Вам также может понравиться
- Greenacre Preface 2010Документ8 страницGreenacre Preface 2010Ángel Quintero SánchezОценок пока нет
- (Cambridge Library Collection - History of Printing, Publishing and Libraries) John Southward-Dictionary of Typography and Its Accessory Arts-Cambridge University Press (2010)Документ196 страниц(Cambridge Library Collection - History of Printing, Publishing and Libraries) John Southward-Dictionary of Typography and Its Accessory Arts-Cambridge University Press (2010)Ángel Quintero SánchezОценок пока нет
- FBBVA - Book - La Práctica Del Análisis de CorrespondenciasДокумент2 страницыFBBVA - Book - La Práctica Del Análisis de CorrespondenciasÁngel Quintero SánchezОценок пока нет
- Handbook - Attitudes and Attitude ChangeДокумент29 страницHandbook - Attitudes and Attitude ChangeBeatrice DumitruОценок пока нет
- Greenacre c08 Ok 2010Документ12 страницGreenacre c08 Ok 2010Ángel Quintero SánchezОценок пока нет
- Greenacre C13ok 2010Документ12 страницGreenacre C13ok 2010Ángel Quintero SánchezОценок пока нет
- Greenacre C09ok 2010 PDFДокумент11 страницGreenacre C09ok 2010 PDFÁngel Quintero SánchezОценок пока нет
- Greenacre c11 2010Документ11 страницGreenacre c11 2010Ángel Quintero SánchezОценок пока нет
- Greenacre c12 2010Документ11 страницGreenacre c12 2010Ángel Quintero SánchezОценок пока нет
- Chapter SixДокумент12 страницChapter SixÁngel Quintero SánchezОценок пока нет
- Biplots in Practice: The Relationship Between Fish Morphology and DietДокумент16 страницBiplots in Practice: The Relationship Between Fish Morphology and DietÁngel Quintero SánchezОценок пока нет
- Greenacre C14ok 2010Документ15 страницGreenacre C14ok 2010Ángel Quintero SánchezОценок пока нет
- Greenacre Contents 2010Документ1 страницаGreenacre Contents 2010Ángel Quintero SánchezОценок пока нет
- DispersiónДокумент10 страницDispersiónÁngel Quintero SánchezОценок пока нет
- Chapter SixДокумент12 страницChapter SixÁngel Quintero SánchezОценок пока нет
- Greenacre Preface 2010Документ8 страницGreenacre Preface 2010Ángel Quintero SánchezОценок пока нет
- BOSS3 Participant HandbookДокумент21 страницаBOSS3 Participant HandbookÁngel Quintero SánchezОценок пока нет
- Chapter SixДокумент12 страницChapter SixÁngel Quintero SánchezОценок пока нет
- Análisis de ComponentesДокумент12 страницAnálisis de ComponentesÁngel Quintero SánchezОценок пока нет
- Biplots in PracticeДокумент10 страницBiplots in PracticeÁngel Quintero SánchezОценок пока нет
- DispersiónДокумент10 страницDispersiónÁngel Quintero SánchezОценок пока нет
- Market Research Studies Questionnaire NO ANSWERSДокумент3 страницыMarket Research Studies Questionnaire NO ANSWERSÁngel Quintero Sánchez100% (1)
- Biplots 1Документ33 страницыBiplots 1Ángel Quintero SánchezОценок пока нет
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Functional Requirements and Concepts of Frequency Converter's Oil Application Control ProgramДокумент78 страницFunctional Requirements and Concepts of Frequency Converter's Oil Application Control ProgramRigoberto José Martínez CedeñoОценок пока нет
- Green Solvents PresДокумент74 страницыGreen Solvents PresTDSОценок пока нет
- Four Decades of Research On Thermal Contact, Gap, and Joint Resistance in MicroelectronicsДокумент25 страницFour Decades of Research On Thermal Contact, Gap, and Joint Resistance in MicroelectronicsDaniel MendesОценок пока нет
- V 082 N 04 P 112Документ6 страницV 082 N 04 P 112Romi FadliОценок пока нет
- Hiad 2Документ15 страницHiad 2Hrishikesh JoshiОценок пока нет
- Mody Institute of Technology and Science, Lakshmangarh Faculty of Engineering and TechnologyДокумент3 страницыMody Institute of Technology and Science, Lakshmangarh Faculty of Engineering and TechnologyAtul GaurОценок пока нет
- Internal Resistance and Combinations of CellsДокумент10 страницInternal Resistance and Combinations of CellsSukoon Sarin67% (3)
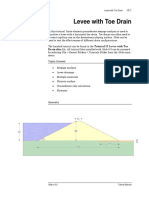
- Levee Drain Analysis in SlideДокумент12 страницLevee Drain Analysis in SlideAdriRGОценок пока нет
- Modeling of Synchronous Generators in Power System Studies: October 2016Документ12 страницModeling of Synchronous Generators in Power System Studies: October 2016aswardiОценок пока нет
- 12.1 and 12.2 Quiz 1Документ1 страница12.1 and 12.2 Quiz 1DoraemonОценок пока нет
- Temperature Regulator With Two Temperature SensorsДокумент2 страницыTemperature Regulator With Two Temperature SensorsSandi AslanОценок пока нет
- MIT OCW Principles of Inorganic Chemistry II Lecture on Octahedral ML6 Sigma ComplexesДокумент7 страницMIT OCW Principles of Inorganic Chemistry II Lecture on Octahedral ML6 Sigma Complexessanskarid94Оценок пока нет
- Direct Determination of The Flow Curves of NoДокумент4 страницыDirect Determination of The Flow Curves of NoZaid HadiОценок пока нет
- 1 4 Bookmark A Crash Course in Forces MotionДокумент2 страницы1 4 Bookmark A Crash Course in Forces Motionapi-115513756Оценок пока нет
- Mapua Institute of Technology: Field Work 1 Pacing On Level GroundДокумент7 страницMapua Institute of Technology: Field Work 1 Pacing On Level GroundIan Ag-aDoctorОценок пока нет
- Physics: Pearson EdexcelДокумент16 страницPhysics: Pearson EdexcelRichard Davidson12100% (1)
- Inline Desilter ManualДокумент18 страницInline Desilter ManualdesaviniciusОценок пока нет
- Analytical Chemistry & Numerical MCQ Test 3 - Makox MCQsДокумент5 страницAnalytical Chemistry & Numerical MCQ Test 3 - Makox MCQsنونه الحنونةОценок пока нет
- Physics Grade 11 Gas Laws and WavesДокумент6 страницPhysics Grade 11 Gas Laws and WavesNatalia WhyteОценок пока нет
- MechanicsДокумент558 страницMechanicsfejiloОценок пока нет
- Human at Mars PDFДокумент55 страницHuman at Mars PDFVuningoma BoscoОценок пока нет
- Sherman Notes PDFДокумент213 страницSherman Notes PDFAbdul Hamid Bhatti100% (1)
- NCHRP RPT 242 PDFДокумент85 страницNCHRP RPT 242 PDFDavid Drolet TremblayОценок пока нет
- 79 PDFДокумент4 страницы79 PDFHolayilОценок пока нет
- Radiation Heat Transfer in Combustion Systems - Viskanta and Menguc PDFДокумент64 страницыRadiation Heat Transfer in Combustion Systems - Viskanta and Menguc PDFXamir Suarez Alejandro100% (1)
- PID - From Theory To ImplementationДокумент5 страницPID - From Theory To Implementationvictor-cabral3433Оценок пока нет
- 1 Electricity Test QuestionsДокумент5 страниц1 Electricity Test QuestionstinoОценок пока нет
- 16.100 Take-Home Exam SolutionsДокумент3 страницы16.100 Take-Home Exam SolutionslarasmoyoОценок пока нет
- Make a castable lab test mixДокумент16 страницMake a castable lab test mixthaituan237Оценок пока нет
- Engineering With Nuclear Explosives (Vol. 1.) Symposium, 1970Документ868 страницEngineering With Nuclear Explosives (Vol. 1.) Symposium, 1970MisterSpacerockОценок пока нет