Вам также может понравиться
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- IRR of RA 9297Документ21 страницаIRR of RA 9297Peter Jake Patriarca0% (1)
- Rayleigh-Plateau Instability of Axisymmetric Fluid BodiesДокумент27 страницRayleigh-Plateau Instability of Axisymmetric Fluid BodiesSam RoelantsОценок пока нет
- CBC - RAC (PACU-CRE) Servicing NC IIIДокумент139 страницCBC - RAC (PACU-CRE) Servicing NC IIIrayОценок пока нет
- Thinkpad X13 Yoga Gen 2 User GuideДокумент66 страницThinkpad X13 Yoga Gen 2 User GuideKayla DollenteОценок пока нет
- Meralco Bill 409851010101 10232021 - 1Документ2 страницыMeralco Bill 409851010101 10232021 - 1Kayla DollenteОценок пока нет
- Chemical Engineering Lab Drying Experiment ResultsДокумент2 страницыChemical Engineering Lab Drying Experiment ResultsKayla DollenteОценок пока нет
- E302Документ4 страницыE302Kayla DollenteОценок пока нет
- Aeotab 12Документ12 страницAeotab 12Kayla DollenteОценок пока нет
- Diagnostic Exam Review Phy10Документ24 страницыDiagnostic Exam Review Phy10Kayla DollenteОценок пока нет
- 1997 11 14 Guide Pulppaper JD Fs2Документ3 страницы1997 11 14 Guide Pulppaper JD Fs2Yudhi Dwi KurniawanОценок пока нет
- Ieotab 3Документ4 страницыIeotab 3Kayla DollenteОценок пока нет
- Petroleum Whitepaper 7-15-2013Документ68 страницPetroleum Whitepaper 7-15-2013Kayla DollenteОценок пока нет
- 79 e 4150 D 6054 Be 6034Документ9 страниц79 e 4150 D 6054 Be 6034Kayla DollenteОценок пока нет
- St. Jude Novena PrayerДокумент2 страницыSt. Jude Novena PrayerKayla DollenteОценок пока нет
- Drying Curves of Non-Porous SolidsДокумент6 страницDrying Curves of Non-Porous SolidsKayla DollenteОценок пока нет
- Fresh or Recycled Water Logs And/or Chips: Wood PreparationДокумент1 страницаFresh or Recycled Water Logs And/or Chips: Wood PreparationKayla DollenteОценок пока нет
- E301Документ3 страницыE301Kayla DollenteОценок пока нет
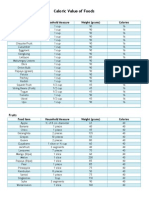
- Caloric Value of FoodsДокумент3 страницыCaloric Value of FoodsKayla DollenteОценок пока нет
- Orifice Plate Test ResultsДокумент10 страницOrifice Plate Test ResultsKayla DollenteОценок пока нет
- Flow Measurements Using OrificeДокумент4 страницыFlow Measurements Using OrificeKovačević DarkoОценок пока нет
- Prayer Before ExaminationДокумент2 страницыPrayer Before ExaminationKayla DollenteОценок пока нет
- Ir Presentation PDFДокумент17 страницIr Presentation PDFMarr BarolОценок пока нет
- Quadratic Relation and FunctionsДокумент37 страницQuadratic Relation and FunctionsKayla DollenteОценок пока нет
- Chipping Initial Cooking Washing Debarking Screening: Refining (Continuous Digester)Документ1 страницаChipping Initial Cooking Washing Debarking Screening: Refining (Continuous Digester)Kayla DollenteОценок пока нет
- 86 Measuring A Discharge Coefficient of An Orifice For An Unsteady Compressible FlowДокумент5 страниц86 Measuring A Discharge Coefficient of An Orifice For An Unsteady Compressible FlowKayla DollenteОценок пока нет
- Eulers MethodДокумент3 страницыEulers MethodKayla DollenteОценок пока нет
- Chanson de Roland - Full SummaryДокумент16 страницChanson de Roland - Full SummaryKayla DollenteОценок пока нет
- School of Chemical Engineering and Chemistry: Mapua Institute of TechnologyДокумент2 страницыSchool of Chemical Engineering and Chemistry: Mapua Institute of TechnologyKayla DollenteОценок пока нет
- Diagnostic Exam Review Phy10Документ24 страницыDiagnostic Exam Review Phy10Kayla DollenteОценок пока нет
- Dr. Neal Bushaw: at atДокумент3 страницыDr. Neal Bushaw: at atKayla DollenteОценок пока нет
- Boyce/Diprima 10 Ed, CH 1.1: Basic Mathematical Models Direction FieldsДокумент27 страницBoyce/Diprima 10 Ed, CH 1.1: Basic Mathematical Models Direction FieldsKayla DollenteОценок пока нет
- Math6 Q2 Module6Документ44 страницыMath6 Q2 Module6Jory Aromas AgapayОценок пока нет
- Statistics & Probability Q3 - Week 7-8Документ10 страницStatistics & Probability Q3 - Week 7-8Rayezeus Jaiden Del RosarioОценок пока нет
- Emerging Trends in Application of Mathematics in Current Engineering FieldДокумент5 страницEmerging Trends in Application of Mathematics in Current Engineering Fieldbaks007100% (1)
- 6 Hansen ModelДокумент26 страниц6 Hansen ModelSemíramis LimaОценок пока нет
- Physics - Ch5 VectorsДокумент25 страницPhysics - Ch5 VectorsNur IffatinОценок пока нет
- DSP LAB EXPERIMENTS USING CODE COMPOSER STUDIO ON TMS320C6745Документ11 страницDSP LAB EXPERIMENTS USING CODE COMPOSER STUDIO ON TMS320C6745vedeshОценок пока нет
- POINT OF INTERSECTION OF TWO STRAIGHT LINESДокумент15 страницPOINT OF INTERSECTION OF TWO STRAIGHT LINESRißhith PatelОценок пока нет
- Power Query M Formula Language Specification (July 2019)Документ115 страницPower Query M Formula Language Specification (July 2019)lucasОценок пока нет
- 2.4 Transition MatricesДокумент9 страниц2.4 Transition MatricesLutfi AminОценок пока нет
- Geometry Section 3 6Документ11 страницGeometry Section 3 6api-262621710Оценок пока нет
- GTSE Online Class IV MathsДокумент13 страницGTSE Online Class IV MathsGurmohina KaurОценок пока нет
- Vibrations and Stability - J.J.Thomsen, 2003 - IndexДокумент9 страницVibrations and Stability - J.J.Thomsen, 2003 - IndexBenjaminОценок пока нет
- DLL - Math 6 4th Q WK 5Документ4 страницыDLL - Math 6 4th Q WK 5JohnCarloBernardoОценок пока нет
- MA1002Документ1 страницаMA1002Cherry CharanОценок пока нет
- Practice Problems in PhysicsДокумент12 страницPractice Problems in PhysicsChandra SainiОценок пока нет
- Functional AnalysisДокумент5 страницFunctional Analysisirayo50% (2)
- Part 2 - The Second-Order Linear ODEsДокумент59 страницPart 2 - The Second-Order Linear ODEsnam nguyenОценок пока нет
- (Discrete Mathematical Structure) : Total Pages:6Документ6 страниц(Discrete Mathematical Structure) : Total Pages:6Prs SorenОценок пока нет
- Instructions for Exam Answer Script FormattingДокумент3 страницыInstructions for Exam Answer Script Formattingप्रियरंजन सिंह राजपूतОценок пока нет
- Programacion Lineal N 1 PDFДокумент14 страницProgramacion Lineal N 1 PDFAlbino Quispe MОценок пока нет
- GVN-THE GLOBAL SCHOOL HALFYEARLY EXAMINATION MATHEMATICS CLASS X SET-BДокумент3 страницыGVN-THE GLOBAL SCHOOL HALFYEARLY EXAMINATION MATHEMATICS CLASS X SET-Bmr. rightОценок пока нет
- Kernel Ridge Regression ClassificationДокумент5 страницKernel Ridge Regression Classificationag125aaОценок пока нет
- Top Partial Differential Equations (PDEsДокумент2 страницыTop Partial Differential Equations (PDEsmaheshОценок пока нет
- Psa - 2 Units 201-20-Important Questions 1Документ3 страницыPsa - 2 Units 201-20-Important Questions 1Kunte Vikas Rao0% (1)
- Sed 322 SyllabusДокумент5 страницSed 322 Syllabusapi-251146794Оценок пока нет
- Math Diagnostic ExamДокумент4 страницыMath Diagnostic ExamMananquil JeromeОценок пока нет
- Canonical Correlation Analysis: James H. SteigerДокумент35 страницCanonical Correlation Analysis: James H. SteigerOchieng WilberforceОценок пока нет
- Inequalities NotesДокумент3 страницыInequalities NotesMichal OstrowskiОценок пока нет