Вам также может понравиться
- ch19 3Документ40 страницch19 3BobОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
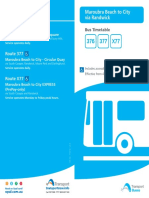
- 376 - 377 Bus Time TableДокумент19 страниц376 - 377 Bus Time TableBobОценок пока нет
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Calc 1141 2Документ27 страницCalc 1141 2BobОценок пока нет
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
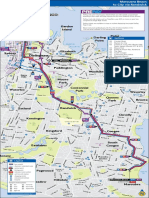
- 376 - 377 Bus MapДокумент1 страница376 - 377 Bus MapBobОценок пока нет
- The Global Financial Crisis: - An Actuarial PerspectiveДокумент3 страницыThe Global Financial Crisis: - An Actuarial PerspectiveBobОценок пока нет
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- International: 2020 VisionДокумент5 страницInternational: 2020 VisionBobОценок пока нет
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Draft Standards For The Development of Spreadsheets: 1 Spreadsheets Can Be AssetsДокумент5 страницDraft Standards For The Development of Spreadsheets: 1 Spreadsheets Can Be AssetsBobОценок пока нет
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Takaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthДокумент3 страницыTakaful: An Islamic Alternative To Conventional Insurance Sees Phenomenal GrowthBobОценок пока нет
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- Hapter Xercise OlutionsДокумент5 страницHapter Xercise OlutionsBobОценок пока нет
- Is Insurance A Luxury?Документ3 страницыIs Insurance A Luxury?BobОценок пока нет
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- ch4 5Документ37 страницch4 5BobОценок пока нет
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Signs of Ageing: HealthcareДокумент2 страницыSigns of Ageing: HealthcareBobОценок пока нет
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Pension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleДокумент43 страницыPension Benefit Design: Flexibility and The Integration of Insurance Over The Life CycleBobОценок пока нет
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Uk Actuarial Profession The Actuaries' Code: ApplicationДокумент3 страницыThe Uk Actuarial Profession The Actuaries' Code: ApplicationBobОценок пока нет
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (345)
- Chapter 3: Professionalism Exercise Sample Solutions Exercise 3.1Документ6 страницChapter 3: Professionalism Exercise Sample Solutions Exercise 3.1BobОценок пока нет
- Code of Professional Conduct November 2009: IndexДокумент10 страницCode of Professional Conduct November 2009: IndexBobОценок пока нет
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- Code of Professional Conduct: Section 5Документ4 страницыCode of Professional Conduct: Section 5BobОценок пока нет
- Code of Conduct For Candidates: Effective December 1, 2008Документ2 страницыCode of Conduct For Candidates: Effective December 1, 2008BobОценок пока нет
- Doors Of: December 2009/january 2010Документ6 страницDoors Of: December 2009/january 2010BobОценок пока нет
- Expert Input: On The Current Financial CrisisДокумент7 страницExpert Input: On The Current Financial CrisisBobОценок пока нет
- Institute of Actuaries of India: Professional Conduct Standards (Referred To As PCS)Документ9 страницInstitute of Actuaries of India: Professional Conduct Standards (Referred To As PCS)BobОценок пока нет
- Rules of Professional ConductДокумент9 страницRules of Professional ConductBobОценок пока нет
- Chapter 2 Exercises and Solutions: Exercise 2.1Документ3 страницыChapter 2 Exercises and Solutions: Exercise 2.1BobОценок пока нет
- BMS 840 - Quantitative Techniques Course Outline - Revised Sept 2018Документ3 страницыBMS 840 - Quantitative Techniques Course Outline - Revised Sept 2018WaswaCollinsОценок пока нет
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Cfa AmosДокумент7 страницCfa Amosrahmat48Оценок пока нет
- UNIT V ProbabilityДокумент16 страницUNIT V Probabilitybad guyОценок пока нет
- Time Series Analysis Using RДокумент15 страницTime Series Analysis Using RJohn KalarОценок пока нет
- Sample Size Determination: Janice Weinberg, SCD Professor of Biostatistics Boston University School of Public HealthДокумент28 страницSample Size Determination: Janice Weinberg, SCD Professor of Biostatistics Boston University School of Public HealthMusa yohanaОценок пока нет
- QIPV 8 - Functions of RandomVariablesДокумент11 страницQIPV 8 - Functions of RandomVariablesMPD19I004 MADDUKURI SRIОценок пока нет
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Hypothesis TestingДокумент23 страницыHypothesis TestingAbhitha JayavelОценок пока нет
- Descriptive StatisticsДокумент21 страницаDescriptive StatisticsComp105Jyot KalathiyaОценок пока нет
- Measures of Central TendencyДокумент35 страницMeasures of Central TendencyRenukadevi NavaneethanОценок пока нет
- Scholastic Travel RetentionДокумент5 страницScholastic Travel RetentionAdithi RajuОценок пока нет
- Coba2 SummaryДокумент2 страницыCoba2 SummaryUmmi Khairun NiswahОценок пока нет
- MAS III Review Question PrelimДокумент17 страницMAS III Review Question PrelimJana LingcayОценок пока нет
- Regresi-BergandaДокумент31 страницаRegresi-BergandaAssyaerati Inezia100% (1)
- Question Text: Complete Mark 0.00 Out of 1.00Документ41 страницаQuestion Text: Complete Mark 0.00 Out of 1.00Kenji TamayoОценок пока нет
- Research Methodology and IPRДокумент2 страницыResearch Methodology and IPRNmg KumarОценок пока нет
- Business Statistics and RM: Hamendra Dangi 9968316938Документ21 страницаBusiness Statistics and RM: Hamendra Dangi 9968316938Adil AliОценок пока нет
- Pedro ScaleДокумент3 страницыPedro ScaleomingОценок пока нет
- FEM 2063 - Data Analytics: CHAPTER 4: ClassificationsДокумент76 страницFEM 2063 - Data Analytics: CHAPTER 4: ClassificationsFakhrulShahrilEzanie100% (1)
- Mathematics Statistics: Matutum View AcademyДокумент10 страницMathematics Statistics: Matutum View AcademyNeil Trezley Sunico BalajadiaОценок пока нет
- De La Salle University - Dasmariñas: Mathematics and Statistics DepartmentДокумент3 страницыDe La Salle University - Dasmariñas: Mathematics and Statistics DepartmentAxl Arboleda ValiolaОценок пока нет
- GENERAL INSTRUCTION: For Answers With Many Decimals, Round Off The FINAL ANSWER To TWO Decimal PlacesДокумент2 страницыGENERAL INSTRUCTION: For Answers With Many Decimals, Round Off The FINAL ANSWER To TWO Decimal Placesjoshua bautistaОценок пока нет
- Machine Learning Survival AnalysisДокумент39 страницMachine Learning Survival AnalysisTiago Almeida de OliveiraОценок пока нет
- BSDM Hypothesis Testing PresentationДокумент11 страницBSDM Hypothesis Testing PresentationPreethiОценок пока нет
- How To Analyze Data Using ANOVA in SPSSДокумент8 страницHow To Analyze Data Using ANOVA in SPSSGaily Jubie HontiverosОценок пока нет
- Tut 3 Confidence Interval - AnswerДокумент2 страницыTut 3 Confidence Interval - Answer王志永Оценок пока нет
- Sampling Techniques - Towards Data ScienceДокумент10 страницSampling Techniques - Towards Data Sciencemayuri kadlagОценок пока нет
- 3 Firm ExampleДокумент14 страниц3 Firm ExampleJose C Beraun TapiaОценок пока нет
- Chapter 6 Correlation and Regression 2Документ19 страницChapter 6 Correlation and Regression 2QuTe DoGra GОценок пока нет
- UM04CBBA04 - 09 - Statistics For Management IIДокумент2 страницыUM04CBBA04 - 09 - Statistics For Management IIDrRitesh PatelОценок пока нет
- AnovaДокумент105 страницAnovaasdasdas asdasdasdsadsasddssaОценок пока нет