Вам также может понравиться
- Plan 9 From Bell-Labs: Andrey Mirtchovski Tony KusalikДокумент37 страницPlan 9 From Bell-Labs: Andrey Mirtchovski Tony KusalikKarthik RajuОценок пока нет
- TCP IP Protocol Suite Chap-01 IntroДокумент13 страницTCP IP Protocol Suite Chap-01 IntroRahul RajОценок пока нет
- Plan 9 PresentationДокумент32 страницыPlan 9 PresentationLeoKuriakoseОценок пока нет
- Plan9-Review-1plan 921128013725-Phpapp02Документ57 страницPlan9-Review-1plan 921128013725-Phpapp02LeoKuriakoseОценок пока нет
- 9Документ22 страницы9shoummowОценок пока нет
- Anomalies in Firewall PolicyДокумент6 страницAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Plan 9 Operating System: Submitted ByДокумент2 страницыPlan 9 Operating System: Submitted ByLeoKuriakoseОценок пока нет
- DMR Iwp9Документ26 страницDMR Iwp9LeoKuriakoseОценок пока нет
- 4061 28Документ15 страниц4061 28LeoKuriakoseОценок пока нет
- Anomalies in Firewall PolicyДокумент6 страницAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Anomalies in Firewall PolicyДокумент6 страницAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Detecting and Resolving Firewall Policy AnomaliesДокумент14 страницDetecting and Resolving Firewall Policy AnomaliesieeexploreprojectsОценок пока нет
- Anomalies in Firewall PolicyДокумент15 страницAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Anomalies in Firewall PolicyДокумент21 страницаAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Detecting and Resolving Firewall Policy AnomaliesДокумент9 страницDetecting and Resolving Firewall Policy AnomaliesJAYAPRAKASHОценок пока нет
- Anomalies in Firewall PolicyДокумент12 страницAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Anomalies in Firewall PolicyДокумент11 страницAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Google LoonДокумент7 страницGoogle LoonLeoKuriakoseОценок пока нет
- Anomalies in Firewall PolicyДокумент4 страницыAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Anomalies in Firewall PolicyДокумент4 страницыAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Anomalies in Firewall PolicyДокумент8 страницAnomalies in Firewall PolicyLeoKuriakoseОценок пока нет
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (894)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Security Enhanced Applications For Information SystemsДокумент234 страницыSecurity Enhanced Applications For Information SystemsJoséRodriguezОценок пока нет
- SampleFINAL KEY 205 TaylorДокумент9 страницSampleFINAL KEY 205 Tayloraskar_cbaОценок пока нет
- So PrintДокумент55 страницSo PrintAniezeEchaОценок пока нет
- TCR-TSC Lookup TableДокумент8 страницTCR-TSC Lookup TableSoumya DasОценок пока нет
- Copy Ios Flash To TFTP ServerДокумент7 страницCopy Ios Flash To TFTP Serverateeqshahid035Оценок пока нет
- Trapdoors For Lattices: Simpler, Tighter, Faster, Smaller: Daniele Micciancio Chris Peikert September 14, 2011Документ41 страницаTrapdoors For Lattices: Simpler, Tighter, Faster, Smaller: Daniele Micciancio Chris Peikert September 14, 2011kr0465Оценок пока нет
- Wincc Oa User Days 2016 Communication Drivers ProtocolsДокумент13 страницWincc Oa User Days 2016 Communication Drivers ProtocolsKijo SupicОценок пока нет
- Comp422 2011 Lecture1 IntroductionДокумент50 страницComp422 2011 Lecture1 IntroductionaskbilladdmicrosoftОценок пока нет
- Algorithms: CS 202 Epp Section ??? Aaron BloomfieldДокумент25 страницAlgorithms: CS 202 Epp Section ??? Aaron BloomfieldJosephОценок пока нет
- A Complete Chapter Quiz: Error Detection and CorrectionДокумент4 страницыA Complete Chapter Quiz: Error Detection and CorrectionJaneОценок пока нет
- Amity Practical List 2019-20Документ7 страницAmity Practical List 2019-20fakeОценок пока нет
- LFCS Domains and Competencies V2.16 ChecklistДокумент7 страницLFCS Domains and Competencies V2.16 ChecklistKeny Oscar Cortes GonzalezОценок пока нет
- An A-Z Index of The Windows CMD Command Line - SS64Документ5 страницAn A-Z Index of The Windows CMD Command Line - SS64Bharat RaghunathanОценок пока нет
- CN ProgramsДокумент14 страницCN ProgramsPrakash ReddyОценок пока нет
- Numerical Methods Chapra 6th Edition Solution Manual PDFДокумент3 страницыNumerical Methods Chapra 6th Edition Solution Manual PDFabdul latifОценок пока нет
- Computer Concept and Web Technology: Cse 3Rd Semester Jkie BilaspurДокумент98 страницComputer Concept and Web Technology: Cse 3Rd Semester Jkie Bilaspurmd.zainul haqueОценок пока нет
- Hardware Certification Report - 1152921504626450757 PDFДокумент1 страницаHardware Certification Report - 1152921504626450757 PDFAbrahamОценок пока нет
- NXOpen - Signing ProcessДокумент2 страницыNXOpen - Signing ProcesssnagareddyОценок пока нет
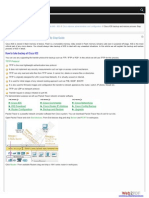
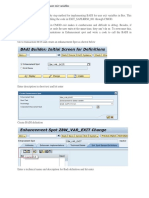
- Badi Implementation For Bex User Exit VariablesДокумент6 страницBadi Implementation For Bex User Exit VariablesMANIОценок пока нет
- Security Policies 919Документ14 страницSecurity Policies 919questnvr73Оценок пока нет
- Artificial Intelligence With JavaДокумент1 016 страницArtificial Intelligence With JavaAkram Dridi100% (7)
- How To Fix AutoCAD Error 1308Документ6 страницHow To Fix AutoCAD Error 1308curlyjockeyОценок пока нет
- Tugasan MTS3013 Pengaturcaraan BerstrukturДокумент19 страницTugasan MTS3013 Pengaturcaraan BerstrukturMuhamad Basyir Mat NawiОценок пока нет
- DIGITAL CIRCUIT SimulationДокумент60 страницDIGITAL CIRCUIT SimulationNidheesh KMОценок пока нет
- Multi Tenancy Rails PDFДокумент162 страницыMulti Tenancy Rails PDFgilaniali346850% (2)
- Do 009467 PS 4Документ482 страницыDo 009467 PS 4gayamartОценок пока нет
- Jira PythonДокумент24 страницыJira PythonsysrerunОценок пока нет
- CSC 4181 Compiler Construction ParsingДокумент53 страницыCSC 4181 Compiler Construction ParsingMohsin MineОценок пока нет
- Sampling TheoremДокумент92 страницыSampling TheoremvijaybabukoreboinaОценок пока нет
- PIC24FJ128GAДокумент230 страницPIC24FJ128GAjosrocОценок пока нет