Вам также может понравиться
- Cloud Computing Made Simple: Navigating the Cloud: A Practical Guide to Cloud ComputingОт EverandCloud Computing Made Simple: Navigating the Cloud: A Practical Guide to Cloud ComputingОценок пока нет
- Exam AZ 900: Azure Fundamental Study Guide-1: Explore Azure Fundamental guide and Get certified AZ 900 examОт EverandExam AZ 900: Azure Fundamental Study Guide-1: Explore Azure Fundamental guide and Get certified AZ 900 examОценок пока нет
- Attribute-Based Access Control With Constant-Size Ciphertext in Cloud ComputingДокумент14 страницAttribute-Based Access Control With Constant-Size Ciphertext in Cloud ComputingGateway ManagerОценок пока нет
- Abstract of Cloud ComputingДокумент6 страницAbstract of Cloud ComputingJanaki JanuОценок пока нет
- Sagar de Duplication PaperДокумент2 страницыSagar de Duplication PaperK V D SagarОценок пока нет
- The Incremental Load Balance Cloud Algorithm by Using Dynamic Data DeploymentДокумент2 страницыThe Incremental Load Balance Cloud Algorithm by Using Dynamic Data Deploymentgetachew mengstieОценок пока нет
- 8.IJAEST Vol No 5 Issue No 2 Achieving Availability, Elasticity and Reliability of The Data Access in Cloud Computing 150 155Документ6 страниц8.IJAEST Vol No 5 Issue No 2 Achieving Availability, Elasticity and Reliability of The Data Access in Cloud Computing 150 155noddynoddyОценок пока нет
- Cloud Computing: Case Studies and Total Costs of Ownership - ProQuestДокумент8 страницCloud Computing: Case Studies and Total Costs of Ownership - ProQuestHanggara Willy0% (1)
- Term Paper On Cloud ComputingДокумент14 страницTerm Paper On Cloud ComputingShifath Shams50% (2)
- Cloud Computing DocumentationДокумент11 страницCloud Computing DocumentationSailaja MannemОценок пока нет
- Sscloud: A Smart Storage For Distributed Daas On The CloudДокумент4 страницыSscloud: A Smart Storage For Distributed Daas On The CloudddaaОценок пока нет
- Towards Secure and Dependable Storage Services in Cloud ComputingДокумент14 страницTowards Secure and Dependable Storage Services in Cloud ComputingRaghuram SeshabhattarОценок пока нет
- I J E C B S Issn (O) : 2230-8849: Cloud Computing: An AnalysisДокумент15 страницI J E C B S Issn (O) : 2230-8849: Cloud Computing: An AnalysisnoddynoddyОценок пока нет
- Unit 4 Infrastructure As A ServiceДокумент37 страницUnit 4 Infrastructure As A ServiceTarun SinghОценок пока нет
- Cloud Computing: A CRM Service Based On A Separate Encryption and Decryption Using Blowfish AlgorithmДокумент5 страницCloud Computing: A CRM Service Based On A Separate Encryption and Decryption Using Blowfish Algorithmsurendiran123Оценок пока нет
- Review of Cloud ComputingДокумент4 страницыReview of Cloud ComputingijsretОценок пока нет
- A Hybrid Algorithm For Scheduling ScientificДокумент44 страницыA Hybrid Algorithm For Scheduling Scientificmohamed fathimaОценок пока нет
- Unit 5 Cloud ComputingДокумент12 страницUnit 5 Cloud ComputingvibhamanojОценок пока нет
- Cloud Computing Architecture& Services: Manju Sharma, Sadia Husain, Halah ZainДокумент6 страницCloud Computing Architecture& Services: Manju Sharma, Sadia Husain, Halah Zainelangolatha5Оценок пока нет
- Assignment: Q1. What Is Cloud Computing? AnsДокумент8 страницAssignment: Q1. What Is Cloud Computing? Ansvashishttyagi91Оценок пока нет
- Cloud Computing: Submitted By: Divya Khandelwal B.Tech (CSE) 7 Sem 0271352707Документ31 страницаCloud Computing: Submitted By: Divya Khandelwal B.Tech (CSE) 7 Sem 0271352707divya25sepОценок пока нет
- Cloud Computing: The Beginning of A New EraДокумент6 страницCloud Computing: The Beginning of A New EraArun KumarОценок пока нет
- Cloud Computing Relies On Restricting Sharing of Resources To Achieve Coherence and Economies of ScaleДокумент13 страницCloud Computing Relies On Restricting Sharing of Resources To Achieve Coherence and Economies of Scaleharshitasarraf13Оценок пока нет
- I J E C B S: Cloud Computing: An AnalysisДокумент16 страницI J E C B S: Cloud Computing: An Analysisadmin2146Оценок пока нет
- What Is Cloud Computing? Cloud Computing Is The Use of Computing Resources (Hardware andДокумент74 страницыWhat Is Cloud Computing? Cloud Computing Is The Use of Computing Resources (Hardware andSanda MounikaОценок пока нет
- Introduction Cloud ComputingДокумент7 страницIntroduction Cloud ComputingsuhradamОценок пока нет
- Introduction To Cloud ComputingДокумент36 страницIntroduction To Cloud ComputingAjay KakkarОценок пока нет
- Database Consolidation Onto Private Clouds: An Oracle White Paper October 2011Документ18 страницDatabase Consolidation Onto Private Clouds: An Oracle White Paper October 2011gerkillОценок пока нет
- Database Consolidation Onto Private Clouds: An Oracle White Paper October 2011Документ18 страницDatabase Consolidation Onto Private Clouds: An Oracle White Paper October 2011Rosario Carmen Salazar OrtizОценок пока нет
- Topic:Cloud Computing Name:Aksa Kalsoom Submitted To:Sir Amir Taj Semester:7 ROLL# 11PWBCS0276 Section:BДокумент6 страницTopic:Cloud Computing Name:Aksa Kalsoom Submitted To:Sir Amir Taj Semester:7 ROLL# 11PWBCS0276 Section:BlailaaabidОценок пока нет
- Cache Performance Based On Response Time and Cost Effectivein Cloud ComputingДокумент10 страницCache Performance Based On Response Time and Cost Effectivein Cloud ComputingInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Cloud Computing: A Perspective Study: Received 1 Dec 2008Документ10 страницCloud Computing: A Perspective Study: Received 1 Dec 2008krmrzaОценок пока нет
- CYRUS: Towards Client-Defined Cloud Storage: Jae Yoon Chung Carlee Joe-Wong Sangtae HaДокумент16 страницCYRUS: Towards Client-Defined Cloud Storage: Jae Yoon Chung Carlee Joe-Wong Sangtae HaGonzalo MartinezОценок пока нет
- Layers of Cloud IaaS PaaS and SaaS A SurДокумент4 страницыLayers of Cloud IaaS PaaS and SaaS A SurSimonohioОценок пока нет
- Cloud Computing: An Overview: Charandeep Singh Bedi, Rajan SachdevaДокумент10 страницCloud Computing: An Overview: Charandeep Singh Bedi, Rajan SachdevaCharndeep BediОценок пока нет
- Azure 4Документ5 страницAzure 4SarahОценок пока нет
- Cloud ComputingДокумент8 страницCloud ComputingArun KafleyОценок пока нет
- Cloud ComputingДокумент13 страницCloud Computingabdul raufОценок пока нет
- Mi AssignmentДокумент11 страницMi AssignmentVarun MavaniОценок пока нет
- Amazon Web ServicesДокумент85 страницAmazon Web ServicesSrinivasa Reddy KarriОценок пока нет
- Term Paper Cloud ComputingДокумент11 страницTerm Paper Cloud Computingkuntal Roy Animation WorldОценок пока нет
- Amazon Web ServicesДокумент96 страницAmazon Web Servicesmihirmmb100% (1)
- Architecture & ConsiderationДокумент7 страницArchitecture & Consideration18941Оценок пока нет
- Assignment On Benefits of Cloud ComputingДокумент8 страницAssignment On Benefits of Cloud ComputingMonir HossainОценок пока нет
- Taxonomy For Cloud ComputingДокумент4 страницыTaxonomy For Cloud ComputingFiona YvetteОценок пока нет
- Chapter 1Документ57 страницChapter 1Kalyan Reddy AnuguОценок пока нет
- Cloud Computing - PrashantДокумент6 страницCloud Computing - PrashantSachin MauryaОценок пока нет
- Database Management System As A Cloud ServiceДокумент13 страницDatabase Management System As A Cloud Serviceengineeringwatch100% (1)
- Move Into The Cloud, Shall We?: Sharon Q. YangДокумент4 страницыMove Into The Cloud, Shall We?: Sharon Q. YangAsim IshaqОценок пока нет
- Amazon Web Services: An Overview: Expert Reference Series of White PapersДокумент8 страницAmazon Web Services: An Overview: Expert Reference Series of White PapersAadi ManchandaОценок пока нет
- Cloud Computing An IntroductionДокумент39 страницCloud Computing An Introductionsrishtityagi2020Оценок пока нет
- بحث كوكيДокумент2 страницыبحث كوكيHarvey SpecterОценок пока нет
- Tech Literature Review: Cloud ComputingДокумент8 страницTech Literature Review: Cloud ComputingPulla raoОценок пока нет
- A Technical Seminar Report ON Cloud Computing: D. Sai Krishna. (2220212108)Документ19 страницA Technical Seminar Report ON Cloud Computing: D. Sai Krishna. (2220212108)srgupta99Оценок пока нет
- IT702 CloudComputing AssignmentДокумент17 страницIT702 CloudComputing AssignmentSurya PratapОценок пока нет
- Minimum-Cost Cloud Storage Service Across Multiple Cloud ProvidersДокумент10 страницMinimum-Cost Cloud Storage Service Across Multiple Cloud ProvidersajithОценок пока нет
- Simple But Comprehensive Study On Cloud StorageДокумент5 страницSimple But Comprehensive Study On Cloud Storagepenumudi233Оценок пока нет
- Virtualizing The Private Cloud For Maximum Resource UtilizationДокумент5 страницVirtualizing The Private Cloud For Maximum Resource UtilizationIjarcet JournalОценок пока нет
- Cloud Computing: Harnessing the Power of the Digital Skies: The IT CollectionОт EverandCloud Computing: Harnessing the Power of the Digital Skies: The IT CollectionОценок пока нет
- Azure Unleashed: Harnessing Microsoft's Cloud Platform for Innovation and GrowthОт EverandAzure Unleashed: Harnessing Microsoft's Cloud Platform for Innovation and GrowthОценок пока нет
- Electrical Machines I: Week 13: Ward Leonard Speed Control and DC Motor BrakingДокумент15 страницElectrical Machines I: Week 13: Ward Leonard Speed Control and DC Motor Brakingmansoor.ahmed100Оценок пока нет
- 1Документ18 страниц1Mansoor AhmedОценок пока нет
- Lab 3Документ5 страницLab 3mansoor.ahmed100Оценок пока нет
- MS Electrical (Control) EngineeringДокумент34 страницыMS Electrical (Control) Engineeringmansoor.ahmed100Оценок пока нет
- AtenolДокумент6 страницAtenolmansoor.ahmed100Оценок пока нет
- T=K ϕ I E E I R N= E K ϕ T=K I: Separately Excited DC Motor Series DC MotorДокумент2 страницыT=K ϕ I E E I R N= E K ϕ T=K I: Separately Excited DC Motor Series DC Motormansoor.ahmed100Оценок пока нет
- Notice: All The Images in This VTP LAB Are Used For Demonstration Only, You Will See Slightly Different Images in The Real CCNA ExamДокумент14 страницNotice: All The Images in This VTP LAB Are Used For Demonstration Only, You Will See Slightly Different Images in The Real CCNA Exammansoor.ahmed100Оценок пока нет
- 3102 WorkbookДокумент153 страницы3102 Workbookmansoor.ahmed100Оценок пока нет
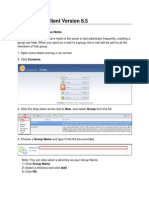
- Lotus Notes Client Version 8.5Документ4 страницыLotus Notes Client Version 8.5mansoor.ahmed100Оценок пока нет
- Smart Sheet: GERRYS INFORMATION TECHNOLOGY - Escalation List & Contact InformationДокумент1 страницаSmart Sheet: GERRYS INFORMATION TECHNOLOGY - Escalation List & Contact Informationmansoor.ahmed100Оценок пока нет
- 3103 WorkbookДокумент91 страница3103 Workbookmansoor.ahmed100Оценок пока нет
- LogitechДокумент11 страницLogitechmansoor.ahmed100Оценок пока нет
- PDC PmphandbookДокумент0 страницPDC PmphandbookAhmed FoudaОценок пока нет
- Practice Problem 2 - SolutionДокумент14 страницPractice Problem 2 - Solutionmansoor.ahmed100Оценок пока нет
- Extrusion Detection System: Problem StatementДокумент3 страницыExtrusion Detection System: Problem Statementmansoor.ahmed100Оценок пока нет
- Practice Problem 2Документ2 страницыPractice Problem 2mansoor.ahmed100Оценок пока нет
- Anomaly in Manet2Документ14 страницAnomaly in Manet2mansoor.ahmed100Оценок пока нет
- Mobile Ad-Hoc and Sensor NetworksДокумент27 страницMobile Ad-Hoc and Sensor Networksmansoor.ahmed100Оценок пока нет
- Paper Title (Use Style: Paper Title) : Subtitle As Needed (Paper Subtitle)Документ3 страницыPaper Title (Use Style: Paper Title) : Subtitle As Needed (Paper Subtitle)mansoor.ahmed100Оценок пока нет
- H.M RashidДокумент10 страницH.M Rashidmansoor.ahmed100Оценок пока нет
- Research Assignment - DetailsДокумент2 страницыResearch Assignment - Detailsmansoor.ahmed100Оценок пока нет
- Extrusion Detection System: Problem StatementДокумент3 страницыExtrusion Detection System: Problem Statementmansoor.ahmed100Оценок пока нет
- Paper Title (Use Style: Paper Title) : Subtitle As Needed (Paper Subtitle)Документ3 страницыPaper Title (Use Style: Paper Title) : Subtitle As Needed (Paper Subtitle)mansoor.ahmed100Оценок пока нет
- Extrusion Detection: Deployment Analysis in Mobile Ad-Hoc NetworksДокумент8 страницExtrusion Detection: Deployment Analysis in Mobile Ad-Hoc Networksmansoor.ahmed100Оценок пока нет
- A Study of Linux File System EvolutionДокумент14 страницA Study of Linux File System EvolutionVictor LyapunovОценок пока нет
- Redhat Linux System Administration Rh133Документ284 страницыRedhat Linux System Administration Rh133Adrian Bravo100% (1)
- FIOS: A Fair, Efficient Flash I/O Scheduler: Stan Park Kai Shen University of RochesterДокумент22 страницыFIOS: A Fair, Efficient Flash I/O Scheduler: Stan Park Kai Shen University of Rochestermansoor.ahmed100Оценок пока нет
- VrableДокумент28 страницVrablemansoor.ahmed100Оценок пока нет
- Chapter 13Документ56 страницChapter 13mansoor.ahmed100Оценок пока нет
- Radio Protection ChallengesДокумент31 страницаRadio Protection ChallengesJackssonОценок пока нет
- NKU Athletic Director Ken Bothof DepositionДокумент76 страницNKU Athletic Director Ken Bothof DepositionJames PilcherОценок пока нет
- Walmart Assignment1Документ13 страницWalmart Assignment1kingkammyОценок пока нет
- Cluster of Business and Management: BBAW 2103 Financial AccountingДокумент13 страницCluster of Business and Management: BBAW 2103 Financial AccountingFreshlynero JonalОценок пока нет
- Project Level 2Документ5 страницProject Level 2Alexa GonzalezОценок пока нет
- Physiotherapy For ChildrenДокумент2 страницыPhysiotherapy For ChildrenCatalina LucaОценок пока нет
- Glgq1g10 Sci Las Set 4 ColoredДокумент4 страницыGlgq1g10 Sci Las Set 4 ColoredPogi AkoОценок пока нет
- PDFДокумент50 страницPDFWalaa RaslanОценок пока нет
- Project Procurement Management: 1 WWW - Cahyo.web - Id IT Project Management, Third Edition Chapter 12Документ28 страницProject Procurement Management: 1 WWW - Cahyo.web - Id IT Project Management, Third Edition Chapter 12cahyodОценок пока нет
- My AnalysisДокумент4 страницыMy AnalysisMaricris CastillanoОценок пока нет
- Instructional Supervisory Plan BITДокумент7 страницInstructional Supervisory Plan BITjeo nalugon100% (2)
- Mock Exam 2Документ18 страницMock Exam 2Anna StacyОценок пока нет
- Detailed Lesson Plan in Tle Grade 8Документ7 страницDetailed Lesson Plan in Tle Grade 8Hanna MikangcrzОценок пока нет
- Program PlanningДокумент24 страницыProgram Planningkylexian1Оценок пока нет
- DonatelloДокумент12 страницDonatelloGiorgia Ronfo SP GironeОценок пока нет
- Integrating Intuition and Analysis Edward Deming Once SaidДокумент2 страницыIntegrating Intuition and Analysis Edward Deming Once SaidRimsha Noor ChaudaryОценок пока нет
- XS2 Pharma 0512 103 UK U-NiДокумент2 страницыXS2 Pharma 0512 103 UK U-NiMilan MilovanovicОценок пока нет
- Jack Pumpkinhead of Oz - L. Frank BaumДокумент68 страницJack Pumpkinhead of Oz - L. Frank BaumbobbyejayneОценок пока нет
- Villa VeronicaДокумент12 страницVilla Veronicacj fontzОценок пока нет
- Introducing Identity - SummaryДокумент4 страницыIntroducing Identity - SummarylkuasОценок пока нет
- Apcr MCR 3Документ13 страницApcr MCR 3metteoroОценок пока нет
- Anchoring ScriptДокумент2 страницыAnchoring ScriptThomas Shelby100% (2)
- Swimming Pool - PWTAG CodeofPractice1.13v5 - 000Документ58 страницSwimming Pool - PWTAG CodeofPractice1.13v5 - 000Vin BdsОценок пока нет
- IJONE Jan-March 2017-3 PDFДокумент140 страницIJONE Jan-March 2017-3 PDFmoahammad bilal AkramОценок пока нет
- Novos Paradigmas em MediaçãoДокумент399 страницNovos Paradigmas em MediaçãoLeticia Trombini Vidotto100% (1)
- Bunescu-Chilimciuc Rodica Perspective Teoretice Despre Identitatea Social Theoretic Perspectives On Social IdentityДокумент5 страницBunescu-Chilimciuc Rodica Perspective Teoretice Despre Identitatea Social Theoretic Perspectives On Social Identityandreea popaОценок пока нет
- Speaking C1Документ16 страницSpeaking C1Luca NituОценок пока нет
- Grammar Exercises AnswersДокумент81 страницаGrammar Exercises Answerspole star107100% (1)
- DLL Ict 9 1st Quarter Week 5Документ3 страницыDLL Ict 9 1st Quarter Week 5Bernadeth Irma Sawal Caballa100% (2)
- Self-Learning Home Task (SLHT) : Key Drawings and Animation BreakdownsДокумент6 страницSelf-Learning Home Task (SLHT) : Key Drawings and Animation BreakdownsRUFINO MEDICOОценок пока нет