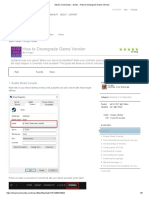
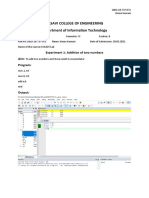
Вам также может понравиться
- Base SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОт EverandBase SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОценок пока нет
- Common Issues in DatastageДокумент12 страницCommon Issues in Datastagesunipulicherla100% (1)
- Advanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОт EverandAdvanced SAS Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesОценок пока нет
- IV - Common Errors in DatastageДокумент3 страницыIV - Common Errors in DatastageMohapatra SaradaОценок пока нет
- Data Stage ETL QuestionДокумент11 страницData Stage ETL Questionrameshgrb2000Оценок пока нет
- Datastage Scenarios in IndianДокумент19 страницDatastage Scenarios in IndianRasool ShaikОценок пока нет
- Issues DatastageДокумент4 страницыIssues DatastagerkpoluОценок пока нет
- BMC Control-M 7: A Journey from Traditional Batch Scheduling to Workload AutomationОт EverandBMC Control-M 7: A Journey from Traditional Batch Scheduling to Workload AutomationОценок пока нет
- DataStage MatterДокумент81 страницаDataStage MatterShiva Kumar0% (1)
- DataStage Theory PartДокумент18 страницDataStage Theory PartJesse KotaОценок пока нет
- Pro Oracle SQL Development: Best Practices for Writing Advanced QueriesОт EverandPro Oracle SQL Development: Best Practices for Writing Advanced QueriesОценок пока нет
- Datastage QuestionsДокумент18 страницDatastage QuestionsMonica MarciucОценок пока нет
- Load XML Files Using A DataStage Parallel JobДокумент2 страницыLoad XML Files Using A DataStage Parallel JobrachitОценок пока нет
- IBM InfoSphere DataStage A Complete Guide - 2019 EditionОт EverandIBM InfoSphere DataStage A Complete Guide - 2019 EditionРейтинг: 5 из 5 звезд5/5 (1)
- Data StageДокумент44 страницыData StageDilip AlluriОценок пока нет
- Datastage Scenarios 3Документ23 страницыDatastage Scenarios 3Bhaskar ReddyОценок пока нет
- Datastage Material PDFДокумент110 страницDatastage Material PDFBhaskar ReddyОценок пока нет
- DataStage ProblemДокумент2 страницыDataStage ProblemMuvva Vijayabasker ReddyОценок пока нет
- Dev's Datastage Tutorial, Guides, Training and Online Help 4 U. Unix, Etl, Database Related Solutions - Datastage Interview Questions and Answers v1Документ6 страницDev's Datastage Tutorial, Guides, Training and Online Help 4 U. Unix, Etl, Database Related Solutions - Datastage Interview Questions and Answers v1vinu_kb89Оценок пока нет
- Certificación 11.3Документ16 страницCertificación 11.3juanfevargax2100% (1)
- DS RoutineДокумент12 страницDS RoutineHarsh JainОценок пока нет
- Balaji DatastageДокумент6 страницBalaji Datastagefreecharge momОценок пока нет
- Looping in DatastageДокумент7 страницLooping in DatastageCsvv VardhanОценок пока нет
- Datastage Transformer FunctionsДокумент71 страницаDatastage Transformer FunctionsAnonymousHPОценок пока нет
- Datastage AnswersДокумент3 страницыDatastage AnswersAnonymousHPОценок пока нет
- Partitioning in DatastageДокумент27 страницPartitioning in DatastageVamsi KarthikОценок пока нет
- Datastage: Datastage Interview Questions/AnswersДокумент28 страницDatastage: Datastage Interview Questions/Answersashok7374Оценок пока нет
- Recovered DataStage TipДокумент115 страницRecovered DataStage TipBhaskar Reddy100% (1)
- Datastage Performance Guide PDFДокумент108 страницDatastage Performance Guide PDFbsvbrajaОценок пока нет
- Data Stage Interview QuestionsДокумент15 страницData Stage Interview QuestionsManoj SharmaОценок пока нет
- Datastage UnixcommondsДокумент9 страницDatastage Unixcommondsbrightfulindia3Оценок пока нет
- DataStage FAQДокумент243 страницыDataStage FAQmohenishjaiswal100% (1)
- Datastage Slowly Changing DimensionsДокумент10 страницDatastage Slowly Changing DimensionsrameshchinnaboinaОценок пока нет
- DataStage Basic Concepts11Документ68 страницDataStage Basic Concepts11ArunKumarОценок пока нет
- ETL DataStage v11.3Документ28 страницETL DataStage v11.3RajaPraveenОценок пока нет
- Introduction To DatastageДокумент24 страницыIntroduction To DatastageGiorgio JacchiniОценок пока нет
- Resume BhaskarGupta DataStageДокумент16 страницResume BhaskarGupta DataStageBhaskar Gupta MadalaОценок пока нет
- DataStage Parallel RoutinesДокумент5 страницDataStage Parallel Routinesnithinmamidala999Оценок пока нет
- Datastage 8 DumpsДокумент51 страницаDatastage 8 DumpsksparthiОценок пока нет
- Data Stage Basic ConceptsДокумент6 страницData Stage Basic ConceptssunilОценок пока нет
- Datastage InterviewДокумент161 страницаDatastage Interviewmukesh100% (1)
- Job SequencerДокумент19 страницJob Sequenceraddubey2Оценок пока нет
- Datastage NotesДокумент86 страницDatastage Notesbimaljsr123Оценок пока нет
- Ibm Infosphere Datastage V8.0.1 Training/Workshop: Course DescriptionДокумент2 страницыIbm Infosphere Datastage V8.0.1 Training/Workshop: Course DescriptionzipzapdhoomОценок пока нет
- Datastage Scribble Sheet: VariousДокумент20 страницDatastage Scribble Sheet: VariousKurt AndersenОценок пока нет
- DataStage IntroductionДокумент35 страницDataStage Introductionshanky_hertbОценок пока нет
- Run Time Column Propagation (RCP)Документ3 страницыRun Time Column Propagation (RCP)addubey2Оценок пока нет
- DM 0903 Data Stage Slowly Changing PDFДокумент32 страницыDM 0903 Data Stage Slowly Changing PDFsirishdahagamОценок пока нет
- DataStage Configuration FileДокумент10 страницDataStage Configuration FileVasu SrinivasОценок пока нет
- DataStage Interview QuestionsДокумент3 страницыDataStage Interview QuestionsvrkesariОценок пока нет
- Module 1: Introduction To Data Warehouse Concepts: Syllabus of Datastage CourseДокумент13 страницModule 1: Introduction To Data Warehouse Concepts: Syllabus of Datastage CourseSampath PagidipallyОценок пока нет
- Datastage Scenarios Doc1Документ52 страницыDatastage Scenarios Doc1Bhaskar ReddyОценок пока нет
- Training Course Datastage (Part 1) : V. Beyet 03/07/2006Документ122 страницыTraining Course Datastage (Part 1) : V. Beyet 03/07/2006gangadhar1310100% (1)
- DatastageДокумент69 страницDatastageNarendra Singh100% (1)
- Excel Analysis of Between CompaniesДокумент5 страницExcel Analysis of Between Companiesnithinmamidala999Оценок пока нет
- 101 Keyboard ShortcutsДокумент6 страниц101 Keyboard Shortcutslittle cute gurlz100% (4)
- Analysis With Missing DataДокумент55 страницAnalysis With Missing Datanithinmamidala999Оценок пока нет
- Summary Measures: Multiple Choice QuestionsДокумент9 страницSummary Measures: Multiple Choice Questionsnithinmamidala999Оценок пока нет
- BankigsitesДокумент1 страницаBankigsitesnithinmamidala999Оценок пока нет
- KNN ALGORITHM IN MACHINELEARNINGДокумент10 страницKNN ALGORITHM IN MACHINELEARNINGnithinmamidala999Оценок пока нет
- AreДокумент158 страницAreAditya Kumar SinghОценок пока нет
- DS FaqsДокумент16 страницDS FaqsSrikanth ReddyОценок пока нет
- Data Stage Interview Questions - 12-Dec-2013 - 12PMДокумент4 страницыData Stage Interview Questions - 12-Dec-2013 - 12PMnithinmamidala999Оценок пока нет
- Datastage ArchitectureДокумент4 страницыDatastage Architecturenithinmamidala999Оценок пока нет
- DataStage Stages 12-Dec-2013 12PMДокумент47 страницDataStage Stages 12-Dec-2013 12PMnithinmamidala999Оценок пока нет
- What Is The Flow of Loading Data Into Fact & Dimensional Tables?Документ3 страницыWhat Is The Flow of Loading Data Into Fact & Dimensional Tables?nithinmamidala999Оценок пока нет
- Bharathi.A: E-MailДокумент3 страницыBharathi.A: E-Mailnithinmamidala999Оценок пока нет
- Amulya DataStag ResumeДокумент4 страницыAmulya DataStag Resumenithinmamidala999Оценок пока нет
- Sandeep ds3 2014-04-22Документ3 страницыSandeep ds3 2014-04-22nithinmamidala999Оценок пока нет
- Basic of StatisticsДокумент83 страницыBasic of StatisticsMuhammad SyiardyОценок пока нет
- Hanumanth 3+ Testing ResumeДокумент3 страницыHanumanth 3+ Testing Resumenithinmamidala999Оценок пока нет
- Email: Mobile No: Professional SummaryДокумент3 страницыEmail: Mobile No: Professional Summarynithinmamidala999Оценок пока нет
- Battula Edukondalu: Good Experience inДокумент3 страницыBattula Edukondalu: Good Experience innithinmamidala999Оценок пока нет
- 170-2008 Learning Procreport PDFДокумент15 страниц170-2008 Learning Procreport PDFnithinmamidala999Оценок пока нет
- Analytics With R - Course ContentsДокумент2 страницыAnalytics With R - Course ContentsHarikrishna BajjuriОценок пока нет
- Debbie Hoppe, John Alden Life Insurance Company, Sacramento, CAДокумент2 страницыDebbie Hoppe, John Alden Life Insurance Company, Sacramento, CAnithinmamidala999Оценок пока нет
- Proc Tabulate: Doing More: Art Carpenter California Occidental Consultants, Anchorage, AKДокумент18 страницProc Tabulate: Doing More: Art Carpenter California Occidental Consultants, Anchorage, AKnithinmamidala999Оценок пока нет
- DS Admin CmdsДокумент121 страницаDS Admin Cmdsnithinmamidala999Оценок пока нет
- AggregatorДокумент4 страницыAggregatornithinmamidala999Оценок пока нет
- Major Components of Teradata ArchitectureДокумент52 страницыMajor Components of Teradata Architecturenithinmamidala999Оценок пока нет
- DataStage XML and Web Services Packs OverviewДокумент71 страницаDataStage XML and Web Services Packs Overviewnithinmamidala999Оценок пока нет
- Daywise Schedule DATASTAGE 8.7Документ3 страницыDaywise Schedule DATASTAGE 8.7nithinmamidala999Оценок пока нет
- Datastage CantentsДокумент6 страницDatastage Cantentsnithinmamidala999Оценок пока нет
- Pwn2Own 2014 AFD - Sys Privilege EscalationДокумент16 страницPwn2Own 2014 AFD - Sys Privilege Escalationc583162Оценок пока нет
- PLE6xx Installation: EAME Service TrainingДокумент57 страницPLE6xx Installation: EAME Service TrainingMario BreguОценок пока нет
- Client Server Computing Model & Data WarehousingДокумент2 страницыClient Server Computing Model & Data WarehousingKM SHATAKSHIОценок пока нет
- PsExec - Execute Process RemotelyДокумент2 страницыPsExec - Execute Process RemotelyYasir KhanОценок пока нет
- Swathi ABAP FresherДокумент2 страницыSwathi ABAP FresherswathiОценок пока нет
- How Can I Restrict Windows 7 To Only Use The Local Subnet, But Block The Internet - Super UserДокумент2 страницыHow Can I Restrict Windows 7 To Only Use The Local Subnet, But Block The Internet - Super UserMario SabatinoОценок пока нет
- Comprog22 PDFДокумент30 страницComprog22 PDFKatelyn BermudeОценок пока нет
- Paint Package Wordpad and Notepad Other Accessories of Windows Briefcase Utility of Windows 95Документ8 страницPaint Package Wordpad and Notepad Other Accessories of Windows Briefcase Utility of Windows 95cooooool1927Оценок пока нет
- Motivation: Consider A Shared Database: - Two Classes of UsersДокумент18 страницMotivation: Consider A Shared Database: - Two Classes of UsersJagruti BorasteОценок пока нет
- Oracle SQL Developer VMДокумент3 страницыOracle SQL Developer VMKhoa DiepОценок пока нет
- DSD Native Instructions (Foobar-ASIO)Документ5 страницDSD Native Instructions (Foobar-ASIO)carmineОценок пока нет
- Install and Configure A GPFS Cluster On AIXДокумент5 страницInstall and Configure A GPFS Cluster On AIXvidyasagarraoОценок пока нет
- Steam Community - Guide - How To Downgrade Game VersionДокумент8 страницSteam Community - Guide - How To Downgrade Game VersionZulfiqarОценок пока нет
- ADDAДокумент50 страницADDAAnupam KumarОценок пока нет
- FSD Oracle Event - CNSE Main SlotДокумент10 страницFSD Oracle Event - CNSE Main SlotazeeОценок пока нет
- Configuring and Managing VsansДокумент14 страницConfiguring and Managing VsansManishОценок пока нет
- Embedded Systems Lecture 2Документ60 страницEmbedded Systems Lecture 2Nebiyu TakeleОценок пока нет
- SCJP - Question Bank 1Документ15 страницSCJP - Question Bank 1Pune EnginrОценок пока нет
- HD Hpe Pro: Evolve-Dialogue With Your Rival by Professional ToolsДокумент7 страницHD Hpe Pro: Evolve-Dialogue With Your Rival by Professional ToolsBest PC BoxОценок пока нет
- Delock External Enclosure For 2.5 Sata HDD / SSD With Superspeed Usb Type Micro-B Female - Tool FreeДокумент2 страницыDelock External Enclosure For 2.5 Sata HDD / SSD With Superspeed Usb Type Micro-B Female - Tool FreeVasile GurezОценок пока нет
- Gen Diff ProtpdfДокумент55 страницGen Diff ProtpdfAyan MajiОценок пока нет
- HP SSD S700 Pro 2.5 Datasheet V2Документ19 страницHP SSD S700 Pro 2.5 Datasheet V2poor clasher mj khanОценок пока нет
- Forcetv IptvДокумент81 страницаForcetv IptvJanesa100% (1)
- Director Global Customer Training in Charlotte NC Resume Andrew ConlanДокумент3 страницыDirector Global Customer Training in Charlotte NC Resume Andrew ConlanAndrewConlanОценок пока нет
- Install LAMP Server (Apache, MariaDB, PHP) On CentOS - RHEL - Scientific Linux 7 - UnixmenДокумент9 страницInstall LAMP Server (Apache, MariaDB, PHP) On CentOS - RHEL - Scientific Linux 7 - UnixmenAymenОценок пока нет
- Operating Systems: Project ReportsДокумент33 страницыOperating Systems: Project ReportsMafruha Rahman MariamОценок пока нет
- 1602-18-737-071 ES&IOT Lab 1 - MergedДокумент139 страниц1602-18-737-071 ES&IOT Lab 1 - Mergedcity cyberОценок пока нет
- A Presentation On Virtual Keyboard: Submitted By:-Jugaaduengineer (Anil Saini)Документ19 страницA Presentation On Virtual Keyboard: Submitted By:-Jugaaduengineer (Anil Saini)Prince SivaОценок пока нет
- GNUSim8085 Assembly Language GuideДокумент3 страницыGNUSim8085 Assembly Language GuideKomalОценок пока нет
- QuickRide LogcatДокумент129 страницQuickRide LogcatRakesh GuptaОценок пока нет
- Coders at Work: Reflections on the Craft of ProgrammingОт EverandCoders at Work: Reflections on the Craft of ProgrammingРейтинг: 4 из 5 звезд4/5 (151)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceОт EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceОценок пока нет
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepОт EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepРейтинг: 4.5 из 5 звезд4.5/5 (19)
- How to Make a Video Game All By Yourself: 10 steps, just you and a computerОт EverandHow to Make a Video Game All By Yourself: 10 steps, just you and a computerРейтинг: 5 из 5 звезд5/5 (1)
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleОт EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleРейтинг: 4 из 5 звезд4/5 (16)
- Clean Code: A Handbook of Agile Software CraftsmanshipОт EverandClean Code: A Handbook of Agile Software CraftsmanshipРейтинг: 5 из 5 звезд5/5 (13)
- Microsoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.От EverandMicrosoft 365 Guide to Success: 10 Books in 1 | Kick-start Your Career Learning the Key Information to Master Your Microsoft Office Files to Optimize Your Tasks & Surprise Your Colleagues | Access, Excel, OneDrive, Outlook, PowerPoint, Word, Teams, etc.Рейтинг: 5 из 5 звезд5/5 (2)
- Once Upon an Algorithm: How Stories Explain ComputingОт EverandOnce Upon an Algorithm: How Stories Explain ComputingРейтинг: 4 из 5 звезд4/5 (43)
- What Algorithms Want: Imagination in the Age of ComputingОт EverandWhat Algorithms Want: Imagination in the Age of ComputingРейтинг: 3.5 из 5 звезд3.5/5 (41)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.От EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Рейтинг: 5 из 5 звезд5/5 (34)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsОт EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsРейтинг: 4.5 из 5 звезд4.5/5 (24)
- Nine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersОт EverandNine Algorithms That Changed the Future: The Ingenious Ideas That Drive Today's ComputersРейтинг: 5 из 5 звезд5/5 (7)
- The Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!От EverandThe Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!Рейтинг: 4.5 из 5 звезд4.5/5 (2)
- Python Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsОт EverandPython Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsРейтинг: 3.5 из 5 звезд3.5/5 (54)
- Python for Beginners: A Crash Course Guide to Learn Python in 1 WeekОт EverandPython for Beginners: A Crash Course Guide to Learn Python in 1 WeekРейтинг: 4.5 из 5 звезд4.5/5 (7)
- Python Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)От EverandPython Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)Рейтинг: 5 из 5 звезд5/5 (1)
- GAMEDEV: 10 Steps to Making Your First Game SuccessfulОт EverandGAMEDEV: 10 Steps to Making Your First Game SuccessfulРейтинг: 4.5 из 5 звезд4.5/5 (12)
- Problem Solving in C and Python: Programming Exercises and Solutions, Part 1От EverandProblem Solving in C and Python: Programming Exercises and Solutions, Part 1Рейтинг: 4.5 из 5 звезд4.5/5 (2)
- Python: For Beginners A Crash Course Guide To Learn Python in 1 WeekОт EverandPython: For Beginners A Crash Course Guide To Learn Python in 1 WeekРейтинг: 3.5 из 5 звезд3.5/5 (23)
- Understanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerОт EverandUnderstanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerРейтинг: 4.5 из 5 звезд4.5/5 (44)