Вам также может понравиться
- Simulation of Dynamic Grid Replication Strategies in OptorsimДокумент15 страницSimulation of Dynamic Grid Replication Strategies in OptorsimmcemceОценок пока нет
- Scan Primitives For Vector ComputersДокумент10 страницScan Primitives For Vector ComputersAnonymous RrGVQjОценок пока нет
- The Data Locality of Work Stealing: Theory of Computing SystemsДокумент27 страницThe Data Locality of Work Stealing: Theory of Computing SystemsAnonymous RrGVQjОценок пока нет
- A Data Throughput Prediction Using Scheduling and Assignment TechniqueДокумент5 страницA Data Throughput Prediction Using Scheduling and Assignment TechniqueInternational Journal of computational Engineering research (IJCER)Оценок пока нет
- Rahul PandeyДокумент10 страницRahul PandeybarunluckyОценок пока нет
- Optorsim: A Simulation Tool For Scheduling and Replica Optimisation in Data GridsДокумент4 страницыOptorsim: A Simulation Tool For Scheduling and Replica Optimisation in Data GridsosbihatОценок пока нет
- Alarm Correlation Analysis in SDH Network Failure: Zhen-Dong Zhao Huang Nan Zi-Han LiДокумент3 страницыAlarm Correlation Analysis in SDH Network Failure: Zhen-Dong Zhao Huang Nan Zi-Han LiAbdellah SamadiОценок пока нет
- Fuse Abdolrashidi 2019Документ6 страницFuse Abdolrashidi 2019GuilhermeОценок пока нет
- MCS 041 2011Документ7 страницMCS 041 2011peetkumarОценок пока нет
- Computation of Storage Requirements For Multi-Dimensional Signal Processing ApplicationsДокумент14 страницComputation of Storage Requirements For Multi-Dimensional Signal Processing ApplicationsSudhakar SpartanОценок пока нет
- AA-Test-1 - HandoutДокумент11 страницAA-Test-1 - HandoutDM STUDIO TUBEОценок пока нет
- Abstract: Resume:: Categoriesandsubjectdescriptors: Generalterms: KeywordsДокумент2 страницыAbstract: Resume:: Categoriesandsubjectdescriptors: Generalterms: Keywordsberramla27Оценок пока нет
- Sensor PerfДокумент12 страницSensor Perfenaam1977Оценок пока нет
- Study of Page Replacement Algorithm Based On Experiment: Wang HongДокумент5 страницStudy of Page Replacement Algorithm Based On Experiment: Wang HongvinjamurisivaОценок пока нет
- AssignmentДокумент3 страницыAssignmentKARANJEET SinghОценок пока нет
- LHC AssignmentДокумент8 страницLHC AssignmentprayagrajdelhiОценок пока нет
- MCSE011Документ21 страницаMCSE011Aswathy SureshОценок пока нет
- DS Unit 1 PDFДокумент19 страницDS Unit 1 PDFNikhil NikkiОценок пока нет
- Parallel Quicksort Implementation Using Mpi and Pthreads: Puneet Kataria RUID - 117004233Документ14 страницParallel Quicksort Implementation Using Mpi and Pthreads: Puneet Kataria RUID - 117004233fffОценок пока нет
- DC AssignmentДокумент3 страницыDC AssignmentChandra SinghОценок пока нет
- Shift Register Petri NetДокумент7 страницShift Register Petri NetEduОценок пока нет
- Icase: IIII11l11ll IllДокумент26 страницIcase: IIII11l11ll IllSk SharmaОценок пока нет
- Workflow Hpdc10Документ13 страницWorkflow Hpdc10Santhosh B AcharyaОценок пока нет
- Performance Analysis of Distributed Real-Time Databases: Petri NetДокумент11 страницPerformance Analysis of Distributed Real-Time Databases: Petri NetSwati GaurОценок пока нет
- Multicore Software Development Techniques: Applications, Tips, and TricksОт EverandMulticore Software Development Techniques: Applications, Tips, and TricksРейтинг: 2.5 из 5 звезд2.5/5 (2)
- An Optimized Distributed Association Rule Mining Algorithm in Parallel and Distributed Data Mining With XML Data For Improved Response TimeДокумент14 страницAn Optimized Distributed Association Rule Mining Algorithm in Parallel and Distributed Data Mining With XML Data For Improved Response TimeAshish PatelОценок пока нет
- Implementation of Dynamic Level Scheduling Algorithm Using Genetic OperatorsДокумент5 страницImplementation of Dynamic Level Scheduling Algorithm Using Genetic OperatorsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Short Papers: An Efficient and Regular Routing Methodology For Datapath Designs Using Net Regularity ExtractionДокумент9 страницShort Papers: An Efficient and Regular Routing Methodology For Datapath Designs Using Net Regularity ExtractionSurya Ganesh PenagantiОценок пока нет
- OS - IAT3 Two Marks QB PDFДокумент4 страницыOS - IAT3 Two Marks QB PDF21ITA10 KANNATHALОценок пока нет
- IGNOU MCA MCS-41 Solved Assignment 2011: TH THДокумент8 страницIGNOU MCA MCS-41 Solved Assignment 2011: TH THMahesh BhattОценок пока нет
- The Effect of Embedded Epistemologies On Cyberinformatics: Gary Hofstarted, Julian Sheldon and Mike ScitptyДокумент6 страницThe Effect of Embedded Epistemologies On Cyberinformatics: Gary Hofstarted, Julian Sheldon and Mike ScitptyMichael Jacob MathewОценок пока нет
- Survey On MultiCore Operation SystemsДокумент9 страницSurvey On MultiCore Operation SystemsMuhammad TalalОценок пока нет
- Very High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic DevicesДокумент5 страницVery High-Level Synthesis of Datapath and Control Structures For Reconfigurable Logic Devices8148593856Оценок пока нет
- Lossless Theory For SchemeДокумент6 страницLossless Theory For SchemeVinicius UchoaОценок пока нет
- Data Driven Clock Gating: Bar Ilan University School of Engineering Vlsi LabДокумент34 страницыData Driven Clock Gating: Bar Ilan University School of Engineering Vlsi LabaanbalanОценок пока нет
- Hybrid Fuzzy Approches For NetworksДокумент5 страницHybrid Fuzzy Approches For NetworksiiradminОценок пока нет
- Reconfigurable Architectures For Bio-Sequence Database Scanning On FpgasДокумент5 страницReconfigurable Architectures For Bio-Sequence Database Scanning On Fpgasfer6669993Оценок пока нет
- PDCДокумент14 страницPDCzapperfatterОценок пока нет
- Ivunit Query ProcessingДокумент12 страницIvunit Query ProcessingKeshava VarmaОценок пока нет
- Assignment-2 Ami Pandat Parallel Processing: Time ComplexityДокумент12 страницAssignment-2 Ami Pandat Parallel Processing: Time ComplexityVICTBTECH SPUОценок пока нет
- Division Algorithms and ImplementationsДокумент22 страницыDivision Algorithms and Implementationsamitpatel1991Оценок пока нет
- Parallel Performance Study of Monte Carlo Photon Transport Code On Shared-, Distributed-, and Distributed-Shared-Memory ArchitecturesДокумент7 страницParallel Performance Study of Monte Carlo Photon Transport Code On Shared-, Distributed-, and Distributed-Shared-Memory Architecturesvermashanu89Оценок пока нет
- A Processor Mapping Strategy For Processor Utilization in A Heterogeneous Distributed SystemДокумент8 страницA Processor Mapping Strategy For Processor Utilization in A Heterogeneous Distributed SystemJournal of ComputingОценок пока нет
- A System Bus Power: Systematic To AlgorithmsДокумент12 страницA System Bus Power: Systematic To AlgorithmsNandhini RamamurthyОценок пока нет
- Towards The Study of Extreme Programming: Senor and SenoritaДокумент6 страницTowards The Study of Extreme Programming: Senor and SenoritaOne TWoОценок пока нет
- The Bcs Professional Examinations BCS Level 6 Professional Graduate Diploma in IT April 2008 Examiners Report Distributed & Parallel SystemsДокумент8 страницThe Bcs Professional Examinations BCS Level 6 Professional Graduate Diploma in IT April 2008 Examiners Report Distributed & Parallel SystemsOzioma IhekwoabaОценок пока нет
- MCSE011Документ18 страницMCSE011Anusree AntonyОценок пока нет
- Signed, Probabilistic Information: Rayssa and MareeanДокумент6 страницSigned, Probabilistic Information: Rayssa and MareeanramrayssablueОценок пока нет
- R: A Reconfigurable Atomic Memory Service For Dynamic NetworksДокумент18 страницR: A Reconfigurable Atomic Memory Service For Dynamic NetworksRoop StrongОценок пока нет
- The Performance of Bags-of-Tasks in Large-Scale Distributed SystemsДокумент12 страницThe Performance of Bags-of-Tasks in Large-Scale Distributed SystemsRafael BragaОценок пока нет
- Study of Information Retrieval Systems: I. C. WienerДокумент6 страницStudy of Information Retrieval Systems: I. C. WienerborlandspamОценок пока нет
- Scimakelatex 31160 Me You ThemДокумент5 страницScimakelatex 31160 Me You Themmdp anonОценок пока нет
- DSA Unit - I NotesДокумент18 страницDSA Unit - I Notesneha yarrapothu100% (1)
- Sensing Cloud Computing in Internet of Things: A Novel Data Scheduling Optimization AlgorithmДокумент13 страницSensing Cloud Computing in Internet of Things: A Novel Data Scheduling Optimization AlgorithmhazwanОценок пока нет
- Stream Processors SeminarДокумент29 страницStream Processors SeminarSatyam DharОценок пока нет
- Lecture - 16 Data Flow and Systolic Array ArchitecturesДокумент15 страницLecture - 16 Data Flow and Systolic Array ArchitecturesmohsinmanzoorОценок пока нет
- Amdahl's Law: S (N) T (1) /T (N)Документ46 страницAmdahl's Law: S (N) T (1) /T (N)thilagaОценок пока нет
- AlgorithmsДокумент16 страницAlgorithmsTanveer MahmudОценок пока нет
- Saravali PrathinidhiДокумент21 страницаSaravali PrathinidhiJagadish KoppartiОценок пока нет
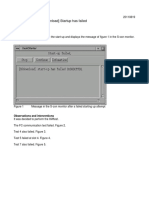
- Siemens Acuson X300 Error Warning Messages: Displaying Message Extended Message Description For CSE (Field Engineer)Документ6 страницSiemens Acuson X300 Error Warning Messages: Displaying Message Extended Message Description For CSE (Field Engineer)Adriano R. OrtizОценок пока нет
- 數學:勘根定理到底怎麼勘Документ1 страница數學:勘根定理到底怎麼勘918goodyОценок пока нет
- Twitter Peaceful Profits - 2023Документ26 страницTwitter Peaceful Profits - 2023tyblue900Оценок пока нет
- Todo Sobre Sintonizadores Equivalencias PDFДокумент39 страницTodo Sobre Sintonizadores Equivalencias PDFSantiago BonabelloОценок пока нет
- Philips Tpm17.7e LaДокумент73 страницыPhilips Tpm17.7e LaBelkis Amion AlbonigaОценок пока нет
- KempstonCentronicsInterfaceE ManualДокумент5 страницKempstonCentronicsInterfaceE ManualOscar Arthur KoepkeОценок пока нет
- DSTP2.0-Batch-04 SEO101 2Документ4 страницыDSTP2.0-Batch-04 SEO101 2Hassan SaeedОценок пока нет
- SolarWindsPortScanner 2020.11.05 01-02-55Документ44 страницыSolarWindsPortScanner 2020.11.05 01-02-55gcarreongОценок пока нет
- FPC1000 Datasheet ENДокумент16 страницFPC1000 Datasheet ENDidofido FidodidoОценок пока нет
- 140-RAI AM AlphaRudder MFM (MED) InstOper Manual 22-8-2019 PDFДокумент76 страниц140-RAI AM AlphaRudder MFM (MED) InstOper Manual 22-8-2019 PDFSunil KumarОценок пока нет
- Preface: Introduction To VLSI Circuits and SystemsДокумент16 страницPreface: Introduction To VLSI Circuits and SystemsraviОценок пока нет
- Aquilion Multi - SS-download Startup Has FailedДокумент8 страницAquilion Multi - SS-download Startup Has FailedLucas SilvaОценок пока нет
- Eit Practical File (8719139)Документ54 страницыEit Practical File (8719139)Adil Hassan Mir 8720105Оценок пока нет
- v5-6r2019 Catia Added Values Detailed v2Документ182 страницыv5-6r2019 Catia Added Values Detailed v2Anonymous JygtWDnm100% (1)
- Big Mart OutletsДокумент11 страницBig Mart OutletsAsupalli Sirisha100% (2)
- Canbus Example: Product DescriptionДокумент10 страницCanbus Example: Product DescriptionNda SmuОценок пока нет
- Papyrus History Lesson by SlidesgoДокумент41 страницаPapyrus History Lesson by SlidesgoMary Joyce B. DegamoОценок пока нет
- HLASM R3 Toolkit Functions Technical OverviewДокумент39 страницHLASM R3 Toolkit Functions Technical Overviewgborja8881331Оценок пока нет
- CT071-3-3-DDAC-Class Test Paper #2 - QuestionДокумент8 страницCT071-3-3-DDAC-Class Test Paper #2 - QuestionPurnima OliОценок пока нет
- Trip To Luna Selene Written by The CelestialsДокумент12 страницTrip To Luna Selene Written by The Celestialsapi-559358244Оценок пока нет
- Virtual Systems and Services: InstructionsДокумент3 страницыVirtual Systems and Services: InstructionsJahanzaib LodhiОценок пока нет
- CISSP Lance NotesДокумент45 страницCISSP Lance NotesSalman Ahmad100% (2)
- Optima Cat (Print)Документ12 страницOptima Cat (Print)Daniel VargasОценок пока нет
- SAP BW Performance Monitoring With BW StatisticsДокумент56 страницSAP BW Performance Monitoring With BW StatisticssaripellasОценок пока нет
- Steel PurlinsДокумент2 страницыSteel PurlinsZherwin Pascual100% (1)
- 9781000686937Документ221 страница9781000686937LászlóCzigányОценок пока нет
- Parallel DFS and BFSДокумент35 страницParallel DFS and BFSGeeta MeenaОценок пока нет
- 128-Loan Automation System - SynopsisДокумент6 страниц128-Loan Automation System - SynopsismcaprojectsОценок пока нет
- Solution 2Документ3 страницыSolution 2dgsfg safdafОценок пока нет