Вам также может понравиться
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryОт EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryРейтинг: 3.5 из 5 звезд3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)От EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Рейтинг: 4.5 из 5 звезд4.5/5 (121)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaОт EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaРейтинг: 4.5 из 5 звезд4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingОт EverandThe Little Book of Hygge: Danish Secrets to Happy LivingРейтинг: 3.5 из 5 звезд3.5/5 (400)
- Never Split the Difference: Negotiating As If Your Life Depended On ItОт EverandNever Split the Difference: Negotiating As If Your Life Depended On ItРейтинг: 4.5 из 5 звезд4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerОт EverandThe Emperor of All Maladies: A Biography of CancerРейтинг: 4.5 из 5 звезд4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeОт EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeРейтинг: 4 из 5 звезд4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyОт EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyРейтинг: 3.5 из 5 звезд3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersОт EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersРейтинг: 4.5 из 5 звезд4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnОт EverandTeam of Rivals: The Political Genius of Abraham LincolnРейтинг: 4.5 из 5 звезд4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreОт EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreРейтинг: 4 из 5 звезд4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceОт EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceРейтинг: 4 из 5 звезд4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureОт EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureРейтинг: 4.5 из 5 звезд4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaОт EverandThe Unwinding: An Inner History of the New AmericaРейтинг: 4 из 5 звезд4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)От EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Рейтинг: 4 из 5 звезд4/5 (98)
- PoetryДокумент36 страницPoetryAbhay Vohra100% (22)
- Unit 1 - ARM7Документ67 страницUnit 1 - ARM7Makrand KakatkarОценок пока нет
- SkyFence Brochure 2018121cДокумент12 страницSkyFence Brochure 2018121cAnkitОценок пока нет
- CT-VT Testing PDFДокумент9 страницCT-VT Testing PDFusmanОценок пока нет
- Kathrein 2017 Directional Antennas VPol 690-2690 MHZДокумент8 страницKathrein 2017 Directional Antennas VPol 690-2690 MHZRobertОценок пока нет
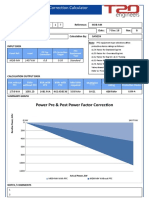
- Power Factor CalculationДокумент2 страницыPower Factor CalculationSandeep DeodharОценок пока нет
- Entrepreneurial Theory For StudentsДокумент9 страницEntrepreneurial Theory For StudentsMultazeem MominОценок пока нет
- Reconfiguration Architectures: by Nagasai.B 108113022Документ14 страницReconfiguration Architectures: by Nagasai.B 108113022aarthi100Оценок пока нет
- What Is MetastabilityДокумент5 страницWhat Is Metastabilityaarthi100Оценок пока нет
- Universal GatesДокумент2 страницыUniversal Gatesaarthi100Оценок пока нет
- Electrical Engineering: Signals and SystemsДокумент10 страницElectrical Engineering: Signals and Systemsaarthi100Оценок пока нет
- ComparchДокумент3 страницыComparchaarthi100Оценок пока нет
- VLIW PhilipsДокумент11 страницVLIW Philipsarchan1989Оценок пока нет
- LedДокумент3 страницыLedaarthi100Оценок пока нет
- 1 Cauchy Sequences: N N J N MДокумент3 страницы1 Cauchy Sequences: N N J N Maarthi100Оценок пока нет
- Barrel ShifterДокумент2 страницыBarrel Shifteraarthi100Оценок пока нет
- Micro StripДокумент22 страницыMicro Stripaarthi100Оценок пока нет
- DiodeДокумент5 страницDiodeaarthi100Оценок пока нет
- ExperimentДокумент23 страницыExperimentZubair BangiОценок пока нет
- JS Events Methods ObjectsДокумент25 страницJS Events Methods Objectsaarthi100Оценок пока нет
- Taylor SeriesДокумент7 страницTaylor SeriesnottherОценок пока нет
- PSRДокумент1 страницаPSRaarthi100Оценок пока нет
- TaskerДокумент1 страницаTaskeraarthi100Оценок пока нет
- Synchronous Asynchronous ModeДокумент7 страницSynchronous Asynchronous Modeaarthi100Оценок пока нет
- BrainДокумент1 страницаBrainaarthi100Оценок пока нет
- Html5 AudioДокумент15 страницHtml5 Audioaarthi100Оценок пока нет
- LimitsДокумент2 страницыLimitsaarthi100Оценок пока нет
- Prayer of The WoodsДокумент1 страницаPrayer of The Woodsaarthi100Оценок пока нет
- QuestionnaireДокумент5 страницQuestionnaireaarthi100Оценок пока нет
- CorrosionДокумент13 страницCorrosionaarthi100Оценок пока нет
- CorrosionДокумент23 страницыCorrosionaarthi100Оценок пока нет
- PaintsДокумент14 страницPaintsaarthi100Оценок пока нет
- Nemo Invex II - BrochureДокумент2 страницыNemo Invex II - BrochureEduardo Ugalde DíazОценок пока нет
- Diode Circuits and Special Purpose Diodes CpEДокумент29 страницDiode Circuits and Special Purpose Diodes CpEvj hernandezОценок пока нет
- Class - 12 - Physics - Alternating Current - PPT-2 of 3Документ22 страницыClass - 12 - Physics - Alternating Current - PPT-2 of 3Benedet TaferyОценок пока нет
- SO CF, Internal Fault Map Class 1A SO CF, Internal Fault Map Class 2A SO CF, External Condition Map Class 1BДокумент15 страницSO CF, Internal Fault Map Class 1A SO CF, Internal Fault Map Class 2A SO CF, External Condition Map Class 1BATMMOBILISОценок пока нет
- Me6702 Mechatronics Unit 4Документ23 страницыMe6702 Mechatronics Unit 4Niyas AhamedОценок пока нет
- 9 D9.35PДокумент2 страницы9 D9.35Pmanpreetsingh3458417Оценок пока нет
- Implementation of Information Technology in RedFox Internet CafeДокумент13 страницImplementation of Information Technology in RedFox Internet CafeMuhamad Adji YahyaОценок пока нет
- Owner's ManualДокумент56 страницOwner's ManualFouquetОценок пока нет
- ADPlaylistEditor3 (Network Version)Документ42 страницыADPlaylistEditor3 (Network Version)Dramane BonkoungouОценок пока нет
- Dell Latitude 5289Документ50 страницDell Latitude 5289AkalankaОценок пока нет
- TDA7297SA DatasheetДокумент11 страницTDA7297SA DatasheetLeoОценок пока нет
- FCM1811-A1/FCM1811-B1 CPU Board Product Manual: Fire Safety and Security ProductsДокумент2 страницыFCM1811-A1/FCM1811-B1 CPU Board Product Manual: Fire Safety and Security ProductsTun Wai WinОценок пока нет
- Repair Station Capability L Station Id Ld7r612j RCD CHG Added Rockwell Collins CockpitДокумент20 страницRepair Station Capability L Station Id Ld7r612j RCD CHG Added Rockwell Collins CockpitAdel KhelifiОценок пока нет
- Bias Probe InstructionsДокумент2 страницыBias Probe InstructionsGoran ColMax Pickups ColicОценок пока нет
- Chapter 3 BJT Devices PDFДокумент22 страницыChapter 3 BJT Devices PDFDaNieL RuPErTOОценок пока нет
- PricingДокумент8 страницPricingBherllyne JumillaОценок пока нет
- MJ 11032 G Hyundai BlowerДокумент4 страницыMJ 11032 G Hyundai BlowerDragan LugonićОценок пока нет
- GD - 40 - Manual Service Control BoxДокумент2 страницыGD - 40 - Manual Service Control BoxDiztian REquez AriezОценок пока нет
- 1.Ch12 OfficialДокумент20 страниц1.Ch12 Officialx1Оценок пока нет
- TN Electronics Hardware Manufacturing PolicyДокумент28 страницTN Electronics Hardware Manufacturing PolicyArunVenkatachalamОценок пока нет
- Datasheet 16F1938 PDFДокумент488 страницDatasheet 16F1938 PDFAnonymous ZMx8heОценок пока нет
- MOSFETWIKДокумент23 страницыMOSFETWIKCrayolo HernandezОценок пока нет
- Lecture 1 (INTRO)Документ27 страницLecture 1 (INTRO)nehar shubheschaОценок пока нет
- Embedded SystemДокумент78 страницEmbedded SystemIshita BahalОценок пока нет
- 1HSB543200 EdbДокумент9 страниц1HSB543200 EdbRenzo Gutilla100% (1)