Вам также может понравиться
- Can Television Be Good For ChildrenДокумент22 страницыCan Television Be Good For Childrencharusat100% (1)
- Low IncomeДокумент2 страницыLow IncomeAmandaОценок пока нет
- Media's Effects On ChildrenДокумент3 страницыMedia's Effects On Childrenvukasinzelic16Оценок пока нет
- The Educational Impact of Television UndДокумент22 страницыThe Educational Impact of Television UndFernanda RochaОценок пока нет
- Media and Young Children's LearningДокумент24 страницыMedia and Young Children's LearningHarini CalamurОценок пока нет
- Television Viewing Patterns in 6-To 18 - Month-Olds: The Role of Caregiver-Infant Interactional QualityДокумент21 страницаTelevision Viewing Patterns in 6-To 18 - Month-Olds: The Role of Caregiver-Infant Interactional QualityGeorgetownELPОценок пока нет
- Literature Review - Impact of TelevisionДокумент8 страницLiterature Review - Impact of Televisionapi-364386649100% (1)
- Advantages of Laptops - Argumentative Essay Sample PDFДокумент9 страницAdvantages of Laptops - Argumentative Essay Sample PDFKim Jae MinОценок пока нет
- Television and Media Literacy in Young Children: Issues and Effects in Early ChildhoodДокумент7 страницTelevision and Media Literacy in Young Children: Issues and Effects in Early ChildhoodLeonard Andrew ManuevoОценок пока нет
- Week 11 Reading 2Документ5 страницWeek 11 Reading 2Didar YANASОценок пока нет
- Making Good Decisions: Television, Learning, and The Cognitive Development of Young ChildrenДокумент5 страницMaking Good Decisions: Television, Learning, and The Cognitive Development of Young ChildrenUlfa Nurul AuliaОценок пока нет
- Background of The StudyДокумент22 страницыBackground of The StudyArgie BarracaОценок пока нет
- Language Acquisition and Infant's Exposure To Television in Pakistan: Phenomenological Study of Mother's ExperiencesДокумент11 страницLanguage Acquisition and Infant's Exposure To Television in Pakistan: Phenomenological Study of Mother's ExperiencesSky AerisОценок пока нет
- TV Language Early Years 2004Документ46 страницTV Language Early Years 2004Raluca Andreea PetcuОценок пока нет
- Journal Children MediaДокумент18 страницJournal Children MediaMaleka330Оценок пока нет
- Diaryquestionnairetv 2Документ17 страницDiaryquestionnairetv 2GeorgetownELPОценок пока нет
- The Effects of Watching TV Cartoon Program On The Behavior of Grade One Pupils in Brion-Silva Elementary SchoolДокумент34 страницыThe Effects of Watching TV Cartoon Program On The Behavior of Grade One Pupils in Brion-Silva Elementary SchoolMelannie D Arcenas100% (2)
- Effects of Media Violence On ChildrenДокумент18 страницEffects of Media Violence On ChildrendavorshОценок пока нет
- Reading p202311131639Документ7 страницReading p202311131639nguyenhuuhung2610dbОценок пока нет
- DR - SalwaSAl Harbi46522 160160 1 PBДокумент6 страницDR - SalwaSAl Harbi46522 160160 1 PBGiemer HerreraОценок пока нет
- Warren 2006 PDFДокумент29 страницWarren 2006 PDFErika P. Muchica PizarroОценок пока нет
- Using Augmentative Communication With Infants and Young Children With Down SyndromeДокумент0 страницUsing Augmentative Communication With Infants and Young Children With Down SyndromeDini KohandiОценок пока нет
- Baby Mozart 2008Документ28 страницBaby Mozart 2008GeorgetownELPОценок пока нет
- Dayanim - Et - Al-2015-Child - Development 2Документ12 страницDayanim - Et - Al-2015-Child - Development 2赵青Оценок пока нет
- Chapter-2 Literature ReviewДокумент15 страницChapter-2 Literature Reviewhg plОценок пока нет
- Peer Review Journal ArticleДокумент7 страницPeer Review Journal Articleapi-507432876Оценок пока нет
- The in Uence of Media in Children's Language Development: March 2015Документ6 страницThe in Uence of Media in Children's Language Development: March 2015syafiqhasyikinbintishamsudddinОценок пока нет
- Quality Criteria in children TV: Narrative and Script Writing for Children’s TV 0-6От EverandQuality Criteria in children TV: Narrative and Script Writing for Children’s TV 0-6Оценок пока нет
- Developmental Review: Mary L. Courage, Mark L. HoweДокумент15 страницDevelopmental Review: Mary L. Courage, Mark L. HoweMónika MikeОценок пока нет
- KaufmanДокумент5 страницKaufmanGabriella HarasztiОценок пока нет
- A Prospective Study of The Relationship Between SLI, PH DisДокумент25 страницA Prospective Study of The Relationship Between SLI, PH DiscynthiaОценок пока нет
- The Effect of Repetition On Imitation From Television During InfancyДокумент12 страницThe Effect of Repetition On Imitation From Television During Infancyalex_brito84Оценок пока нет
- Annotated Bibliography On The Effects of Media On Early Childhood DevelopmentДокумент6 страницAnnotated Bibliography On The Effects of Media On Early Childhood Developmentbateskm100% (1)
- ProQuestDocuments 1Документ21 страницаProQuestDocuments 1buolОценок пока нет
- Children and The MediaДокумент12 страницChildren and The MediaanoviОценок пока нет
- Follow-Up of Children Attending Infant Language Units: Outcomes at 11 Years of AgeДокумент13 страницFollow-Up of Children Attending Infant Language Units: Outcomes at 11 Years of AgeFelipe TorresОценок пока нет
- Nursery Rhymes, Phonological Skills and Reading: Journal of Child Language July 1989Документ24 страницыNursery Rhymes, Phonological Skills and Reading: Journal of Child Language July 1989Bunmi Bdaejo Bunmi BadejoОценок пока нет
- Recast' in A New Light: Insights For Practice From Typical Language StudiesДокумент17 страницRecast' in A New Light: Insights For Practice From Typical Language StudiesRafik AhmedОценок пока нет
- Infant Behavior and DevelopmentДокумент8 страницInfant Behavior and DevelopmentGeorgetownELPОценок пока нет
- Impact of Television Programs and Advertisements On School Going Adolescents: A Case Study of Bahawalpur City, PakistanДокумент12 страницImpact of Television Programs and Advertisements On School Going Adolescents: A Case Study of Bahawalpur City, PakistanAjjuguttuSandeepReddyОценок пока нет
- Gomba, Mariella Denice P. Children's Educational Television Programming and Prod. Activity 1 Coc-Babr 3-1Документ3 страницыGomba, Mariella Denice P. Children's Educational Television Programming and Prod. Activity 1 Coc-Babr 3-1John Vincent DelacruzОценок пока нет
- Educational Impact of TelevisionДокумент23 страницыEducational Impact of Televisiondc.dilek01Оценок пока нет
- The Effect of Text Messaging OnДокумент9 страницThe Effect of Text Messaging OnAndrés CastilloОценок пока нет
- Chapter One 1.1 Backgrounds To The StudyДокумент5 страницChapter One 1.1 Backgrounds To The StudyAdediran DolapoОценок пока нет
- The Effects of Televesion On ChildrenДокумент5 страницThe Effects of Televesion On ChildrenISLAMICULTURE100% (6)
- Reel TimeДокумент26 страницReel TimeAmen MartzОценок пока нет
- Research Proposal: ProjectДокумент7 страницResearch Proposal: ProjectrabiaОценок пока нет
- Communication Development Report (CDR) : A Parent Report Instrument For The Early Screening of Communication and Language Development in Greek-Speaking Infants and ToddlersДокумент26 страницCommunication Development Report (CDR) : A Parent Report Instrument For The Early Screening of Communication and Language Development in Greek-Speaking Infants and ToddlersAlexia KarousouОценок пока нет
- 2005 01 AcostaДокумент22 страницы2005 01 Acostamarchtwentyseven72Оценок пока нет
- The Early CatastropheДокумент6 страницThe Early CatastropheMitchell DavisОценок пока нет
- Mitos de Los SaacsДокумент12 страницMitos de Los Saacsdesco2011Оценок пока нет
- Foundational TuningДокумент13 страницFoundational TuningjiyaskitchenОценок пока нет
- 1 s2.0 S0163638321000631 MainДокумент6 страниц1 s2.0 S0163638321000631 MainAngana NandyОценок пока нет
- Second Language Acquisition EssayДокумент7 страницSecond Language Acquisition EssayManuela MihelićОценок пока нет
- Group 4 Lived Experiences On Parental Guiding Original.Документ10 страницGroup 4 Lived Experiences On Parental Guiding Original.Richmar Tabuelog CabañeroОценок пока нет
- 04 Texto - Lisa BaumwellДокумент12 страниц04 Texto - Lisa BaumwellFlor De Maria Mikkelsen RamellaОценок пока нет
- Gale Researcher Guide for: Comprehension and Meaning in LanguageОт EverandGale Researcher Guide for: Comprehension and Meaning in LanguageОценок пока нет
- Many Languages, Building Connections: Supporting Infants and Toddlers Who Are Dual Language LearnersОт EverandMany Languages, Building Connections: Supporting Infants and Toddlers Who Are Dual Language LearnersРейтинг: 2 из 5 звезд2/5 (1)
- Preschool Clues: Raising Smart, Inspired, and Engaged Kids in a Screen-Filled WorldОт EverandPreschool Clues: Raising Smart, Inspired, and Engaged Kids in a Screen-Filled WorldОценок пока нет
- Are Brains "Gay"?: Chapter EightДокумент23 страницыAre Brains "Gay"?: Chapter EightJames Gildardo CuasmayànОценок пока нет
- The Transpersonal SelfДокумент225 страницThe Transpersonal SelfJames Gildardo CuasmayànОценок пока нет
- The Regret and Disappointment Scale: An Instrument For Assessing Regret and Disappointment in Decision MakingДокумент13 страницThe Regret and Disappointment Scale: An Instrument For Assessing Regret and Disappointment in Decision MakingJames Gildardo CuasmayànОценок пока нет
- Utility of Ordinal ScalesДокумент16 страницUtility of Ordinal ScalesJames Gildardo CuasmayànОценок пока нет
- VirtuMVP Operation ManualДокумент21 страницаVirtuMVP Operation ManualJames Gildardo CuasmayànОценок пока нет
- Two Word UtterancesДокумент18 страницTwo Word UtterancesJames Gildardo CuasmayànОценок пока нет
- Creativity-Productivity in Child's LanguageДокумент13 страницCreativity-Productivity in Child's LanguageJames Gildardo CuasmayànОценок пока нет
- Language and CognitionДокумент10 страницLanguage and CognitionJames Gildardo CuasmayànОценок пока нет
- Grammar in Discrimination, ImitationДокумент14 страницGrammar in Discrimination, ImitationJames Gildardo CuasmayànОценок пока нет
- A Longitudinal Study of Bilingual Development in Infants: SciencedirectДокумент5 страницA Longitudinal Study of Bilingual Development in Infants: SciencedirectJames Gildardo CuasmayànОценок пока нет
- NCM 57: Health AssessmentДокумент2 страницыNCM 57: Health AssessmentEmvie Loyd Pagunsan-ItableОценок пока нет
- Universal DesignДокумент14 страницUniversal Designapi-365230869100% (1)
- Effects of Child Marriage On Girls Education and EmpowermentДокумент8 страницEffects of Child Marriage On Girls Education and EmpowermentAbdulОценок пока нет
- Isolation Precautions: Airborne ( - Pressure Room) Droplet (3ft Rule) ContactДокумент3 страницыIsolation Precautions: Airborne ( - Pressure Room) Droplet (3ft Rule) ContactLisa CapraОценок пока нет
- XAS 88 KDДокумент4 страницыXAS 88 KDNuno PaivaОценок пока нет
- I4 SG Week 2Документ1 страницаI4 SG Week 2Ziyang Huaman BazanОценок пока нет
- Conditional Clauses - Type IДокумент2 страницыConditional Clauses - Type Icarol0801Оценок пока нет
- BAMA 516 Customer Relationship Management - Feb2020Документ6 страницBAMA 516 Customer Relationship Management - Feb2020sherryОценок пока нет
- How To Make GIS A Common Educational TooДокумент11 страницHow To Make GIS A Common Educational TooGeomatique GestionОценок пока нет
- The Design of Small Slot ArraysДокумент6 страницThe Design of Small Slot ArraysRoberto B. Di RennaОценок пока нет
- Ogl 320 FinalДокумент4 страницыOgl 320 Finalapi-239499123Оценок пока нет
- Ata 46Документ28 страницAta 46Zbor Zbor100% (1)
- Diss 14Документ4 страницыDiss 14Marc EstañoОценок пока нет
- NSTP 1 Mac & Sac Syllabus 1st Sem 16-17Документ2 страницыNSTP 1 Mac & Sac Syllabus 1st Sem 16-17Arriel TingОценок пока нет
- Word Embedding 9 Mar 23 PDFДокумент16 страницWord Embedding 9 Mar 23 PDFarpan singhОценок пока нет
- Synopsis of Railway ReservationДокумент14 страницSynopsis of Railway ReservationBhojRaj Yadav100% (1)
- Adrienne D Hunter - Art For Children Experiencing Psychological Trauma - A Guide For Educators and School-Based Professionals-Routledge (2018)Документ321 страницаAdrienne D Hunter - Art For Children Experiencing Psychological Trauma - A Guide For Educators and School-Based Professionals-Routledge (2018)Sonia PuarОценок пока нет
- English HL Gr. 4Документ9 страницEnglish HL Gr. 4nadinevanwykrОценок пока нет
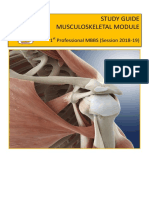
- Study Guide Musculoskeletal Module: 1 Professional MBBS (Session 2018-19)Документ42 страницыStudy Guide Musculoskeletal Module: 1 Professional MBBS (Session 2018-19)Shariq KhattakОценок пока нет
- Art Therapy DV.280101208Документ40 страницArt Therapy DV.280101208Mas AditОценок пока нет
- Kodály Method - Wikipedia, The Free EncyclopediaДокумент5 страницKodály Method - Wikipedia, The Free EncyclopediaSalvatore BellaviaОценок пока нет
- NHEF - APPLICATION Guide 2023Документ7 страницNHEF - APPLICATION Guide 2023Oyin AyoОценок пока нет
- Class Plan Teens 2Документ1 страницаClass Plan Teens 2Elton JonhОценок пока нет
- Deepankar BishtДокумент3 страницыDeepankar BishtRahul YadavОценок пока нет
- Mahatma Jyotiba Phule Rohilkhand University, Bareilly: Examination Session (2021 - 2022)Документ2 страницыMahatma Jyotiba Phule Rohilkhand University, Bareilly: Examination Session (2021 - 2022)Health AdviceОценок пока нет
- Case Study - Challenger Ethical IssuesДокумент7 страницCase Study - Challenger Ethical IssuesFaizi MalikzОценок пока нет
- National Strength and Conditioning Association.1Документ19 страницNational Strength and Conditioning Association.1Joewin EdbergОценок пока нет
- Action Plan-LACДокумент1 страницаAction Plan-LACNimz Eda Anino-Albarico JimenezОценок пока нет
- GMath2Q3Week7Day1 4Документ15 страницGMath2Q3Week7Day1 4Jerick JohnОценок пока нет
- Mis VacacionesДокумент6 страницMis VacacionesYliana MoraОценок пока нет