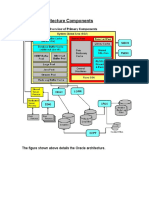
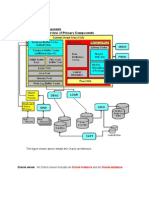
Вам также может понравиться
- Module 1 - Oracle ArchitectureДокумент34 страницыModule 1 - Oracle ArchitecturePratik Gandhi100% (2)
- oRACLE NotesДокумент15 страницoRACLE NotesCarla MissionaОценок пока нет
- Module 1 - Oracle Architecture: ObjectivesДокумент64 страницыModule 1 - Oracle Architecture: Objectivesshaikali1980Оценок пока нет
- Oracle DBA ArchitectureДокумент17 страницOracle DBA ArchitectureDiwakar Reddy SОценок пока нет
- Module 1 - Oracle ArchitectureДокумент34 страницыModule 1 - Oracle ArchitectureGautam TrivediОценок пока нет
- 3 Oracle Architecture NotesДокумент39 страниц3 Oracle Architecture NotesPaul NikolaidisОценок пока нет
- Module 1 - Oracle Architecture: ObjectivesДокумент41 страницаModule 1 - Oracle Architecture: ObjectivesNavneet SainiОценок пока нет
- Database Architecture Oracle DbaДокумент41 страницаDatabase Architecture Oracle DbaImran ShaikhОценок пока нет
- Module 1 - Oracle ArchitectureДокумент110 страницModule 1 - Oracle ArchitectureKranthi KumarОценок пока нет
- Oracle SM IДокумент388 страницOracle SM ITanmoy NandyОценок пока нет
- Chapter - 1: Oracle Architecture - Module 1Документ39 страницChapter - 1: Oracle Architecture - Module 1Vivek MeenaОценок пока нет
- SQL Tuning 11g CustomizedДокумент873 страницыSQL Tuning 11g CustomizedMamataMaharanaОценок пока нет
- Introduction To The Oracle Server: It Includes The FollowingДокумент11 страницIntroduction To The Oracle Server: It Includes The FollowingRishabh BhagatОценок пока нет
- Database NotesДокумент31 страницаDatabase NotesSaad QaisarОценок пока нет
- ORACLE ArchitectureДокумент23 страницыORACLE Architecturechamod tharushaОценок пока нет
- Database Systems: Overview of Oracle Database ArchitectureДокумент24 страницыDatabase Systems: Overview of Oracle Database ArchitectureSuneel KumarОценок пока нет
- Basics of The Oracle Database ArchitectureДокумент56 страницBasics of The Oracle Database Architecturevidhi hinguОценок пока нет
- 10G ConceptsДокумент4 страницы10G Conceptssrini6886dbaОценок пока нет
- Chapter6 Database ArchitectureДокумент56 страницChapter6 Database ArchitectureMohammed AlramadiОценок пока нет
- DbmsДокумент15 страницDbmsElliott MadimabeОценок пока нет
- Chapter 1. Oracle Database ArchitectureДокумент7 страницChapter 1. Oracle Database ArchitectureAdryan AnghelОценок пока нет
- Unit-1 (Oracle Architectural Components)Документ9 страницUnit-1 (Oracle Architectural Components)Sarthak Singh ChandelОценок пока нет
- Oracle ArchitectureДокумент102 страницыOracle ArchitecturemanavalanmichaleОценок пока нет
- CSE 8th Sem DBAДокумент119 страницCSE 8th Sem DBAvidhi hinguОценок пока нет
- Oracle Instance ArchitectureДокумент28 страницOracle Instance ArchitecturemonsonОценок пока нет
- Presentation Lesson1Документ19 страницPresentation Lesson1Troy Lenner ParedesОценок пока нет
- Object Oriented - Interview Questions: What Is OOP?Документ18 страницObject Oriented - Interview Questions: What Is OOP?Sam RogerОценок пока нет
- Oracle10g Introduction1eryk 130405011929 Phpapp02Документ34 страницыOracle10g Introduction1eryk 130405011929 Phpapp02Sonali SinghОценок пока нет
- Chapter01 Oracle ArchitectureДокумент42 страницыChapter01 Oracle ArchitecturehenaediОценок пока нет
- Chapter01 Oracle ArchitectureДокумент42 страницыChapter01 Oracle ArchitectureOscar RiveraОценок пока нет
- Describe Oracle Architecture in Brief.: AnswerДокумент8 страницDescribe Oracle Architecture in Brief.: AnswersonijayminОценок пока нет
- 2 Database ArchitectureДокумент13 страниц2 Database ArchitecturewaleedОценок пока нет
- Oracle Database 11g Database Architecture and ASMДокумент44 страницыOracle Database 11g Database Architecture and ASMYelena BytenskayaОценок пока нет
- Oracle ArchitectureДокумент5 страницOracle ArchitectureVenu BabuОценок пока нет
- Less01 - DBA1 NotesДокумент34 страницыLess01 - DBA1 NotesRahmatullah MehrabiОценок пока нет
- Process Architecture: Open, Comprehensive, and Integrated Approach To Information Management. An OracleДокумент13 страницProcess Architecture: Open, Comprehensive, and Integrated Approach To Information Management. An OraclevishwasdeshkarОценок пока нет
- Module 1 - Oracle ArchitectureДокумент33 страницыModule 1 - Oracle ArchitectureGouthambojja143Оценок пока нет
- Oracle Database ArchitectureДокумент7 страницOracle Database ArchitecturearavinthОценок пока нет
- Case Study-Oracle Mod IiiДокумент63 страницыCase Study-Oracle Mod IiiNevin FrancisОценок пока нет
- Oracle Database Architecture: Umeme Template Version 1.0Документ15 страницOracle Database Architecture: Umeme Template Version 1.0Ma GodfreyОценок пока нет
- Oracle Server Architecture: Oracle Database Consist of Instance and Database ItselfДокумент3 страницыOracle Server Architecture: Oracle Database Consist of Instance and Database ItselfLateshbbОценок пока нет
- Oracle BasicsДокумент30 страницOracle BasicsRaghunath Reddy100% (1)
- 2 - Oracle OCP ExamДокумент16 страниц2 - Oracle OCP ExamAnonymous qPo1wFyH0EОценок пока нет
- Instance: What Is An Oracle Database?Документ7 страницInstance: What Is An Oracle Database?Vinay GoddemmeОценок пока нет
- Oracle Back End: Globsyn TechnologiesДокумент211 страницOracle Back End: Globsyn TechnologiesMayur N MalviyaОценок пока нет
- Oracle 8: Database Administration (Exam # 1Z0-013) : The SgaДокумент16 страницOracle 8: Database Administration (Exam # 1Z0-013) : The SgaAnonymous qPo1wFyH0EОценок пока нет
- 2 - Oracle 8 OCP Admin ExamДокумент16 страниц2 - Oracle 8 OCP Admin ExamAnonymous qPo1wFyH0EОценок пока нет
- Racle G Rchitecture With Iagram: U N: 3 N Oracle 11g New FeaturesДокумент14 страницRacle G Rchitecture With Iagram: U N: 3 N Oracle 11g New FeaturesThirumal VankamОценок пока нет
- In Oracle MilieuДокумент6 страницIn Oracle MilieuzahirhussianОценок пока нет
- Oracle Book-Final FormattedДокумент168 страницOracle Book-Final Formattedkranthi633100% (1)
- ORACLE ClassДокумент26 страницORACLE Classssv pОценок пока нет
- Oracle Database Security: Presented by Wilson CriderДокумент94 страницыOracle Database Security: Presented by Wilson Cridersaravanand1983Оценок пока нет
- Oracle Database Administration Hand BookДокумент78 страницOracle Database Administration Hand Bookmarioy4783% (12)
- Oracle Architechture & ConceptsДокумент90 страницOracle Architechture & ConceptsElango GopalОценок пока нет
- Unit-I: Oracle Product DetailДокумент63 страницыUnit-I: Oracle Product DetailSaurabhОценок пока нет
- Introduction To CMIS 565 - Module 0Документ9 страницIntroduction To CMIS 565 - Module 0kamakom78Оценок пока нет
- Oracle Database Oracle Instance + Data Files: AsktomДокумент5 страницOracle Database Oracle Instance + Data Files: Asktomvaloo_phoolОценок пока нет
- Oracle SQLДокумент127 страницOracle SQLsoireeОценок пока нет
- Partha Resume ETL TestingДокумент4 страницыPartha Resume ETL TestingDivya SrinivasanОценок пока нет
- 1) Choose The Right Query For Getting The Last N Records From A Given Employee TableДокумент6 страниц1) Choose The Right Query For Getting The Last N Records From A Given Employee TableDivya SrinivasanОценок пока нет
- How When Writes QL in Pls QLДокумент24 страницыHow When Writes QL in Pls QLDivya SrinivasanОценок пока нет
- Analytics On Big Fast Data Using A Realtime Stream Data Processing ArchitectureДокумент34 страницыAnalytics On Big Fast Data Using A Realtime Stream Data Processing ArchitectureDivya SrinivasanОценок пока нет
- Philippine Psychometricians Licensure Exam RevieweДокумент1 страницаPhilippine Psychometricians Licensure Exam RevieweKristelle Mae C. Azucenas0% (1)
- Accounting TheoryДокумент192 страницыAccounting TheoryABDULLAH MOHAMMEDОценок пока нет
- Thai Reader Project Volume 2Документ215 страницThai Reader Project Volume 2geoffroОценок пока нет
- Transportation Research Part F: Andreas Lieberoth, Niels Holm Jensen, Thomas BredahlДокумент16 страницTransportation Research Part F: Andreas Lieberoth, Niels Holm Jensen, Thomas BredahlSayani MandalОценок пока нет
- Educational Metamorphosis Journal Vol 2 No 1Документ150 страницEducational Metamorphosis Journal Vol 2 No 1Nau RichoОценок пока нет
- Operations Management and Operations PerformanceДокумент59 страницOperations Management and Operations PerformancePauline LagtoОценок пока нет
- Isolasi Dan Karakterisasi Runutan Senyawa Metabolit Sekunder Fraksi Etil Asetat Dari Umbi Binahong Cord F L A Steen S)Документ12 страницIsolasi Dan Karakterisasi Runutan Senyawa Metabolit Sekunder Fraksi Etil Asetat Dari Umbi Binahong Cord F L A Steen S)Fajar ManikОценок пока нет
- Lee Gwan Cheung Resume WeeblyДокумент1 страницаLee Gwan Cheung Resume Weeblyapi-445443446Оценок пока нет
- VTU Result PDFДокумент2 страницыVTU Result PDFVaibhavОценок пока нет
- 10 Problems of Philosophy EssayДокумент3 страницы10 Problems of Philosophy EssayRandy MarshОценок пока нет
- Uprooted Radical Part 2 - NisiOisiN - LightДокумент307 страницUprooted Radical Part 2 - NisiOisiN - LightWillОценок пока нет
- Denmark Bayan enДокумент3 страницыDenmark Bayan enTyba314Оценок пока нет
- Decision Making and Problem Solving & Managing - Gashaw PDFДокумент69 страницDecision Making and Problem Solving & Managing - Gashaw PDFKokebu MekonnenОценок пока нет
- Watchitv Portable: Iptv Expert Analysis Application: Key ApplicationsДокумент5 страницWatchitv Portable: Iptv Expert Analysis Application: Key ApplicationsBen PoovinОценок пока нет
- NB-CPD IR 4r1 - Guidance For SGs On Their Role and Working MethodsДокумент19 страницNB-CPD IR 4r1 - Guidance For SGs On Their Role and Working MethodsmingulОценок пока нет
- List of Least Learned Competencies MAPEH7 1st To 3rd QuarterДокумент3 страницыList of Least Learned Competencies MAPEH7 1st To 3rd QuarterMark Dexter MejiaОценок пока нет
- 05 The Scriptures. New Testament. Hebrew-Greek-English Color Coded Interlinear: ActsДокумент382 страницы05 The Scriptures. New Testament. Hebrew-Greek-English Color Coded Interlinear: ActsMichaelОценок пока нет
- Nurse Implemented Goal Directed Strategy To.97972Документ7 страницNurse Implemented Goal Directed Strategy To.97972haslinaОценок пока нет
- Ejercicios VocalesДокумент10 страницEjercicios Vocalesjavier_adan826303Оценок пока нет
- Presentation of Times of India Newspaper SIPДокумент38 страницPresentation of Times of India Newspaper SIPPrakruti ThakkarОценок пока нет
- Diplomatic Quarter New Marriott Hotel & Executive ApartmentsДокумент1 страницаDiplomatic Quarter New Marriott Hotel & Executive Apartmentsconsultnadeem70Оценок пока нет
- Social Contract Theory - Internet Encyclopedia of PhilosophyДокумент28 страницSocial Contract Theory - Internet Encyclopedia of Philosophywolf1804100% (1)
- A Week in My CountryДокумент2 страницыA Week in My CountryAQhuewulland Youngprincess HokageNarutoОценок пока нет
- AMU BALLB (Hons.) 2018 SyllabusДокумент13 страницAMU BALLB (Hons.) 2018 SyllabusA y u s hОценок пока нет
- Magtajas vs. PryceДокумент3 страницыMagtajas vs. PryceRoyce PedemonteОценок пока нет
- The EagleДокумент4 страницыThe EagleJunkoОценок пока нет
- Capital Structure: Meaning and Theories Presented by Namrata Deb 1 PGDBMДокумент20 страницCapital Structure: Meaning and Theories Presented by Namrata Deb 1 PGDBMDhiraj SharmaОценок пока нет
- Sections 3 7Документ20 страницSections 3 7ninalgamaryroseОценок пока нет
- Basa BasaДокумент4 страницыBasa Basamarilou sorianoОценок пока нет
- Pavnissh K Sharma 9090101066 Ahmedabad, GujratДокумент51 страницаPavnissh K Sharma 9090101066 Ahmedabad, GujratPavnesh SharmaaОценок пока нет