Вам также может понравиться
- True or False: StackДокумент15 страницTrue or False: StackAmro AbosaifОценок пока нет
- Unit Ii 9: SyllabusДокумент12 страницUnit Ii 9: SyllabusbeingniceОценок пока нет
- Jim DSA QuestionsДокумент26 страницJim DSA QuestionsTudor CiotloșОценок пока нет
- QuestionsДокумент31 страницаQuestionsHithaishi BathuluriОценок пока нет
- Question Bank (Unit I) Cs6402-Design and Analysis of Algorithms Part - AДокумент12 страницQuestion Bank (Unit I) Cs6402-Design and Analysis of Algorithms Part - Aviju001Оценок пока нет
- Cs1201 Design and Analysis of AlgorithmДокумент27 страницCs1201 Design and Analysis of Algorithmvijay_sudhaОценок пока нет
- DAA 2 MarksДокумент13 страницDAA 2 MarksVds KrishnaОценок пока нет
- Design and Analysis of AlgorithmДокумент20 страницDesign and Analysis of AlgorithmBhagirat DasОценок пока нет
- Analysis and Design of Algorithms PDFДокумент54 страницыAnalysis and Design of Algorithms PDFazmiОценок пока нет
- Cs1201 Design and Analysis of AlgorithmДокумент27 страницCs1201 Design and Analysis of AlgorithmmaharajakingОценок пока нет
- DaaДокумент15 страницDaaSaravanan DevarajОценок пока нет
- Cs2251 - Design and Analysis of Algorithms 2 Marks Questions With AnswersДокумент27 страницCs2251 - Design and Analysis of Algorithms 2 Marks Questions With AnswersMohan MohanbagavathiОценок пока нет
- Design and Analysis of Algorithms Laboratory (15Csl47)Документ12 страницDesign and Analysis of Algorithms Laboratory (15Csl47)Raj vamsi Srigakulam100% (1)
- DAA IA-1 Case Study Material-CSEДокумент9 страницDAA IA-1 Case Study Material-CSEsyed adilОценок пока нет
- DAAQB Test1Документ3 страницыDAAQB Test1Rajesh RajОценок пока нет
- Lab Manual DAA (Shivam 1802636)Документ71 страницаLab Manual DAA (Shivam 1802636)shivam kashyapОценок пока нет
- Design and Analysis of Algorithm Question BankДокумент15 страницDesign and Analysis of Algorithm Question BankGeo ThaliathОценок пока нет
- Cs8451 Design and Analysis of Algorithms: Unit-I Part-A 1. Define AlgorithmДокумент21 страницаCs8451 Design and Analysis of Algorithms: Unit-I Part-A 1. Define Algorithmnavin paskantiОценок пока нет
- Study Material On Data Structure and AlgorithmsДокумент43 страницыStudy Material On Data Structure and AlgorithmsGod is every whereОценок пока нет
- 1 - 1 - Fundamentals - Algorithm - Problem - SlovingДокумент24 страницы1 - 1 - Fundamentals - Algorithm - Problem - SlovingKarthikeyan RVОценок пока нет
- Advanced Analysis of Algorithms: Dr. Javed Iqbal BangashДокумент23 страницыAdvanced Analysis of Algorithms: Dr. Javed Iqbal BangashshahabОценок пока нет
- Daa QB PDFДокумент12 страницDaa QB PDFshri hariОценок пока нет
- 2 - Asymptotic, ComparisionДокумент35 страниц2 - Asymptotic, ComparisionSrinitya SuripeddiОценок пока нет
- ADA Que Bank 2022-2023Документ14 страницADA Que Bank 2022-2023Chavda ShaktisinhОценок пока нет
- University Solution 19-20Документ33 страницыUniversity Solution 19-20picsichubОценок пока нет
- Algorithms AnalysisДокумент40 страницAlgorithms AnalysisImaОценок пока нет
- The Fundamentals: Algorithms The IntegersДокумент55 страницThe Fundamentals: Algorithms The Integersnguyên trần minhОценок пока нет
- Dhanalakshmi College of EngineeringДокумент17 страницDhanalakshmi College of EngineeringRamesh KumarОценок пока нет
- CS2251 Design and Analysis of Algorithms - Question Bank: Unit - IДокумент14 страницCS2251 Design and Analysis of Algorithms - Question Bank: Unit - Irana1995Оценок пока нет
- DAAДокумент62 страницыDAASrini VasОценок пока нет
- Analysis and Design of Algorithm-2Документ29 страницAnalysis and Design of Algorithm-2renuka05sharmaОценок пока нет
- CSCE 3110 Data Structures & Algorithm Analysis: Rada MihalceaДокумент30 страницCSCE 3110 Data Structures & Algorithm Analysis: Rada MihalceaMahreen IlahiОценок пока нет
- Algorithm, Arrays: Ques 1:define An Algorithm. What Are The Properties of An Algorithm? What Are The Types of Algorithms?Документ51 страницаAlgorithm, Arrays: Ques 1:define An Algorithm. What Are The Properties of An Algorithm? What Are The Types of Algorithms?Yugal YadavОценок пока нет
- 2 MarksДокумент16 страниц2 MarkssiswariyaОценок пока нет
- Daa QB 1 PDFДокумент24 страницыDaa QB 1 PDFSruthy SasiОценок пока нет
- CHAP1 enДокумент45 страницCHAP1 enDo DragonОценок пока нет
- Solu 4Документ44 страницыSolu 4Eric FansiОценок пока нет
- GC 211:data Structures: Week 2: Algorithm Analysis ToolsДокумент21 страницаGC 211:data Structures: Week 2: Algorithm Analysis ToolsayeneОценок пока нет
- Udaydaa1 7Документ75 страницUdaydaa1 7uday bariОценок пока нет
- DS Assignment 1Документ9 страницDS Assignment 1Sonal Jaiswal100% (1)
- CS8451 DAA PartA Q&A-new PDFДокумент20 страницCS8451 DAA PartA Q&A-new PDFMohan DasОценок пока нет
- Question Bank 1to11Документ19 страницQuestion Bank 1to11rinkalОценок пока нет
- Datastructuers and Algorithms in C++Документ5 страницDatastructuers and Algorithms in C++sachin kumar shawОценок пока нет
- Lecture 2: Asymptotic Analysis: CSE 373 Edition 2016Документ32 страницыLecture 2: Asymptotic Analysis: CSE 373 Edition 2016khoalanОценок пока нет
- TCS Papers1Документ45 страницTCS Papers1Moushumi DharОценок пока нет
- Cs 316: Algorithms (Introduction) : SPRING 2015Документ44 страницыCs 316: Algorithms (Introduction) : SPRING 2015Ahmed KhairyОценок пока нет
- Foca FileДокумент16 страницFoca FileShaweta ThakurОценок пока нет
- Daa Questions 2Документ14 страницDaa Questions 2pushrajesandОценок пока нет
- Gói DsaДокумент33 страницыGói DsaHồng HảiОценок пока нет
- K. J. Somaiya College of Engineering, Mumbai-77Документ7 страницK. J. Somaiya College of Engineering, Mumbai-77ARNAB DEОценок пока нет
- ADA Sample PaperДокумент8 страницADA Sample PaperjivendraОценок пока нет
- Assignment (ANALYSIS AND DESIGN OF ALGORITHMS)Документ2 страницыAssignment (ANALYSIS AND DESIGN OF ALGORITHMS)Krishna ViramgamaОценок пока нет
- Daa Assignment1Документ1 страницаDaa Assignment1D.SameerОценок пока нет
- Midterm Test 2Документ15 страницMidterm Test 2Đỗ HòaОценок пока нет
- B. A Structure That Maps Keys To Values: B. Size of Elements Stored in The Hash TableДокумент5 страницB. A Structure That Maps Keys To Values: B. Size of Elements Stored in The Hash TableKurumeti Naga Surya Lakshmana KumarОценок пока нет
- DBMS (R20) Unit - 1Документ14 страницDBMS (R20) Unit - 1Kurumeti Naga Surya Lakshmana KumarОценок пока нет
- Pone 0080247Документ9 страницPone 0080247Kurumeti Naga Surya Lakshmana KumarОценок пока нет
- Irctcs E Ticketing Service Electronic Cancellation Slip (Personal User)Документ2 страницыIrctcs E Ticketing Service Electronic Cancellation Slip (Personal User)Kurumeti Naga Surya Lakshmana KumarОценок пока нет
- Revit ArchitectureДокумент5 страницRevit ArchitectureKurumeti Naga Surya Lakshmana KumarОценок пока нет
- Semaphore Definition: StarvationДокумент21 страницаSemaphore Definition: StarvationKurumeti Naga Surya Lakshmana KumarОценок пока нет
- Linux Programming Lab Manual-New SyllabusДокумент31 страницаLinux Programming Lab Manual-New SyllabusKurumeti Naga Surya Lakshmana KumarОценок пока нет
- 01 BasicsДокумент23 страницы01 BasicsKurumeti Naga Surya Lakshmana KumarОценок пока нет
- Year & Sem.: IV B.Tech.-I Sem. Branch: Information Technology Subject: Design Patterns Academic Year 2014-15Документ2 страницыYear & Sem.: IV B.Tech.-I Sem. Branch: Information Technology Subject: Design Patterns Academic Year 2014-15Kurumeti Naga Surya Lakshmana KumarОценок пока нет
- Data Mining: Concepts and Techniques: Jiawei Han and Micheline KamberДокумент46 страницData Mining: Concepts and Techniques: Jiawei Han and Micheline KamberKurumeti Naga Surya Lakshmana KumarОценок пока нет
- Ads Programming: LAB ManualДокумент2 страницыAds Programming: LAB ManualKurumeti Naga Surya Lakshmana KumarОценок пока нет
- SKDFSDFДокумент4 страницыSKDFSDFKurumeti Naga Surya Lakshmana KumarОценок пока нет
- Data Base Management Systems: Lab ManualДокумент2 страницыData Base Management Systems: Lab ManualKurumeti Naga Surya Lakshmana KumarОценок пока нет
- A Novel Approach To Defend and Detect Flood Attacks in Disruption Tolerant NetworksДокумент4 страницыA Novel Approach To Defend and Detect Flood Attacks in Disruption Tolerant NetworksKurumeti Naga Surya Lakshmana KumarОценок пока нет
- ACN: An Associative Classifier With Negative RulesДокумент7 страницACN: An Associative Classifier With Negative RulesKurumeti Naga Surya Lakshmana KumarОценок пока нет
- Lenovo G460e Compal LA-7011P PAW10 Rev1.0A SchematicДокумент41 страницаLenovo G460e Compal LA-7011P PAW10 Rev1.0A Schematicserrano.flia.coОценок пока нет
- Intercepting #Ajax Requests in #CEFSharp (Chrome For C#) Network Programming inДокумент8 страницIntercepting #Ajax Requests in #CEFSharp (Chrome For C#) Network Programming inFaisal Tifta ZanyОценок пока нет
- DBMS FileДокумент76 страницDBMS FileJeremy MontgomeryОценок пока нет
- TM811TRE.30-ENG - APROL Runtime System PDFДокумент64 страницыTM811TRE.30-ENG - APROL Runtime System PDFAnton KazakovОценок пока нет
- SL4000Документ17 страницSL4000Felix EstrellaОценок пока нет
- Bharat Heavy Elelctricals Limited: Operation & Maintenance Manual of Bhelscan Flame Scanner System (Bn10)Документ25 страницBharat Heavy Elelctricals Limited: Operation & Maintenance Manual of Bhelscan Flame Scanner System (Bn10)MukeshKrОценок пока нет
- An Introduction To MQTT For Complete BeginnersДокумент22 страницыAn Introduction To MQTT For Complete BeginnerskarchecovОценок пока нет
- Adept PovertyДокумент21 страницаAdept PovertyKitchie HermosoОценок пока нет
- Operating SystemsДокумент18 страницOperating SystemsMr. Rahul Kumar VermaОценок пока нет
- Imrt VmatДокумент29 страницImrt VmatandreaОценок пока нет
- CP4P Week3 Course Preview ActivityДокумент4 страницыCP4P Week3 Course Preview ActivityPresiОценок пока нет
- LM78S40 Switching Voltage Regulator Applications: National Semiconductor Application Note 711 March 2000Документ17 страницLM78S40 Switching Voltage Regulator Applications: National Semiconductor Application Note 711 March 2000Pravin MevadaОценок пока нет
- Class 8 Art BookДокумент17 страницClass 8 Art BookSrijanОценок пока нет
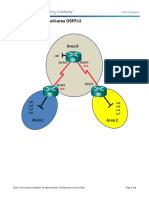
- 9.2.2.9 Lab - Configuring Multi-Area OSPFv3Документ8 страниц9.2.2.9 Lab - Configuring Multi-Area OSPFv3Jessica GregoryОценок пока нет
- Problem Set No.2 SolutionДокумент9 страницProblem Set No.2 SolutionAshley Quinn MorganОценок пока нет
- AlfrescoДокумент10 страницAlfrescoanangsaОценок пока нет
- BSNL Summer Traning ReportДокумент39 страницBSNL Summer Traning ReportMohd MunzirОценок пока нет
- Table of Contents For Computer Architecture: A Minimalist PerspectiveДокумент6 страницTable of Contents For Computer Architecture: A Minimalist PerspectiveWilliam GilreathОценок пока нет
- Full Multisim 14 PDFДокумент365 страницFull Multisim 14 PDFHafiz PGОценок пока нет
- B.inggris Bill GatesДокумент1 страницаB.inggris Bill GatesRoy Wijaya SembiringОценок пока нет
- Huawei AC6805 Wireless Access Controller Datasheet - 2Документ16 страницHuawei AC6805 Wireless Access Controller Datasheet - 2irfanОценок пока нет
- Rational Root TheoremДокумент9 страницRational Root TheoremAerown John Gonzales TamayoОценок пока нет
- TB6500 ManualДокумент11 страницTB6500 ManualEnrique BautistaОценок пока нет
- CS201 Introduction To Programming Solved MID Term Paper 03Документ4 страницыCS201 Introduction To Programming Solved MID Term Paper 03ayesharahimОценок пока нет
- 2.+AC Jurnal+GETS V1 N2 ArdiansyahДокумент8 страниц2.+AC Jurnal+GETS V1 N2 ArdiansyahSEIN FOXINОценок пока нет
- Control Systems Control Systems Masons Gain Formula-Www-Tutorialspoint-ComДокумент6 страницControl Systems Control Systems Masons Gain Formula-Www-Tutorialspoint-ComshrikrisОценок пока нет
- Service Contract Proposal Template - IT PattanaДокумент14 страницService Contract Proposal Template - IT PattanaDuncan NgachaОценок пока нет
- Review of DC-DC Converters in Photovoltaic Systems For MPPT SystemsДокумент5 страницReview of DC-DC Converters in Photovoltaic Systems For MPPT SystemsLuis Angel Garcia ReyesОценок пока нет
- CZ SeriesДокумент15 страницCZ Serieshasan2010jОценок пока нет
- Lab Manual 5Документ6 страницLab Manual 5Nasr UllahОценок пока нет