Вам также может понравиться
- The Essence of Success - Earl NightingaleДокумент2 страницыThe Essence of Success - Earl NightingaleDegrace Ns40% (15)
- Test Plan DocumentДокумент7 страницTest Plan DocumentNyambura Kinyua100% (1)
- Restaurant Management System Case StudyДокумент11 страницRestaurant Management System Case StudyArpit ShrivastavaОценок пока нет
- Quality Risk ManagementДокумент29 страницQuality Risk ManagementmmmmmОценок пока нет
- Improving Bug Triage Based On Predictive ModelДокумент5 страницImproving Bug Triage Based On Predictive ModelIJSTEОценок пока нет
- SakshigabahneДокумент3 страницыSakshigabahneInternational Journal of Scholarly ResearchОценок пока нет
- Chapter 3Документ11 страницChapter 3Paolo RenОценок пока нет
- Using Data Reduction Techniques For Effective Bug Triage: Shanthipriya. D, Deepa.KДокумент4 страницыUsing Data Reduction Techniques For Effective Bug Triage: Shanthipriya. D, Deepa.KKumarecitОценок пока нет
- A Review of Software Fault Detection and Correction Process, Models and TechniquesДокумент8 страницA Review of Software Fault Detection and Correction Process, Models and TechniquesDr Muhamma Imran BabarОценок пока нет
- First Review Part-A Identification and Statement of The ProblemДокумент5 страницFirst Review Part-A Identification and Statement of The ProblemMohamed SaleemОценок пока нет
- Theis ProposalДокумент6 страницTheis ProposaliramОценок пока нет
- Jay Prakash, DBMSДокумент10 страницJay Prakash, DBMSAnirudh Adithya B SОценок пока нет
- Improving Bug Tracking Systems: Many Thanks To Sascha Just For Creating The Template For Figure 1Документ4 страницыImproving Bug Tracking Systems: Many Thanks To Sascha Just For Creating The Template For Figure 1Harivaram GayathriОценок пока нет
- Ijettcs 2013 10 25 078Документ5 страницIjettcs 2013 10 25 078International Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- 000 COUPLING METRICS Software MetricsДокумент38 страниц000 COUPLING METRICS Software MetricsfxgbizdcsОценок пока нет
- TR 200904text24Документ12 страницTR 200904text24SpeedSrlОценок пока нет
- Chapter 1Документ52 страницыChapter 1Kajal SinghalОценок пока нет
- 14 AprДокумент9 страниц14 AprSiva GaneshОценок пока нет
- Mid Term Industrial Training Report: Bug TrackerДокумент13 страницMid Term Industrial Training Report: Bug TrackerDante NeroОценок пока нет
- DEDAN KIMATHI UNIVERSITY OF TECHNOLOGY DIPLOMA IN INFORMATION TECHNOLOGY ASSIGNMENTДокумент9 страницDEDAN KIMATHI UNIVERSITY OF TECHNOLOGY DIPLOMA IN INFORMATION TECHNOLOGY ASSIGNMENTWambuiОценок пока нет
- Developer Centered Bug Prediction ModelДокумент4 страницыDeveloper Centered Bug Prediction ModelssigoldОценок пока нет
- WelcomeДокумент23 страницыWelcomeabiramanОценок пока нет
- TestingДокумент2 страницыTestingMaha JuneОценок пока нет
- Bug Tracking SystemДокумент28 страницBug Tracking SystemKaataRanjithkumarОценок пока нет
- To Prepare Software Requirements Specification Document For Employee Management ApplicationДокумент9 страницTo Prepare Software Requirements Specification Document For Employee Management ApplicationUTKARSH ARYAОценок пока нет
- Bug Tracking SystemДокумент5 страницBug Tracking SystemMohamed WaelОценок пока нет
- Bug Fixing Process Analysis Using Program Slicing TechniquesДокумент8 страницBug Fixing Process Analysis Using Program Slicing TechniquesSailuОценок пока нет
- Bug Management: ISYS6264 - Testing and System ImplementationДокумент52 страницыBug Management: ISYS6264 - Testing and System ImplementationMuhammadAfrizaОценок пока нет
- Software Testing Methodology Unit-3Документ8 страницSoftware Testing Methodology Unit-3Md RehanОценок пока нет
- Automatic Labeling of Github IssuesДокумент9 страницAutomatic Labeling of Github IssuesArun KalyanasundaramОценок пока нет
- Software Testing: Question Bank With Answers Vistas PallavaramДокумент68 страницSoftware Testing: Question Bank With Answers Vistas PallavaramVIMALОценок пока нет
- Prepare for database testingДокумент5 страницPrepare for database testingmengistuОценок пока нет
- Software Engineering - Debugging: Radare2 Windbg Valgrind TestingДокумент3 страницыSoftware Engineering - Debugging: Radare2 Windbg Valgrind TestingMisbah SajidОценок пока нет
- Automatic Calculation of Process Metrics for Bug PredictionДокумент23 страницыAutomatic Calculation of Process Metrics for Bug PredictionFortHellОценок пока нет
- SOFTWARE ENGINEERING-compressedДокумент21 страницаSOFTWARE ENGINEERING-compressedvt1001975Оценок пока нет
- Application of Deep Learning in Software Testing and Quality AssuranceДокумент13 страницApplication of Deep Learning in Software Testing and Quality AssuranceLeah RachaelОценок пока нет
- Tools and Techniques Used For Prioritizing Test Cases in Regression TestingДокумент4 страницыTools and Techniques Used For Prioritizing Test Cases in Regression TestingEditor IJRITCCОценок пока нет
- Bug Tracking SystemДокумент3 страницыBug Tracking Systemswathi-rОценок пока нет
- 1.1 Development of Employee Performance Management - An OverviewДокумент57 страниц1.1 Development of Employee Performance Management - An OverviewJothi ManiОценок пока нет
- ReportДокумент47 страницReportsahil guptaОценок пока нет
- Paper For ICT4dДокумент6 страницPaper For ICT4dSamuel temesgenОценок пока нет
- Ijcs 2016 0303020 PDFДокумент4 страницыIjcs 2016 0303020 PDFeditorinchiefijcsОценок пока нет
- Bug Tracking System (BTS) : International Research Journal of Engineering and Technology (IRJET)Документ5 страницBug Tracking System (BTS) : International Research Journal of Engineering and Technology (IRJET)ushavalsaОценок пока нет
- Predicting Root Cause Analysis (RCA) Bucket ForДокумент4 страницыPredicting Root Cause Analysis (RCA) Bucket ForTameta DadaОценок пока нет
- Srs YashpДокумент26 страницSrs YashpRathod ManthanОценок пока нет
- (Bug Track) PowerДокумент29 страниц(Bug Track) PowerMohamed WaelОценок пока нет
- E CommerceДокумент13 страницE CommerceSuraj NunnaОценок пока нет
- Bug Tracking and Reporting System: A.S.Syed Fiaz, N.Devi, S.AarthiДокумент4 страницыBug Tracking and Reporting System: A.S.Syed Fiaz, N.Devi, S.AarthiranjanbiharОценок пока нет
- Software ValidationДокумент20 страницSoftware Validationradhye radhyeОценок пока нет
- Ijcs 2016 0303013 PDFДокумент4 страницыIjcs 2016 0303013 PDFeditorinchiefijcsОценок пока нет
- Assignment of 014Документ6 страницAssignment of 014Swati TiwariОценок пока нет
- Software Testing and Quality Assurance for Medical ApplicationsДокумент4 страницыSoftware Testing and Quality Assurance for Medical ApplicationsAnuj SamariyaОценок пока нет
- System Analysis and DesignДокумент13 страницSystem Analysis and DesignSreedeviОценок пока нет
- Exalting Complexity Measures For Software Testing Accompanying Multi AgentsДокумент6 страницExalting Complexity Measures For Software Testing Accompanying Multi AgentsInternational Journal of Application or Innovation in Engineering & ManagementОценок пока нет
- Methods of Software TestingДокумент12 страницMethods of Software TestingSai RaazОценок пока нет
- Assignment 5 (C324.6) : Group C Ques 1. CASE StudyДокумент3 страницыAssignment 5 (C324.6) : Group C Ques 1. CASE StudyShubhamMisraОценок пока нет
- Chp2 Taxonomy SW MaintaineanceДокумент7 страницChp2 Taxonomy SW MaintaineanceTooba AkhterОценок пока нет
- Bug Tracking SystemДокумент8 страницBug Tracking Systemsahil guptaОценок пока нет
- Software TestingДокумент8 страницSoftware TestingNnosie Khumalo Lwandile SaezoОценок пока нет
- STQA Lab 3Документ5 страницSTQA Lab 3Mahede HassanОценок пока нет
- Build and Fix Model (Also Referred To As An Ad Hoc Model), The Software Is Developed Without AnyДокумент5 страницBuild and Fix Model (Also Referred To As An Ad Hoc Model), The Software Is Developed Without AnyvectorОценок пока нет
- Tesco CRM Case StudyДокумент1 страницаTesco CRM Case StudyAnbu VidhyaОценок пока нет
- Profit LossДокумент4 страницыProfit LossAnbu VidhyaОценок пока нет
- Averages: Quantities of - No Quantities All of SumДокумент8 страницAverages: Quantities of - No Quantities All of SumSumeet KumarОценок пока нет
- 3rdpipes and Cisterns New1Документ50 страниц3rdpipes and Cisterns New1Sai Manoj K RОценок пока нет
- Profit LossДокумент4 страницыProfit LossAnbu VidhyaОценок пока нет
- C - Official Coast HandbookДокумент15 страницC - Official Coast HandbookSofia FreundОценок пока нет
- Verifyning GC MethodДокумент3 страницыVerifyning GC MethodHristova HristovaОценок пока нет
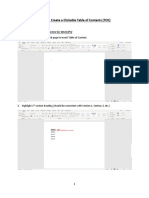
- How To: Create A Clickable Table of Contents (TOC)Документ10 страницHow To: Create A Clickable Table of Contents (TOC)Xuan Mai Nguyen ThiОценок пока нет
- Maths Lit 2014 ExamplarДокумент17 страницMaths Lit 2014 ExamplarAnymore Ndlovu0% (1)
- Iqvia PDFДокумент1 страницаIqvia PDFSaksham DabasОценок пока нет
- Frequency Meter by C Programming of AVR MicrocontrДокумент3 страницыFrequency Meter by C Programming of AVR MicrocontrRajesh DhavaleОценок пока нет
- Sierra Wireless AirPrimeДокумент2 страницыSierra Wireless AirPrimeAminullah -Оценок пока нет
- Resignation Acceptance LetterДокумент1 страницаResignation Acceptance LetterJahnvi KanwarОценок пока нет
- RoboticsДокумент2 страницыRoboticsCharice AlfaroОценок пока нет
- BC Specialty Foods DirectoryДокумент249 страницBC Specialty Foods Directoryjcl_da_costa6894Оценок пока нет
- E200P Operation ManualДокумент26 страницE200P Operation ManualsharmasourabhОценок пока нет
- Superior University: 5Mwp Solar Power Plant ProjectДокумент3 страницыSuperior University: 5Mwp Solar Power Plant ProjectdaniyalОценок пока нет
- DOLE AEP Rule 2017Документ2 страницыDOLE AEP Rule 2017unhoopterenceОценок пока нет
- Vallance - Sistema Do VolvoДокумент15 страницVallance - Sistema Do VolvoNuno PachecoОценок пока нет
- Specialized Government BanksДокумент5 страницSpecialized Government BanksCarazelli AysonОценок пока нет
- Enhancing reliability of CRA piping welds with PAUTДокумент10 страницEnhancing reliability of CRA piping welds with PAUTMohsin IamОценок пока нет
- Lead Magnet 43 Foolproof Strategies To Get More Leads, Win A Ton of New Customers and Double Your Profits in Record Time... (RДокумент189 страницLead Magnet 43 Foolproof Strategies To Get More Leads, Win A Ton of New Customers and Double Your Profits in Record Time... (RluizdasilvaazevedoОценок пока нет
- Company's Profile Presentation (Mauritius Commercial Bank)Документ23 страницыCompany's Profile Presentation (Mauritius Commercial Bank)ashairways100% (2)
- Discount & Percentage Word Problems SolutionsДокумент4 страницыDiscount & Percentage Word Problems SolutionsrheОценок пока нет
- BCM Risk Management and Compliance Training in JakartaДокумент2 страницыBCM Risk Management and Compliance Training in Jakartaindra gОценок пока нет
- Broadband BillДокумент1 страницаBroadband BillKushi GowdaОценок пока нет
- BUSN7054 Take Home Final Exam S1 2020Документ14 страницBUSN7054 Take Home Final Exam S1 2020Li XiangОценок пока нет
- 59 - 1006 - CTP-Final - 20200718 PDFДокумент11 страниц59 - 1006 - CTP-Final - 20200718 PDFshubh.icai0090Оценок пока нет
- Borneo United Sawmills SDN BHD V Mui Continental Insurance Berhad (2006) 1 LNS 372Документ6 страницBorneo United Sawmills SDN BHD V Mui Continental Insurance Berhad (2006) 1 LNS 372Cheng LeongОценок пока нет
- Scenemaster3 ManualДокумент79 страницScenemaster3 ManualSeba Gomez LОценок пока нет
- High Uric CidДокумент3 страницыHigh Uric Cidsarup007Оценок пока нет
- Amos Code SystemДокумент17 страницAmos Code SystemViktor KarlashevychОценок пока нет
- Experienced Leadership Driving Growth at Adlabs EntertainmentДокумент38 страницExperienced Leadership Driving Growth at Adlabs EntertainmentvelusnОценок пока нет