Вам также может понравиться
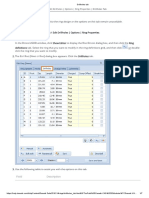
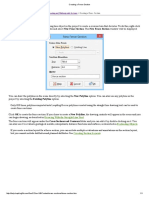
- Drillholes TabДокумент7 страницDrillholes TabkataukongОценок пока нет
- GnssДокумент1 страницаGnsskataukongОценок пока нет
- Windows 10 Activation Keys For All VersionsДокумент4 страницыWindows 10 Activation Keys For All Versionskataukong75% (4)
- Geosoft - Exploring With Data - Target5Документ6 страницGeosoft - Exploring With Data - Target5kataukongОценок пока нет
- Geosoft - Exploring With Data - TargetДокумент7 страницGeosoft - Exploring With Data - TargetkataukongОценок пока нет
- Creating Section LayoutsДокумент2 страницыCreating Section LayoutskataukongОценок пока нет
- Oasis Montaj 90Документ9 страницOasis Montaj 90kataukongОценок пока нет
- Geosoft - Exploring With Data - TipsДокумент5 страницGeosoft - Exploring With Data - TipskataukongОценок пока нет
- List of Hidden Secret Service Codes For Chinese Mobile Phones - AskVGДокумент4 страницыList of Hidden Secret Service Codes For Chinese Mobile Phones - AskVGkataukongОценок пока нет
- Geosoft Release 92Документ4 страницыGeosoft Release 92kataukongОценок пока нет
- Geosoft Release 9Документ4 страницыGeosoft Release 9kataukongОценок пока нет
- Geosoft - Exploring With Data - Target4Документ7 страницGeosoft - Exploring With Data - Target4kataukongОценок пока нет
- Updating COGO Attributes-Help - ArcGIS For DesktopДокумент1 страницаUpdating COGO Attributes-Help - ArcGIS For DesktopkataukongОценок пока нет
- 6S - How To Flash From DFU Mode. Password RecoveryДокумент21 страница6S - How To Flash From DFU Mode. Password RecoverykataukongОценок пока нет
- Geosoft - Exploring With Data - Target3Документ7 страницGeosoft - Exploring With Data - Target3kataukongОценок пока нет
- Mozart Symphony 40Документ2 страницыMozart Symphony 40kataukongОценок пока нет
- Geosoft - Exploring With Data - Creating Geological Surfaces From A Lithology VoxelДокумент3 страницыGeosoft - Exploring With Data - Creating Geological Surfaces From A Lithology VoxelkataukongОценок пока нет
- Geomatica TrialДокумент1 страницаGeomatica TrialkataukongОценок пока нет
- Creating A Fence SectionДокумент1 страницаCreating A Fence SectionkataukongОценок пока нет
- Ortho PhotographyДокумент4 страницыOrtho PhotographykataukongОценок пока нет
- Creating A Fence SectionДокумент1 страницаCreating A Fence SectionkataukongОценок пока нет
- Bu Mat Moi 3 PDFДокумент80 страницBu Mat Moi 3 PDFkataukongОценок пока нет
- Reporting COGO Descriptions-Help - ArcGIS For DesktopДокумент2 страницыReporting COGO Descriptions-Help - ArcGIS For DesktopkataukongОценок пока нет
- Calculating COGO Area-Help - ArcGIS For DesktopДокумент1 страницаCalculating COGO Area-Help - ArcGIS For DesktopkataukongОценок пока нет
- Splitting Features Into COGO Lines-Help - ArcGIS For DesktopДокумент1 страницаSplitting Features Into COGO Lines-Help - ArcGIS For DesktopkataukongОценок пока нет
- Windows 10 MTK VCOM USB Drivers For 32 & - Elephone M2Документ14 страницWindows 10 MTK VCOM USB Drivers For 32 & - Elephone M2kataukong100% (1)
- An Overview of COGO-Help - ArcGIS For DesktopДокумент3 страницыAn Overview of COGO-Help - ArcGIS For DesktopkataukongОценок пока нет
- Samsung Protection AvforumsДокумент5 страницSamsung Protection AvforumskataukongОценок пока нет
- Haydn Emperor HymnsДокумент1 страницаHaydn Emperor HymnskataukongОценок пока нет
- Entry Engineer Tampa FLДокумент2 страницыEntry Engineer Tampa FLkataukongОценок пока нет
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5784)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (890)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (399)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (119)
- Recovery Manager ToshibaДокумент8 страницRecovery Manager ToshibaMaryam100% (1)
- EzCAD3 User ManualДокумент58 страницEzCAD3 User ManualDurraniОценок пока нет
- Microsoft Source ServerДокумент19 страницMicrosoft Source ServeribmmasterОценок пока нет
- Grade 10 3rd Quarter Questioner IctДокумент5 страницGrade 10 3rd Quarter Questioner IctRoselyn MyerОценок пока нет
- Navigating The EDPMS Offline SystemДокумент6 страницNavigating The EDPMS Offline SystemAngelito BALUYOT JRОценок пока нет
- 05 2009Документ84 страницы05 2009Jose Luis Diaz OrtegaОценок пока нет
- Diploma Operating System Chapter 1Документ68 страницDiploma Operating System Chapter 1Alvin ChinОценок пока нет
- TOAD DBA Module GuideДокумент83 страницыTOAD DBA Module Guidesmruti_2012Оценок пока нет
- W32 Downadup Worm AnalysisДокумент12 страницW32 Downadup Worm AnalysisRainer1979Оценок пока нет
- DSE892 Update InstructionsДокумент1 страницаDSE892 Update InstructionsJosue ValdesОценок пока нет
- Bit Bake BasicsДокумент23 страницыBit Bake BasicsSabin LovinОценок пока нет
- Facial Recognition Search On The Police National DatabaseДокумент11 страницFacial Recognition Search On The Police National DatabaseMatthew BurgessОценок пока нет
- Software Requirements Specification (SRS)Документ8 страницSoftware Requirements Specification (SRS)karimahnajiyahОценок пока нет
- Routers - Catalyst 8000 - ArtДокумент13 страницRouters - Catalyst 8000 - ArtAdithyo DewanggaОценок пока нет
- 18CSE364T - System Administration and MaintenanceДокумент5 страниц18CSE364T - System Administration and MaintenanceK MAHESHWARI (RA1811031010041)Оценок пока нет
- Offline Speech Recognition made easy with VOSKДокумент3 страницыOffline Speech Recognition made easy with VOSKSyeda AishaОценок пока нет
- PG3Документ577 страницPG3mattОценок пока нет
- XCSoar ManualДокумент187 страницXCSoar ManualluispilotoОценок пока нет
- YS - UDisk - AP User ManualДокумент17 страницYS - UDisk - AP User Manualpettpett2Оценок пока нет
- About Kingsoft OfficeДокумент1 страницаAbout Kingsoft OfficeCy ArsenalОценок пока нет
- QLAY2 DocumentationДокумент10 страницQLAY2 Documentationjose perezОценок пока нет
- Install and Configure FXCipher EAДокумент2 страницыInstall and Configure FXCipher EAAlexandre VassolerОценок пока нет
- 3.4 Navigate The Operating System TESTДокумент3 страницы3.4 Navigate The Operating System TESTEver MontoyaОценок пока нет
- Case Study Nuix EDRM Enron Data SetДокумент5 страницCase Study Nuix EDRM Enron Data SetNuix DataОценок пока нет
- Follett White Paper SQL System BackupsДокумент7 страницFollett White Paper SQL System Backupsapi-280364067Оценок пока нет
- Convert ARC ASCII Text File To XyzДокумент5 страницConvert ARC ASCII Text File To XyzSlenko VallasОценок пока нет
- DNG 7.2 Converter ReadMeДокумент14 страницDNG 7.2 Converter ReadMemizor_99Оценок пока нет
- Database Commitment Control: Ibm I 7.2Документ120 страницDatabase Commitment Control: Ibm I 7.2Veres PéterОценок пока нет
- Generate 100+ Strategies with One ClickДокумент12 страницGenerate 100+ Strategies with One ClickJeadsada KongboonmaОценок пока нет
- MS DOS Ebook For BeginnerДокумент19 страницMS DOS Ebook For Beginnerramaisgod86% (7)