Вам также может понравиться
- Curso de Introducción a la Administración de Bases de DatosОт EverandCurso de Introducción a la Administración de Bases de DatosРейтинг: 3 из 5 звезд3/5 (1)
- Minería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásОт EverandMinería de Datos: Guía de Minería de Datos para Principiantes, que Incluye Aplicaciones para Negocios, Técnicas de Minería de Datos, Conceptos y MásРейтинг: 4.5 из 5 звезд4.5/5 (4)
- Actividad Aplicada ContextualizaciónДокумент11 страницActividad Aplicada ContextualizaciónJhonatan AndrésОценок пока нет
- B2 Resumen ClaudiaPamelaAmadorGarcesДокумент5 страницB2 Resumen ClaudiaPamelaAmadorGarcesPamela GarcesОценок пока нет
- Método de Estimación Del Empleo - BIG DATAДокумент23 страницыMétodo de Estimación Del Empleo - BIG DATAlucas perezОценок пока нет
- Limpieza de DatosДокумент5 страницLimpieza de DatosJavier CortesОценок пока нет
- Tarea 2Документ6 страницTarea 2Franco QuintanaОценок пока нет
- Proceso KDDДокумент7 страницProceso KDDCarlitos Valentin LaureanoОценок пока нет
- Javier Serrano Control 2Документ5 страницJavier Serrano Control 2Javier Andres Serrano LeivaОценок пока нет
- Cid 2019B Inni T2 2a Lvis.Документ5 страницCid 2019B Inni T2 2a Lvis.pepenarОценок пока нет
- Unidad 2Документ31 страницаUnidad 2Luis Eduardo MorenoОценок пока нет
- Evidencia 1 - Big Data AvanceДокумент4 страницыEvidencia 1 - Big Data Avancefiorella de los milagros vasques yamunaqueОценок пока нет
- Captura y AlmacenamientoДокумент27 страницCaptura y AlmacenamientoDanny Valencia G.Оценок пока нет
- Trabajo 1 Semana 5Документ5 страницTrabajo 1 Semana 5Loreto ToledoОценок пока нет
- Presentacion Mineria DatosДокумент20 страницPresentacion Mineria Datoskarenleon25Оценок пока нет
- Tema05 Preprocesamiento de Datos 2015 16Документ171 страницаTema05 Preprocesamiento de Datos 2015 16karen dejoОценок пока нет
- Mineria de DatosДокумент3 страницыMineria de DatosAndy GuevaraОценок пока нет
- Big Data AA1Документ5 страницBig Data AA1Kenedy JhonОценок пока нет
- Aa1 OficialДокумент27 страницAa1 OficialJesús Alberto Barraza vicenteОценок пока нет
- Mineria de DatosДокумент11 страницMineria de DatosNando PinargoОценок пока нет
- Mineria de Datos FinalДокумент75 страницMineria de Datos FinalMax FuentesОценок пока нет
- Acin217 s1 Encina3Документ10 страницAcin217 s1 Encina3melissa rivera godoyОценок пока нет
- Tema04 Preprocesamiento de Datos 2018 19Документ185 страницTema04 Preprocesamiento de Datos 2018 19antonylazzo1977Оценок пока нет
- KDD Vs Minería de Datos - Pasos KDDДокумент5 страницKDD Vs Minería de Datos - Pasos KDDjuan quijadaОценок пока нет
- I7725 - 2022B UN 1 AC 2 EL Proceso de DescubrimientoДокумент11 страницI7725 - 2022B UN 1 AC 2 EL Proceso de DescubrimientoJaasiel Alejandro Castellanos GomezОценок пока нет
- Ensayo IntroducciónДокумент7 страницEnsayo IntroducciónDolores Vicger ChiquitoОценок пока нет
- Actividad Contextualización 2Документ23 страницыActividad Contextualización 2Holman RodriguezОценок пока нет
- Tema 04Документ181 страницаTema 04Richi Lozano DomingezОценок пока нет
- YohadriДокумент9 страницYohadriladyОценок пока нет
- Produccion T11-15Документ5 страницProduccion T11-15cehowo8997Оценок пока нет
- Ensayo Mineria de DatosДокумент5 страницEnsayo Mineria de DatosLizeth Arely Garcia100% (1)
- Mcomii U1 A1 DishДокумент4 страницыMcomii U1 A1 DishDiana Angelica SandovalОценок пока нет
- Base de DatosДокумент18 страницBase de DatosRaylin CalderónОценок пока нет
- Data MiningДокумент8 страницData Miningkevin perezОценок пока нет
- IBM Quality StageДокумент14 страницIBM Quality StageCarlos TakanoОценок пока нет
- INVESTIGACIONДокумент9 страницINVESTIGACIONLuiss baezaОценок пока нет
- Proceso de Datos Tema 13Документ5 страницProceso de Datos Tema 13Gilberto Castillo SaucedoОценок пока нет
- Data MiningДокумент5 страницData MiningJasmin BaqueОценок пока нет
- P4-Preparación de Los DatosДокумент34 страницыP4-Preparación de Los DatosBrandon DuarteОценок пока нет
- Analsis de Datos Tecnicas y EstretegiasДокумент3 страницыAnalsis de Datos Tecnicas y EstretegiasJose CedeñoОценок пока нет
- TerminologíaДокумент3 страницыTerminologíaAmmy YugchaОценок пока нет
- Tecnológico de Estudios Superiores de TianguistencoДокумент22 страницыTecnológico de Estudios Superiores de TianguistencoEnrique Emiliano Santos CantúОценок пока нет
- Parte 1 - Clase 15 - Data Wrangling IДокумент6 страницParte 1 - Clase 15 - Data Wrangling IPaul VásquezОценок пока нет
- Qué Es La Ciencia de DatosДокумент20 страницQué Es La Ciencia de Datosveila martinezОценок пока нет
- Big DataДокумент3 страницыBig DataYouli Albert RondonОценок пока нет
- Ant Tecnologiasdeinformacionenlaempresa B4Документ9 страницAnt Tecnologiasdeinformacionenlaempresa B4ds0935153Оценок пока нет
- Ensayo Importancia de Los Datos - AtiДокумент10 страницEnsayo Importancia de Los Datos - AtiOdalys Rivas100% (1)
- Proyecto Sistemas Mineria de DatosДокумент16 страницProyecto Sistemas Mineria de DatosCarlos AvilesОценок пока нет
- Act Datos No EstructuradosДокумент4 страницыAct Datos No EstructuradosCristian Steven CORZO SALAS100% (1)
- Actividad Final Diseño y Administracion de Base de DatosДокумент14 страницActividad Final Diseño y Administracion de Base de Datoscesar.rdzramОценок пока нет
- Procesamiento de DatosДокумент7 страницProcesamiento de Datosyorgeni moronОценок пока нет
- 13.mineria de Datos Erika Vilches Gonzalez e Ivan Escobar BroitmanДокумент7 страниц13.mineria de Datos Erika Vilches Gonzalez e Ivan Escobar Broitmansolinfags1Оценок пока нет
- Clase 5 FCD 24052023Документ36 страницClase 5 FCD 24052023Jonathan Avila BerriosОценок пока нет
- Nota Técnica #3. Explotación de Datos - AnalíticaДокумент45 страницNota Técnica #3. Explotación de Datos - AnalíticaKaelyn CorderoОценок пока нет
- Ensayo Big DataДокумент6 страницEnsayo Big Datatatiana bautistaОценок пока нет
- Evaluación N°5:Big Data InvestigacionДокумент10 страницEvaluación N°5:Big Data InvestigacionRichard TobarОценок пока нет
- Sesión 7 y 8Документ64 страницыSesión 7 y 8antonioОценок пока нет
- Apuntes Big DataДокумент22 страницыApuntes Big DataJose Manuel Araujo OrregoОценок пока нет
- MineriaДокумент8 страницMineriaAngelОценок пока нет
- Ciencia de datos: La serie de conocimientos esenciales de MIT PressОт EverandCiencia de datos: La serie de conocimientos esenciales de MIT PressРейтинг: 5 из 5 звезд5/5 (1)
- Ambiente Salud Unidad 2 Texto 2Документ172 страницыAmbiente Salud Unidad 2 Texto 2gerccantom1365100% (2)
- Pedagogia Del ComprendimientoДокумент78 страницPedagogia Del Comprendimientogerccantom1365100% (1)
- Ambiente Salud Unidad 2 Texto 4 AvanzadoДокумент170 страницAmbiente Salud Unidad 2 Texto 4 Avanzadogerccantom136588% (8)
- Fasciculo 1Документ7 страницFasciculo 1gerccantom1365Оценок пока нет
- Optimizacion Instalaciones Taller PDFДокумент152 страницыOptimizacion Instalaciones Taller PDFgerccantom1365Оценок пока нет
- Optimizacion Instalaciones Taller PDFДокумент152 страницыOptimizacion Instalaciones Taller PDFgerccantom1365Оценок пока нет
- Taller Desarrollo Habilidades Docentes PDFДокумент39 страницTaller Desarrollo Habilidades Docentes PDFgerccantom1365100% (1)
- Método de Planificación ZoppДокумент5 страницMétodo de Planificación Zoppgerccantom1365Оценок пока нет
- PlaneacionДокумент5 страницPlaneaciongerccantom1365Оценок пока нет
- PlanificacionДокумент8 страницPlanificaciongerccantom1365Оценок пока нет
- Diagnostico Del PeiДокумент14 страницDiagnostico Del Peigerccantom13650% (1)
- Compromiso 3Документ1 страницаCompromiso 3gerccantom1365Оценок пока нет
- Ejercicios de Comprensión de Lectura #6Документ9 страницEjercicios de Comprensión de Lectura #6gerccantom1365Оценок пока нет
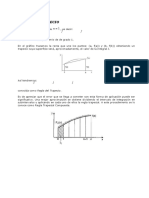
- TRAPECIOДокумент12 страницTRAPECIOChar MaciasОценок пока нет
- BIM Ignacio Muñoz (P3)Документ21 страницаBIM Ignacio Muñoz (P3)Ignacio Muñoz BizamaОценок пока нет
- Lenguaje de Programación I - Piad-207 - MaterialДокумент46 страницLenguaje de Programación I - Piad-207 - MaterialJohan GamarraОценок пока нет
- Epoch LT Training - 2006Документ44 страницыEpoch LT Training - 2006marceloolearojasОценок пока нет
- Capitulo 3 - Diseño de La EcuДокумент26 страницCapitulo 3 - Diseño de La EcuTecnico A Lazaro Cardenas100% (1)
- Modulo de Bienes Corrientes Siga PDFДокумент77 страницModulo de Bienes Corrientes Siga PDFFelipe FyrОценок пока нет
- Presentacion AvogadroДокумент22 страницыPresentacion AvogadroANDRES FELIPE ROMERO SALGADOОценок пока нет
- Paqueterias Que Existen para El Desarrollo de Expedientes DigitalesДокумент12 страницPaqueterias Que Existen para El Desarrollo de Expedientes DigitalesOmar Torres100% (3)
- Servidor de Correo Centos y ExchangeДокумент14 страницServidor de Correo Centos y ExchangeCaro VLОценок пока нет
- Normas Estándares Referentes A Interfaz en SistemasДокумент9 страницNormas Estándares Referentes A Interfaz en Sistemasgcuellar1Оценок пока нет
- Informe Pasantía, Sistema de Control de PrestamosДокумент86 страницInforme Pasantía, Sistema de Control de PrestamosNelson TorresОценок пока нет
- Cartilla Digital CVM3DДокумент3 страницыCartilla Digital CVM3DJuan david Requelme abrigoОценок пока нет
- Experiencia 3 Respuesta en Baja FrecuenciaДокумент23 страницыExperiencia 3 Respuesta en Baja FrecuenciaMARLON HENRY PANDURO AUCCASIОценок пока нет
- Auditoria de Seguridad Informatica y de Proteccion de Datos PersonalesДокумент6 страницAuditoria de Seguridad Informatica y de Proteccion de Datos PersonalesLuis GonzalezОценок пока нет
- Modulo Computo 1º Primaria - LNF - 1Документ68 страницModulo Computo 1º Primaria - LNF - 1Geraldine Leiva EspejoОценок пока нет
- Pic16f877 en Español1Документ20 страницPic16f877 en Español1silviog100% (90)
- Manual Usuario Ibmip334Документ145 страницManual Usuario Ibmip334Ivan GomezОценок пока нет
- Diccionario de DatosДокумент9 страницDiccionario de DatosJhonatan Murcia PossoОценок пока нет
- Laboratorio 04 - Seguridad en WiFi - RadiusДокумент13 страницLaboratorio 04 - Seguridad en WiFi - RadiusLeonardo LeoОценок пока нет
- ScalaДокумент44 страницыScalaChristian CastellanosОценок пока нет
- Colegios Comuna LimacheДокумент5 страницColegios Comuna Limachemaría luz salinas luceroОценок пока нет
- Resetear El Router A La Configuración de FábricaДокумент10 страницResetear El Router A La Configuración de FábricaEnrique Paré EstradaОценок пока нет
- TELEINFORMATICAДокумент218 страницTELEINFORMATICAOmar Jose Ortega MorenoОценок пока нет
- Tema 5Документ66 страницTema 5Elena HdezОценок пока нет
- La - Biblia.De - Mysql Anaya - Multimedia PDFДокумент841 страницаLa - Biblia.De - Mysql Anaya - Multimedia PDFChory_JM100% (1)
- Lectura Literal 2Документ11 страницLectura Literal 2ldawn100% (2)
- Sistema Ms DosДокумент13 страницSistema Ms DosEdwin BaranОценок пока нет
- Manual Español XMeye v1.0Документ9 страницManual Español XMeye v1.0charly sosОценок пока нет
- Diseño e Implementación de Una Arquitectura Abierta para El Robot A465 Con Consola Virtual para Visualización de Movimientos PDFДокумент128 страницDiseño e Implementación de Una Arquitectura Abierta para El Robot A465 Con Consola Virtual para Visualización de Movimientos PDFLS Xol FifoОценок пока нет
- Taller Redes Linux Con VirtualBoxДокумент37 страницTaller Redes Linux Con VirtualBoxLuisAlFeCoОценок пока нет