam ManualAnonymous 5S5j8wOОценок пока нет
- Ferrous Metals: General Grade Cast IronsДокумент8 страницFerrous Metals: General Grade Cast IronskkamalakannaОценок пока нет
- Road Widening Review and Questionnaire-2010Документ34 страницыRoad Widening Review and Questionnaire-2010Joshua Ceniza100% (1)
- 3 4 2 A ParkinglotdesignДокумент3 страницы3 4 2 A Parkinglotdesignapi-300375532Оценок пока нет
- Answer Key: Diagnostic TestДокумент3 страницыAnswer Key: Diagnostic TestAndreia SantosОценок пока нет
- OSA Express White PaperДокумент12 страницOSA Express White PaperapmountОценок пока нет
- Sand ColumnДокумент16 страницSand ColumnZulfadli MunfazОценок пока нет
- HTML Kodları-Tr - GG - Sitene Ekle - Ana SayfaДокумент85 страницHTML Kodları-Tr - GG - Sitene Ekle - Ana SayfaKenan ÇankayaОценок пока нет
- Hilfe ZF Extranet enДокумент14 страницHilfe ZF Extranet enDejan StevanovicОценок пока нет