Вам также может понравиться
- Control Maestro para Tiendas InteligentesДокумент53 страницыControl Maestro para Tiendas InteligentesOM CarlosОценок пока нет
- Unidad 2 - Norrmas y Estándares de Redes de DatosДокумент18 страницUnidad 2 - Norrmas y Estándares de Redes de DatosDenilson Daniel Dorantes ValadezОценок пока нет
- Tema 06 1 Manual Packet Tracer 5 2 140115111623 Phpapp02Документ216 страницTema 06 1 Manual Packet Tracer 5 2 140115111623 Phpapp02maria eugenia romero torresОценок пока нет
- RedesInalambricasIntroduccionДокумент36 страницRedesInalambricasIntroduccionJuan SalvadorОценок пока нет
- Programación del lado del servidorДокумент19 страницProgramación del lado del servidorEnrique NájeraОценок пока нет
- Redes Inalambricas 802.11bДокумент49 страницRedes Inalambricas 802.11bJehison AceroОценок пока нет
- U4 Sistemas OperativosДокумент8 страницU4 Sistemas OperativosBenito DelgadoОценок пока нет
- Wi-Fi y WiMaxДокумент17 страницWi-Fi y WiMaxpijiОценок пока нет
- 1.2 FallasДокумент12 страниц1.2 Fallasmanuel galvanОценок пока нет
- Comparación de Los SGBD Mas UsadosДокумент9 страницComparación de Los SGBD Mas UsadosAndré Jr SandovalОценок пока нет
- Capa de Enlace de DatosДокумент22 страницыCapa de Enlace de DatosEmma Tejeda MartínezОценок пока нет
- BC Basics (Español)Документ34 страницыBC Basics (Español)DeyaniraOjeda100% (2)
- Unidad I InstrumentacionДокумент29 страницUnidad I InstrumentacionIvan Vazquez TrujilloОценок пока нет
- Guia Reto GF0SДокумент50 страницGuia Reto GF0Spedro infanteОценок пока нет
- Esquema de SeguridadДокумент22 страницыEsquema de SeguridadEmmanuelHerreraZОценок пока нет
- Estándares buses manejoДокумент6 страницEstándares buses manejoBéjar Aguilar DavidОценок пока нет
- ANALIZADOR DE TRÁFICO Mi ProyectoДокумент7 страницANALIZADOR DE TRÁFICO Mi ProyectoBoris ZuñigaОценок пока нет
- Un Modelo Funcional para La Administración de Redes PDFДокумент10 страницUn Modelo Funcional para La Administración de Redes PDFDaira Almanza LОценок пока нет
- ModularizaciónДокумент14 страницModularizacióndavidmr905Оценок пока нет
- PW Ensayo JessicaMendezReynosoДокумент1 страницаPW Ensayo JessicaMendezReynosoJessii Ranita ReeynosoОценок пока нет
- Analisis LexicoДокумент15 страницAnalisis LexicoPaulina TerronesОценок пока нет
- Herramientas para El Flujo de DatosДокумент10 страницHerramientas para El Flujo de DatosMiguel Angel PoolОценок пока нет
- Dominios de colisión y broadcast en EthernetДокумент4 страницыDominios de colisión y broadcast en EthernetJaneth GaRciiaОценок пока нет
- UNIDAD 4 Redes InalambricasДокумент10 страницUNIDAD 4 Redes InalambricasPedrosky MoralesОценок пока нет
- Tecnologias Inalambricas COMPLETOДокумент44 страницыTecnologias Inalambricas COMPLETOËdiThYiYiОценок пока нет
- Cuadro ComparativoДокумент5 страницCuadro ComparativoAlfredo Avendaño SerranoОценок пока нет
- SistemasProgramables Unidad-5 CompletaДокумент9 страницSistemasProgramables Unidad-5 CompletaLuis Alejandro Escárcega FernándezОценок пока нет
- Unidad 4 Ex PonerДокумент38 страницUnidad 4 Ex Ponermontezco967% (3)
- Medir Varibales Fisicas en Tiempo Real Temperatura y PosicionДокумент8 страницMedir Varibales Fisicas en Tiempo Real Temperatura y Posicionaicardiño vasquez sanchezОценок пока нет
- Tipos de Notacion para La Conversion de Expresiones.Документ3 страницыTipos de Notacion para La Conversion de Expresiones.HernandezSalomonОценок пока нет
- Redes EmergentesДокумент91 страницаRedes EmergentesJessii Ranita ReeynosoОценок пока нет
- AutomatasДокумент28 страницAutomatasMharcelha Noyola MerinoОценок пока нет
- Unidad 5 SeguridadДокумент17 страницUnidad 5 SeguridadGustGCОценок пока нет
- Tareas y Tecnicas de RequisitosДокумент3 страницыTareas y Tecnicas de RequisitosjhiecooОценок пока нет
- Data Center FДокумент12 страницData Center FErick MartínezОценок пока нет
- Unidad 3 Tecnologias WANДокумент8 страницUnidad 3 Tecnologias WANManuel Alligheri LimaОценок пока нет
- Modelos de Arquitecturas de Cómputo.Документ7 страницModelos de Arquitecturas de Cómputo.CAAMAL CARLOS ALBERTOОценок пока нет
- Análisis Léxico: Reconocimiento de Identificadores y Expresiones RegularesДокумент39 страницAnálisis Léxico: Reconocimiento de Identificadores y Expresiones RegularesRAFAELA FLORES MORALESОценок пока нет
- Conm de Redes LANДокумент89 страницConm de Redes LANJhonatan perezОценок пока нет
- Investigacion Tecnologias WANДокумент53 страницыInvestigacion Tecnologias WANxavmarcial1978Оценок пока нет
- Administracion de Dispositivos de Entrada y SalidaДокумент29 страницAdministracion de Dispositivos de Entrada y SalidaJean Barreto RojasОценок пока нет
- Manual 5 y 6 Espejeo MonitoreoДокумент45 страницManual 5 y 6 Espejeo MonitoreoDasZero Maxwell100% (1)
- Dispositivos de ComunicaciónДокумент2 страницыDispositivos de ComunicaciónCarmelita_16Оценок пока нет
- Configurar Un Servidor FTP en Windows XPДокумент9 страницConfigurar Un Servidor FTP en Windows XPrinoyangelitoОценок пока нет
- Sistemas OperativosДокумент2 страницыSistemas OperativospabloОценок пока нет
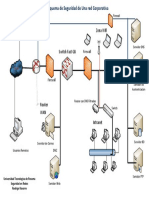
- Esquema de Seguridad Red Corporativa PDFДокумент1 страницаEsquema de Seguridad Red Corporativa PDFEma Smilingirl Alonso GarciaОценок пока нет
- Unidad #1 Introducción Al Lenguaje EnsambladorДокумент5 страницUnidad #1 Introducción Al Lenguaje EnsambladoringgafabifiОценок пока нет
- Sistemas Operativos I - Estructuras de datos para el manejo de dispositivosДокумент10 страницSistemas Operativos I - Estructuras de datos para el manejo de dispositivosFernando Fuentes BetancourtОценок пока нет
- Protocolo IEE 802.11Документ13 страницProtocolo IEE 802.11Daniela CortesОценок пока нет
- SoaДокумент6 страницSoaItno VargasОценок пока нет
- 3.2 MacrosДокумент11 страниц3.2 MacrosFrank DiazОценок пока нет
- U4 Interoperatividad Entre Sistemas OperativosДокумент32 страницыU4 Interoperatividad Entre Sistemas OperativosdanielОценок пока нет
- Diseño Logico de RedesДокумент15 страницDiseño Logico de RedesDaniel Puerta TabordaОценок пока нет
- Karq2 A1 U1 XXXXДокумент5 страницKarq2 A1 U1 XXXXIkusi CuentaОценок пока нет
- Sistemas Operativos en ServidoresДокумент16 страницSistemas Operativos en ServidoresJennifer Cañi YajaОценок пока нет
- Sintesis Canales SegurosДокумент5 страницSintesis Canales SegurosHugoValdezCarlonОценок пока нет
- Topologia de RedДокумент20 страницTopologia de RedRonaldoLP.AlvarezОценок пока нет
- Introduccion A Las Redes de DatosДокумент12 страницIntroduccion A Las Redes de Datoshinata968Оценок пока нет
- Topologías RedДокумент12 страницTopologías RedPaola Diago OrozcoОценок пока нет
- Unidad 4Документ24 страницыUnidad 4Daniel RG100% (1)
- Clasificacion de Los Servicios WebДокумент9 страницClasificacion de Los Servicios WebLeibel MHОценок пока нет
- Redes Punto A PuntoДокумент4 страницыRedes Punto A PuntoEfrainMfОценок пока нет
- Editor de código Sublime TextДокумент12 страницEditor de código Sublime TextAdam Gontier100% (1)
- Introducción A La Arquitectura de SoftwareДокумент51 страницаIntroducción A La Arquitectura de SoftwareMichelle Ysa ValeraОценок пока нет
- Manua IusuarioДокумент6 страницManua IusuarioAdam GontierОценок пока нет
- Modificacion de Aspecto de Pagina WebДокумент3 страницыModificacion de Aspecto de Pagina WebAdam GontierОценок пока нет
- (216864748) Capa2modeloosienlacededatos-120317220358-Phpapp01Документ28 страниц(216864748) Capa2modeloosienlacededatos-120317220358-Phpapp01Adam GontierОценок пока нет
- ItchelДокумент7 страницItchelAdam GontierОценок пока нет
- Introducción: Planificación y Administración de Redes Acceso Al WANДокумент12 страницIntroducción: Planificación y Administración de Redes Acceso Al WANfhanorm1854Оценок пока нет
- 2.1.-Arquitectura de Aplicaciones WebДокумент5 страниц2.1.-Arquitectura de Aplicaciones WebAdam GontierОценок пока нет
- 80 Preguntas de IA SS 8bISCДокумент9 страниц80 Preguntas de IA SS 8bISCAdam GontierОценок пока нет
- Sistemasoperativosderednos 120829121851 Phpapp02Документ26 страницSistemasoperativosderednos 120829121851 Phpapp02Adam GontierОценок пока нет
- Evolución Del SoftwareДокумент4 страницыEvolución Del SoftwareAdam GontierОценок пока нет
- Redes ComputadorasДокумент7 страницRedes ComputadorasJavier Salas SantosОценок пока нет
- Puntos de FuncionДокумент17 страницPuntos de FuncionAdam GontierОценок пока нет
- (300938238) 4-Cartas Sintacticas CompiladorДокумент7 страниц(300938238) 4-Cartas Sintacticas CompiladorAdam GontierОценок пока нет
- Gamaliel Alexandro Martinez MayoДокумент2 страницыGamaliel Alexandro Martinez MayoAdam GontierОценок пока нет
- Creación y administración de usuarios en Oracle DatabaseДокумент11 страницCreación y administración de usuarios en Oracle DatabaseAdam GontierОценок пока нет
- Convergencia de Redes Como Oportunidad para Innovar en Modelos de Negocio - ZTEДокумент48 страницConvergencia de Redes Como Oportunidad para Innovar en Modelos de Negocio - ZTEAdam GontierОценок пока нет
- Material para La ClaseДокумент22 страницыMaterial para La ClaseAdam GontierОценок пока нет
- Unidad 5 DSДокумент22 страницыUnidad 5 DSAdam GontierОценок пока нет
- Lenguaje CДокумент31 страницаLenguaje CAdam GontierОценок пока нет
- Creación y administración de usuarios en Oracle DatabaseДокумент11 страницCreación y administración de usuarios en Oracle DatabaseAdam GontierОценок пока нет
- Instalación y configuración de WAMPSERVER y creación de bases de datos y tablas en MySQL y PHPMyAdminДокумент39 страницInstalación y configuración de WAMPSERVER y creación de bases de datos y tablas en MySQL y PHPMyAdminMoises Martinez RiveraОценок пока нет
- Grajales 5 UnidadДокумент8 страницGrajales 5 UnidadAdam GontierОценок пока нет
- MSQLДокумент2 страницыMSQLAdam GontierОценок пока нет
- UNIDAD 4modelodiseñoДокумент5 страницUNIDAD 4modelodiseñoAdam GontierОценок пока нет
- Canales de Distribucin CognosДокумент26 страницCanales de Distribucin CognosAdam GontierОценок пока нет
- UNIDAD 4modelodiseñoДокумент5 страницUNIDAD 4modelodiseñoAdam GontierОценок пока нет
- Instalacion Del Sistema: Universidad GalileoДокумент168 страницInstalacion Del Sistema: Universidad GalileoKaren Betancourth RamosОценок пока нет
- Presentacion de La Capa de Transporte Del Modelo OsiДокумент23 страницыPresentacion de La Capa de Transporte Del Modelo OsiDaniel RoОценок пока нет
- Carga de Configuracion en SIU o TCUДокумент3 страницыCarga de Configuracion en SIU o TCUofasofasОценок пока нет
- Cambia contraseña WiFi modem TelmexДокумент15 страницCambia contraseña WiFi modem TelmexRocio PerezОценок пока нет
- DNP3Документ7 страницDNP3Francisco RamosОценок пока нет
- 3 2 1 Red Algoritmos de RuteoДокумент36 страниц3 2 1 Red Algoritmos de RuteoVictoria RVОценок пока нет
- Eigrp Vs OspfДокумент4 страницыEigrp Vs OspfsvittОценок пока нет
- Comando IPCONFIGДокумент2 страницыComando IPCONFIGjorge orozcoОценок пока нет
- Cap 03.1 Funcionalidad Y Protocolos de La Capa de Aplicacion PDFДокумент17 страницCap 03.1 Funcionalidad Y Protocolos de La Capa de Aplicacion PDFmartilloh2014Оценок пока нет
- Notas - Ruteo Básico en Redes IP - DДокумент73 страницыNotas - Ruteo Básico en Redes IP - DFer CebОценок пока нет
- Capa de TransporteДокумент16 страницCapa de TransporteJOSEPH ALEXANDER LAURA BUSTAMANTEОценок пока нет
- Modos Usuario y PrivilegiadoДокумент16 страницModos Usuario y PrivilegiadodubiОценок пока нет
- Redes Industriales IIДокумент38 страницRedes Industriales IIAlber Tobar Ayala0% (1)
- Modelo OSI - EJEMPLOSДокумент2 страницыModelo OSI - EJEMPLOSHardyGz100% (1)
- Conmutador (Dispositivo de Red)Документ5 страницConmutador (Dispositivo de Red)carlos9015Оценок пока нет
- Faiber Bernal - 10.4.1.3 Packet Tracer Multiuser - Implement Services Instructions IGДокумент10 страницFaiber Bernal - 10.4.1.3 Packet Tracer Multiuser - Implement Services Instructions IGSergio BernalОценок пока нет
- CCNA 1 Cisco v5.0 Capitulo 3 - Respuestas del examenДокумент6 страницCCNA 1 Cisco v5.0 Capitulo 3 - Respuestas del examenHolger ArévaloОценок пока нет
- 12.9.2-Lab - Configure-Ipv6-Addresses-On-Network-Devices - es-XLДокумент4 страницы12.9.2-Lab - Configure-Ipv6-Addresses-On-Network-Devices - es-XLAlexis CortesОценок пока нет
- Redes Ethernet e IEEE 802: Normas y TecnologíasДокумент44 страницыRedes Ethernet e IEEE 802: Normas y TecnologíasFP CarlitaОценок пока нет
- 3.2.2.4 Lab - Troubleshooting EtherChannel PDFДокумент7 страниц3.2.2.4 Lab - Troubleshooting EtherChannel PDFAdriana LopezОценок пока нет
- Aplicaciones Del Modelo OSIДокумент11 страницAplicaciones Del Modelo OSIJuan Pablo GramajoОценок пока нет
- Proyecto Redes de DatosДокумент1 страницаProyecto Redes de DatosRodrigo DazaОценок пока нет
- Configura tu router ArrisДокумент9 страницConfigura tu router ArrisvictorОценок пока нет
- Protocolo Contact-Id Acudah410Документ6 страницProtocolo Contact-Id Acudah410Ivan FonsecaОценок пока нет
- Actividad1 ACLДокумент3 страницыActividad1 ACLDANIELA PEREZ REYESОценок пока нет
- Ejercicio de SubneteoДокумент3 страницыEjercicio de SubneteoMarco Castillo LezamaОценок пока нет