Вам также может понравиться
- 05 HWДокумент3 страницы05 HWSandipChowdhuryОценок пока нет
- MIPS FSM Diagram!: Cycle 1!Документ1 страницаMIPS FSM Diagram!: Cycle 1!SandipChowdhuryОценок пока нет
- 03 HWДокумент3 страницы03 HWSandipChowdhuryОценок пока нет
- Lectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"Документ30 страницLectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"SandipChowdhuryОценок пока нет
- 05 BoardДокумент4 страницы05 BoardSandipChowdhuryОценок пока нет
- Lectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"Документ30 страницLectures 02, 03 Introduction To Stored Programs": Suggested Reading:" HP Chapters 1.1-1.3"SandipChowdhuryОценок пока нет
- 04 PPT 4upДокумент8 страниц04 PPT 4upSandipChowdhuryОценок пока нет
- MIPS Datapath (With Exception Handling) !Документ1 страницаMIPS Datapath (With Exception Handling) !SandipChowdhuryОценок пока нет
- 04 BoardДокумент10 страниц04 BoardSandipChowdhuryОценок пока нет
- 02 LabДокумент7 страниц02 LabSandipChowdhuryОценок пока нет
- 02 HWДокумент6 страниц02 HWSandipChowdhuryОценок пока нет
- 03 LabДокумент8 страниц03 LabSandipChowdhuryОценок пока нет
- CSE 30321: Computer Architecture I: LogisticsДокумент3 страницыCSE 30321: Computer Architecture I: LogisticsSandipChowdhuryОценок пока нет
- CSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsДокумент8 страницCSE 30321 - Lecture 02-03 - in Class Example Handout: Discussion - Overview of Stored ProgramsSandipChowdhuryОценок пока нет
- 1 LabДокумент10 страниц1 LabSandipChowdhuryОценок пока нет
- 1Документ12 страниц1SandipChowdhuryОценок пока нет
- 1HДокумент8 страниц1HSandipChowdhuryОценок пока нет
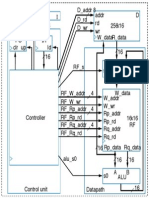
- Notre Dame CSE 30321 Lecture 02-03 Control and DatapathДокумент1 страницаNotre Dame CSE 30321 Lecture 02-03 Control and DatapathSandipChowdhuryОценок пока нет
- From: Subject: Date: To: Reply-ToДокумент1 страницаFrom: Subject: Date: To: Reply-ToSandipChowdhuryОценок пока нет
- Comparator PDFДокумент24 страницыComparator PDFBá Anh ĐàoОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Auto Recloser GEДокумент36 страницAuto Recloser GERamzan QureshiОценок пока нет
- Switching Power SupplyДокумент138 страницSwitching Power SupplyStephen Dunifer95% (22)
- BE 5 UnitДокумент23 страницыBE 5 Unit08sunnyjaganОценок пока нет
- 74HC HCT4851 Q100Документ19 страниц74HC HCT4851 Q100Albaro LedesmaОценок пока нет
- AntennaДокумент8 страницAntennaKimberly Joy FerrerОценок пока нет
- 6264Документ8 страниц6264api-3711187Оценок пока нет
- P72x - EN T - C21 - V11DДокумент334 страницыP72x - EN T - C21 - V11DTlili MahmoudiОценок пока нет
- Electrical PropertiesДокумент4 страницыElectrical PropertiestusharОценок пока нет
- Department of Electronics and Electrical EngineeringДокумент3 страницыDepartment of Electronics and Electrical EngineeringbasabОценок пока нет
- 30V P-Channel MOSFET: Product Summary General DescriptionДокумент5 страниц30V P-Channel MOSFET: Product Summary General DescriptionAndrea CupelloОценок пока нет
- TP 6Документ45 страницTP 6EngrAneelKumarAkhaniОценок пока нет
- Nickel Molybdate Catalysts and Their Use in The Selective Oxidation of HydrocarbonsДокумент60 страницNickel Molybdate Catalysts and Their Use in The Selective Oxidation of HydrocarbonsSandy MartinezОценок пока нет
- Electrical-Engineering Engineering Power-Electronics Inverters NotesДокумент22 страницыElectrical-Engineering Engineering Power-Electronics Inverters NotesAbdelrahman Magdy EbrahimОценок пока нет
- 2014-Green-The Emergence of Perovskite Solar CellsДокумент10 страниц2014-Green-The Emergence of Perovskite Solar CellsChris VilaОценок пока нет
- Shilin Sc3Документ200 страницShilin Sc3Christian JacoboОценок пока нет
- Chapter07 - Electronic Analysis of CMOS Logic GatesДокумент38 страницChapter07 - Electronic Analysis of CMOS Logic GatesRenukaОценок пока нет
- Experiment SuperpositionДокумент6 страницExperiment SuperpositionShara Maica Sincioco SalvadorОценок пока нет
- ARC LS22 Schematic and PartsДокумент7 страницARC LS22 Schematic and PartsarfoceОценок пока нет
- STK621-043A-E: Air Conditioner Three-Phase Compressor Motor Driver IMST Inverter Power Hybrid ICДокумент8 страницSTK621-043A-E: Air Conditioner Three-Phase Compressor Motor Driver IMST Inverter Power Hybrid ICjicoelhoОценок пока нет
- Open Circuit Saturation Curve of An Alternator-EXPT8Документ2 страницыOpen Circuit Saturation Curve of An Alternator-EXPT8Karl Joseph Chua Villariña100% (3)
- Why Are Transformer and Alternator Ratings in KVA On ShipsДокумент18 страницWhy Are Transformer and Alternator Ratings in KVA On Shipsravi_92Оценок пока нет
- Knowles MLC Catalogue 2016Документ102 страницыKnowles MLC Catalogue 2016SalvadorОценок пока нет
- That 1246Документ8 страницThat 1246João PauloОценок пока нет
- Automobile Parking ControlДокумент4 страницыAutomobile Parking ControlHussam AlwareethОценок пока нет
- Kaneyuki Kurokawa Received A B.S. Degree in Electrical Engineering in 1951 and A Ph.D. DegreeДокумент2 страницыKaneyuki Kurokawa Received A B.S. Degree in Electrical Engineering in 1951 and A Ph.D. DegreethgnguyenОценок пока нет
- Westinghouse Ds and DSL Low Voltage Power Circuit Breakers and Cell PartsДокумент28 страницWestinghouse Ds and DSL Low Voltage Power Circuit Breakers and Cell PartsRodney PimentaОценок пока нет
- Electrical Transport MechanismsДокумент106 страницElectrical Transport MechanismslindaОценок пока нет
- Electrical Transmission and Distribution System and DesignДокумент67 страницElectrical Transmission and Distribution System and DesignAdrian Toribio100% (3)
- BJT FundamentalsДокумент33 страницыBJT FundamentalsSamreen ShabbirОценок пока нет